[논문 리뷰] ONCE: Boosting Content-based Recommendation with Both Open- and Closed-source Large Language Models
ONCE는 오픈소스 LLM을 콘텐츠 인코더로, 폐쇄형 LLM을 데이터 보강으로 활용하여 컨텐츠 기반 추천 시스템을 강화하고 두 유형 간의 보완적 시너지를 보여준다.
Personalized content-based recommender systems have become indispensable tools for users to navigate through the vast amount of content available on platforms like daily news websites and book recommendation services. However, existing recommenders face significant challenges in understanding the content of items. Large language models (LLMs), which possess deep semantic comprehension and extensive knowledge from pretraining, have proven to be effective in various natural language processing tasks. In this study, we explore the potential of leveraging both open- and closed-source LLMs to enhance content-based recommendation. With open-source LLMs, we utilize their deep layers as content encoders, enriching the representation of content at the embedding level. For closed-source LLMs, we employ prompting techniques to enrich the training data at the token level. Through comprehensive experiments, we demonstrate the high effectiveness of both types of LLMs and show the synergistic relationship between them. Notably, we observed a significant relative improvement of up to 19.32% compared to existing state-of-the-art recommendation models. These findings highlight the immense potential of both open- and closed-source of LLMs in enhancing content-based recommendation systems. We will make our code and LLM-generated data available for other researchers to reproduce our results.
연구 동기 및 목표
- 더 풍부한 콘텐츠 표현을 통해 콘텐츠 기반 추천 시스템의 개선을 고무한다.
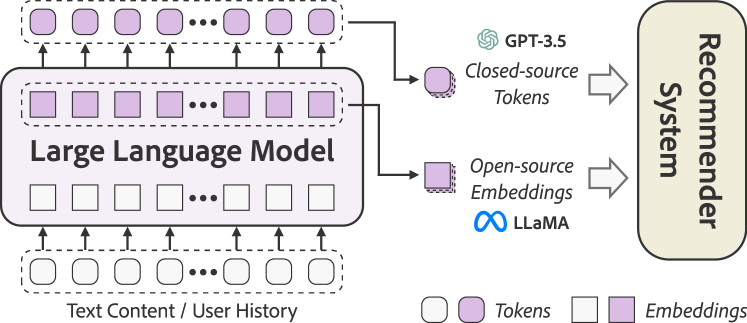
- 오픈소스 LLM을 콘텐츠 인코더(DIRE)로 활용하기 위한 파인튜닝 가능성 연구를 탐구한다.
- 데이터 보강을 위해 폐쇄형 LLM을 프롬프트로 활용하는 GENRE를 연구한다.
- 오픈-소스와 클로즈드 소스 LLM을 통합 프레임워크에서 결합했을 때의 시너지를 탐구한다.
- 표준 벤치마크(MIND, Goodreads)에서의 성능 향화에 대한 실증적 근거를 제공한다.
제안 방법
- 오픈소스 LLM으로 콘텐츠 인코더를 대체하거나 보강하고, 주의(attention) 레이어를 통해 표현을 융합한다(DIRE).
- 다중 필드 콘텐츠를 단일 시퀀스로 변환하는 자연어 템플릿을 사용하고 LLM 임베딩으로 매핑한다.
- 매개변수 효율적 방법(LoRA)으로 LLM의 상단 k 레이어만 파인튜닝하고 계산 비용을 줄이기 위해 캐싱을 사용한다.
- 폐쇄형 LLM(GPT-3.5)을 프롬프트하여 풍부한 데이터 설명 및 사용자 프로필을 생성한다(GENRE).
- LLM이 생성한 요약 및 사용자 프로파일링을 데이터 증강 및 특징 강화로 하여 다운스트림 추천에 반영한다(ALL).
- 사용자 프로필과 콘텐츠 합성을 반복적으로 개선하기 위해 체인 기반 생성(chain-based generation)으로 탐구한다.
실험 결과
연구 질문
- RQ1오픈소스 LLM을 콘텐츠 인코더(DIRE)로 사용하는 것이 콘텐츠 기반 추천 성능에 어떤 영향을 미치는가?
- RQ2폐쇄형 LLM(GENRE)이 훈련 데이터를 보강해 다운스트림 모델을 향상시킬 수 있는 방법은 무엇인가?
- RQ3오픈-소스와 클로즈드 소스 LLM은 추천 품질과 학습 효율성에 보완적인 이점을 제공하는가?
- RQ4추천을 위한 오픈소스 LLM의 파인튜닝 전략(어떤 레이어, LoRA)이 미치는 영향은 무엇인가?
- RQ5두 종류의 LLM을 결합한 경우(ONCE)가 표준 데이터셋에서 어떤 전체적 이득을 제공하는가?
주요 결과
| 데이터셋 | 모델 | AUC | MRR | N@5 | N@10 |
|---|---|---|---|---|---|
| MIND | Original | 61.75 | 30.60 | 31.35 | 37.85 |
| MIND | DIRE (BERT 12L) | 65.32 | 33.16 | 34.29 | 40.35 |
| MIND | LLaMA 7B (Ours) | 68.34 | 35.80 | 37.60 | 43.48 |
| MIND | LLaMA 13B (Ours) | 68.23 | 35.99 | 37.93 | 43.77 |
| MIND | GENRE (CS) | 63.73 | 31.83 | 32.94 | 39.24 |
| MIND | GENRE (UP) | 62.19 | 30.90 | 31.78 | 38.26 |
| MIND | GENRE (CG) | 62.93 | 30.83 | 32.10 | 38.34 |
| MIND | GENRE (UP → CG) | 63.61 | 31.58 | 32.63 | 39.07 |
| MIND | ALL (Ours) | 63.88 | 32.17 | 33.14 | 39.37 |
| MIND | ONCE (Ours) | 68.62 | 36.50 | 38.31 | 44.05 |
| Goodreads | Original | 66.47 | 75.75 | 58.49 | 82.20 |
| Goodreads | DIRE (BERT 12L) | 70.68 | 78.17 | 62.26 | 83.99 |
| Goodreads | LLaMA 7B (Ours) | 77.01 | 82.74 | 71.09 | 89.39 |
| Goodreads | LLaMA 13B (Ours) | 77.43 | 83.05 | 71.56 | 87.61 |
| Goodreads | GENRE (CS) | 67.68 | 76.41 | 59.64 | 82.69 |
| Goodreads | GENRE (UP) | 68.45 | 76.91 | 60.70 | 83.08 |
| Goodreads | GENRE (CG) | 66.94 | 76.10 | 59.26 | 82.47 |
| Goodreads | GENRE (UP → CG) | 67.98 | 76.78 | 60.56 | 82.96 |
| Goodreads | ALL (Ours) | 68.95 | 77.25 | 61.19 | 83.32 |
| Goodreads | ONCE (Ours) | 77.63 | 83.13 | 71.65 | 87.66 |
- 오픈소스 LLM(LLaMA)은 콘텐츠 인코더로서 강력한 개선을 제공하며, 베이스라인 대비 AUC와 MRR의 주목할 만한 이득이 있다.
- 프롬프트를 활용한 폐쇄형 LLM(GPT-3.5)은 데이터 보강을 통해 성능을 개선하고, 오픈소스 LLM과 결합했을 때 상당한 이득을 달성한다.
- 이중 LLM 접근 방식인 ONCE는 모든 데이터셋에서 최상의 성능을 보이며, 원본 및 단일 LLM 베이스라인 대비 일관되게 향상된다.
- 오픈소스 LLM의 상단 레이어 파인튜닝(또는 LoRA 사용)은 일반적으로 더 큰 이득을 가져오지만, 데이터셋과 모델 크기에 따라 효과가 달라진다.
- ONCE는 학습을 가속화하여 예를 들어 폐쇄형 LLM 정보를 활용할 때 학습 초기에 비슷한 성능을 달성한다.
- 데이터 보강 프롬프트와 콘텐츠 인코더 파인튜닝의 조합은 오픈-소스 LLM과 클로즈드-소스 LLM 간의 보완적 관계를 보여준다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.