[논문 리뷰] OAMatcher: An Overlapping Areas-based Network for Accurate Local Feature Matching
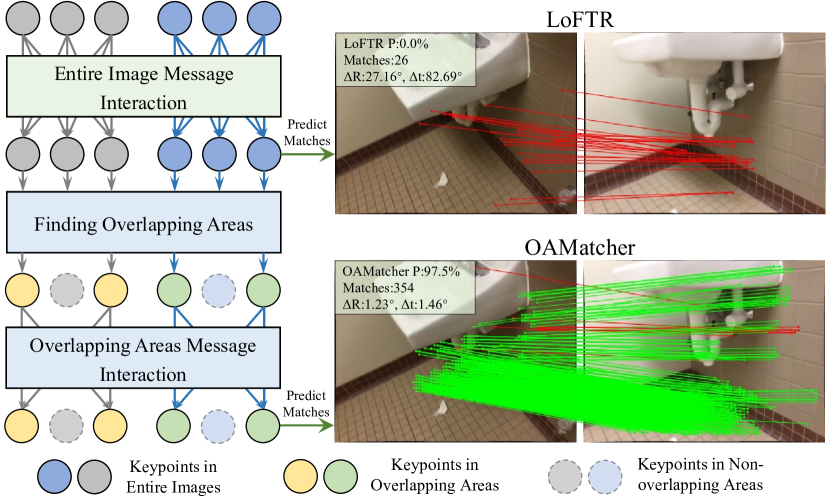
OAMatcher는 검출기 없이 트랜스포머 기반 네트워크로, 공동 가시 overlapped 영역에 집중하여 조밀하고 정확한 로컬 특징 매칭을 가능하게 하며, 노이즈 라벨을 처리하기 위한 매치 라벨 가중치 전략(MLWS)을 갖춘다.
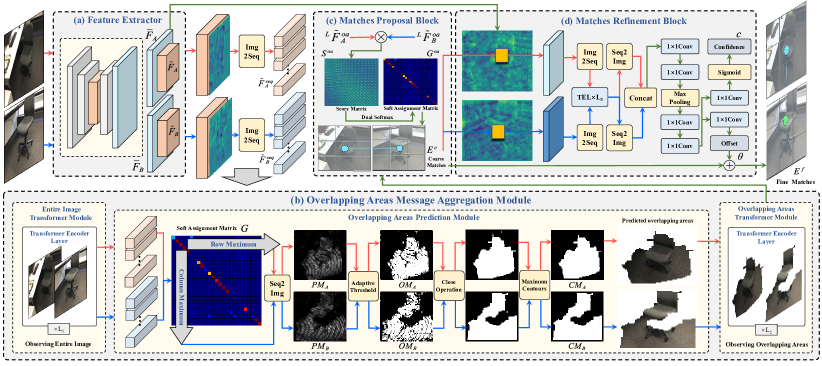
Local feature matching is an essential component in many visual applications. In this work, we propose OAMatcher, a Tranformer-based detector-free method that imitates humans behavior to generate dense and accurate matches. Firstly, OAMatcher predicts overlapping areas to promote effective and clean global context aggregation, with the key insight that humans focus on the overlapping areas instead of the entire images after multiple observations when matching keypoints in image pairs. Technically, we first perform global information integration across all keypoints to imitate the humans behavior of observing the entire images at the beginning of feature matching. Then, we propose Overlapping Areas Prediction Module (OAPM) to capture the keypoints in co-visible regions and conduct feature enhancement among them to simulate that humans transit the focus regions from the entire images to overlapping regions, hence realizeing effective information exchange without the interference coming from the keypoints in non overlapping areas. Besides, since humans tend to leverage probability to determine whether the match labels are correct or not, we propose a Match Labels Weight Strategy (MLWS) to generate the coefficients used to appraise the reliability of the ground-truth match labels, while alleviating the influence of measurement noise coming from the data. Moreover, we integrate depth-wise convolution into Tranformer encoder layers to ensure OAMatcher extracts local and global feature representation concurrently. Comprehensive experiments demonstrate that OAMatcher outperforms the state-of-the-art methods on several benchmarks, while exhibiting excellent robustness to extreme appearance variants. The source code is available at https://github.com/DK-HU/OAMatcher.
연구 동기 및 목표
- 검출기가 실패하는 극단적인 외관 변화 하에서도 견고한 로컬 특징 매칭의 동기를 부여합니다.
- cleaner context exchange를 위해 전체 이미지에서 겹치는 영역으로 초점을 이동시키는 인간 모방 워크플로를 도입합니다.
- 훈련 중 측정 노이즈를 완화하기 위한 GT 라벨 가중 메커니즘을 제안합니다.
- 글로벌 및 로컬 특징을 통합하여 조밀한 매칭을 위한 트랜스포머 기반 검출기 없는 아키텍처를 개발합니다.
- 실내 및 실외 벤치마크에서 최첨단 성능과 견고함을 입증합니다.]
- method: [
- Global information integration across all keypoints to imitate initial full-image observation.
- Overlapping Areas Prediction Module (OAPM) to identify co-visible regions via co-visible masks.
- Overlapping Areas Transformer Module (OATM) to enhance features within overlapping regions.
- Matches Proposal Block (MPB) and Matches Refinement Block (MRB) for coarse-to-fine matching.
- Match Labels Weight Strategy (MLWS) to assign probabilistic label confidences for training.
- Depth-wise convolution integrated into Transformer encoder layers to fuse local and global features.
제안 방법
- 초기 전체 이미지 관찰을 모방하기 위해 모든 키포인트에 걸친 글로벌 정보 통합.
- 공동 가시 마스크를 통해 동시 가시 영역을 식별하는 겹치는 영역 예측 모듈(OAPM).
- 겹치는 영역 내 특징을 강화하는 겹치는 영역 트랜스포머 모듈(OATM).
- 거친 매칭에서 세밀한 매칭으로의 과정을 위한 매치 제안 블록(MPB) 및 매치 정제 블록(MRB).
- 훈련을 위한 확률적 라벨 신뢰도 선정하는 매치 라벨 가중 전략(MLWS).
- 로컬 및 글로벌 특징을 융합하기 위해 트랜스포머 인코더 계층에 깊이별(convolution) 컨볼루션을 통합.
실험 결과
연구 질문
- RQ1전체 이미지 주의(attention) 대신 중첩(overlapping, co-visible) 영역을 예측하고 활용하는 것이 로컬 특징 매칭의 강건성 및 정확성을 향상시킬 수 있는가?
- RQ2확률적 라벨 신뢰도 메커니즘(MLWS)이 훈련 중 노이즈가 있는 GT 매칭을 더 잘 처리하는가?
- RQ3트랜스포머 계층 내 깊이별 컨볼루션 통합이 매칭을 위한 로컬/전역 특징 표현에 어떤 영향을 주는가?
- RQ4제안된 OAPM 및 OATM 구성요소가 벤치마크 전반에서 최첨단 detector-free 방법 대비 측정 가능한 이점을 제공하는가?
- RQ5OAMatcher가 검출기 기반 및 detector-free 베이스라인에 비해 극단적 외관 변화에 더 견고한가?
주요 결과
| 로컬 특징 | 매처 | CCM (ε<1/3/5 픽셀) 전반 | 조명 | 시점 |
|---|---|---|---|---|
| D2-Net | NN | 0.38/0.71/0.82 | 0.66/0.95/0.98 | 0.12/0.49/0.67 |
| SuperPoint | NN | 0.46/0.78/0.85 | 0.57/0.92/0.97 | 0.35/0.65/0.74 |
| SuperGlue | - | 0.51/0.82/0.89 | 0.60/0.92/0.98 | 0.42/0.71/0.81 |
| SGMNet | - | 0.52/0.85/0.91 | 0.59/0.94/0.98 | 0.46/0.74/0.84 |
| ClusterGNN | - | 0.52/0.84/0.90 | 0.61/0.93/0.98 | 0.44/0.74/0.81 |
| SparseNCNet | - | 0.36/0.65/0.76 | 0.62/0.92/0.97 | 0.13/0.40/0.58 |
| Patch2Pix | - | 0.50/0.79/0.87 | 0.71/0.95/0.98 | 0.30/0.64/0.76 |
| LoFTR | - | 0.55/0.81/0.86 | 0.74/0.95/0.98 | 0.38/0.69/0.76 |
| MatchFormer | - | 0.55/0.81/0.87 | 0.75/0.95/0.98 | 0.37/0.68/0.78 |
| OAMatcher | - | 0.0 |
- OAMatcher는 3px 및 5px 임계값에서 LoFTR 기반 대비 약 4–5 포인트의 성능 차이로 경쟁력 있는 성능을 달성하고 우수하게 수행합니다.
- HPatches에서 OAMatcher는 전반 CCM 0.54/0.85/0.91, 조명 0.67/0.95/0.98, 시점 0.42/0.75/0.84를 보고합니다.
- OAMatcher는 다른 방법들, 특히 detector-free 동료들에 비해 극단적인 외관 변화에 대해 견고함을 보여줍니다.
- 모델은 적응 임계값과 형태학적 후처리를 사용하여 겹치는 영역에 초점을 맞춘 공동 가시 마스크를 도출합니다.
- MLWS는 매치 라벨에 확률적 신뢰도를 할당하여 노이즈가 있거나 잘못된 GT 라벨의 영향을 완화합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.