[논문 리뷰] One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion
One-2-3-45++는 단일 이미지를 약 1분 만에 고해상도 질감이 있는 3D 메시로 변환한다. (1) 미세 조정된 2D 확산으로 일관된 다중 시점을 생성하고, (2) 다중 시점 조건이 있는 3D 확산과 경량 텍스처 정제를 통해 이를 올린다.
Recent advancements in open-world 3D object generation have been remarkable, with image-to-3D methods offering superior fine-grained control over their text-to-3D counterparts. However, most existing models fall short in simultaneously providing rapid generation speeds and high fidelity to input images - two features essential for practical applications. In this paper, we present One-2-3-45++, an innovative method that transforms a single image into a detailed 3D textured mesh in approximately one minute. Our approach aims to fully harness the extensive knowledge embedded in 2D diffusion models and priors from valuable yet limited 3D data. This is achieved by initially finetuning a 2D diffusion model for consistent multi-view image generation, followed by elevating these images to 3D with the aid of multi-view conditioned 3D native diffusion models. Extensive experimental evaluations demonstrate that our method can produce high-quality, diverse 3D assets that closely mirror the original input image. Our project webpage: https://sudo-ai-3d.github.io/One2345plus_page.
연구 동기 및 목표
- 단일 이미지에서 고해상도 3D 자산을 생성하기 위해 2D 확산 프라이어와 제한된 3D 데이터를 활용한다.
- 일관된 다중 뷰 이미지 생성을 보장하여 다운스트림 3D 재구성을 향상시킨다.
- 다중 뷰 조건이 있는 3D 확산 모델로 다중 뷰 이미지를 3D로 올리고 텍스처를 효율적으로 정제한다.
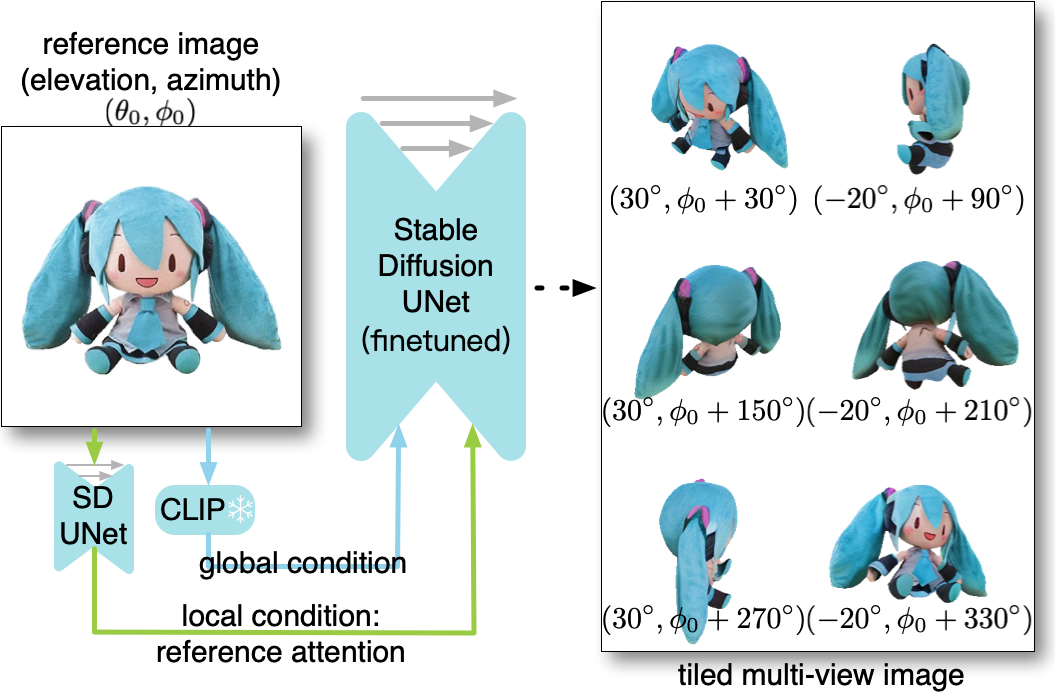
제안 방법
- 여섯 시점을 하나의 이미지로 타일링하고 입력 이미지에 조건화된 일관된 다중 뷰 합성을 생성하도록 2D 확산 모델을 미세 조정한다.
- 다중 뷰 조건이 있는 3D 확산 모델을 사용하여 채택-고해상도 SDF+컬러를 포함하는 점진적 2단계(coarse-to-fine) 프로세스에서 질감이 있는 3D 메시를 재구성한다(점유/용량 then high-res SDF+color).
- 다중 뷰 로컬 이미지 특징을 알려진 카메라 포즈로 투영해 3D 확산을 안내하는 3D 특징 볼륨을 구축한다.
- CLIP 기반의 글로벌 조건과 다중 뷰 조건 부피를 이용한 3D 확산에서 점유 및 컬러 출력을 함께 반영한다.
- 일관된 다중 뷰 이미지를 감독으로 사용해 컬러 필드(TensorField 스타일)를 최적화하는 경량 텍스처 정제 단계를 적용한다.
- 데이터 증강과 무작위 포즈 섭동으로 Objaverse/Objaverse 유래 렌더링에서 학습하고, 추론은 64^3 점유 볼륨의 디노이즈링, 그다음 고해상도 희소 볼륨 확산 및 marching cubes를 수행한다.

실험 결과
연구 질문
- RQ1일관된 다중 뷰 생성이 단일 이미지로부터의 3D 재구성 품질을 향상시킬 수 있는가?
- RQ2다중 뷰 조건이 있는 3D 확산 모델이 이전의 NeRF 기반 또는 확산 기반 방법보다 더 높은 품질의 질감 있는 메시를 생성하는가?
- RQ3제안된 2단계 3D 확산과 경량 텍스처 정제가 입력 이미지에 충실하게 유지되면서 더 빠른가?
- RQ4다중 뷰 로컬 조건은 3D 확산에서 글로벌 조건에 비해 3D IoU, F-점수, CLIP 유사도 측면에서 어떻게 비교되는가?
주요 결과
| Method | F-스코어(%) | CLIP-유사도 | 사용자 선호도 | 시간 |
|---|---|---|---|---|
| Zero123 XL [10] | 91.6 | 73.1 | 58.6 | 30min |
| One-2-3-45 [34] | 90.4 | 70.8 | 52.7 | 45s |
| SyncDreamer [37] | 84.8 | 68.9 | 28.4 | 6min |
| DreamGaussian [63] | 81.0 | 68.4 | 31.5 | 2min |
| Shap-E [25] | 91.8 | 73.1 | 40.8 | 27s |
| Ours | 93.6 | 81.0 | 87.6 | 60s |
- 단일 이미지에서 3D로의 베이스라인을 F-Score, CLIP 유사도 및 GSO 데이터세트의 사용자 선호도에서 능가한다(예: One-2-3-45++는 93.6 F-Score, 81.0 CLIP-Sim, 87.6 User-Pref, 60s).
- 런타임 측면에서 최적화 기반 방법보다 우수한 성능을 보이며(≤1 분), 입력 시야에 대한 충실도 유지 또는 향상을 달성한다.
- 제거 시 3D IoU 및 CLIP 유사도가 저하되므로 일관된 다중 뷰 생성을 포함한 다중 뷰 조건 3D 확산의 중요성이 확인된다.
- 다중 뷰 감독으로 텍스처 정제가 텍스처 품질과 CLIP 유사도를 향상시킨다.
- 텍스트-에서-3D baselines와 비교하여 One-2-3-45++가 더 높은 CLIP 유사도와 사용자 선호를 달성하며 런타임이 훨씬 빠르다(60s 대 수 시간).
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.