[논문 리뷰] Optimization of a Radiofrequency Ablation FEM Application Using Parallel Sparse Solvers
이 논문은 다중코어 및 GPU 플랫폼에서 병렬 희소 해법(MAGMA cuSOLVER, QRMumps)을 사용하여 RAFEM 유한요소 시뮬레이션을 라디오주파수 절제용으로 가속하고 수치 품질을 유지하면서 최대 40배의 가속을 달성합니다.
Finite element method applications are a common approach to simulate a handful of phenomena but can take a lot of computing power, causing elevated waiting time to produce precise results. The radiofrequency ablation finite element method is an application to simulate the medical procedure of radiofrequency ablation, a minimally invasive liver cancer treatment. The application runs sequentially and can take up to 20 hours of execution to generate 15 minutes of simulation results. Most of this time arises from the need to solve a sparse system of linear equations. In this work, we accelerate this application by using three sparse solvers packages (MAGMA cuSOLVER, and QRMumps), including direct and iterative methods over different multicore and GPU architectures. We conducted a numerical result analysis to access the solution quality provided by the distinct solvers and their configurations, proposing the use of the peak signal-to-noise ratio metric. We were able to reduce the application execution time up to 40 times compared to the original sequential version while keeping a similar numerical quality for the results.
연구 동기 및 목표
- 간 RFA 치료를 위한 계산 비용이 큰 RAFEM FEM 응용 프로그램의 속도 향상을 고무하는 것.
- 해결 단계에서 다중코어 CPU와 GPU에서 병렬 희소 해법(직접 해법 및 반복 해법)을 조사한다.
- 원래의 순차 해와 대조하여 PSNR을 사용해 병렬 해의 수치적 품질을 평가한다.
- 다양한 하드웨어, 메쉬 크기, 해법 구성에서 성능을 분석한다.
- 유사한 FEM 응용에 희소 해법을 적용하기 위한 방법론적 지침을 제공한다.
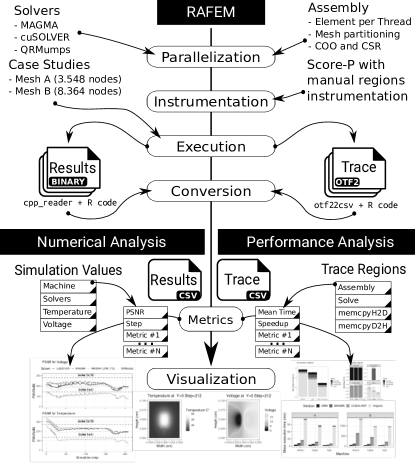
제안 방법
- RAFEM 해석 단계를 병렬화하고 CPU/GPU에서 원래 해법을 MAGMA, cuSOLVER (sparse QR), 및 QRMumps (sparse QR)로 대체한다.
- QRMumps용 COO 입력을 지원하도록 행렬 어셈블리를 확장하고 열 순서 재배치를 재사용하여 분석 시간을 줄인다.
- 해법 매개변수 조정: Scotch/Metis 재배치, QRMumps의 블록 크기, MAGMA의 GMRES m 매개변수, 허용오차 설정.
- 코드(ScoreP/OTF2)를 계측하고 추적하여 어셈블리, 해석, 호스트-디바이스 메모리 전송 비용을 구분한다.
- 순차 참조와의 비교를 위해 PSNR를 사용하고, 단계 결과의 2D 보간을 통해 공간 차이를 분석한다.
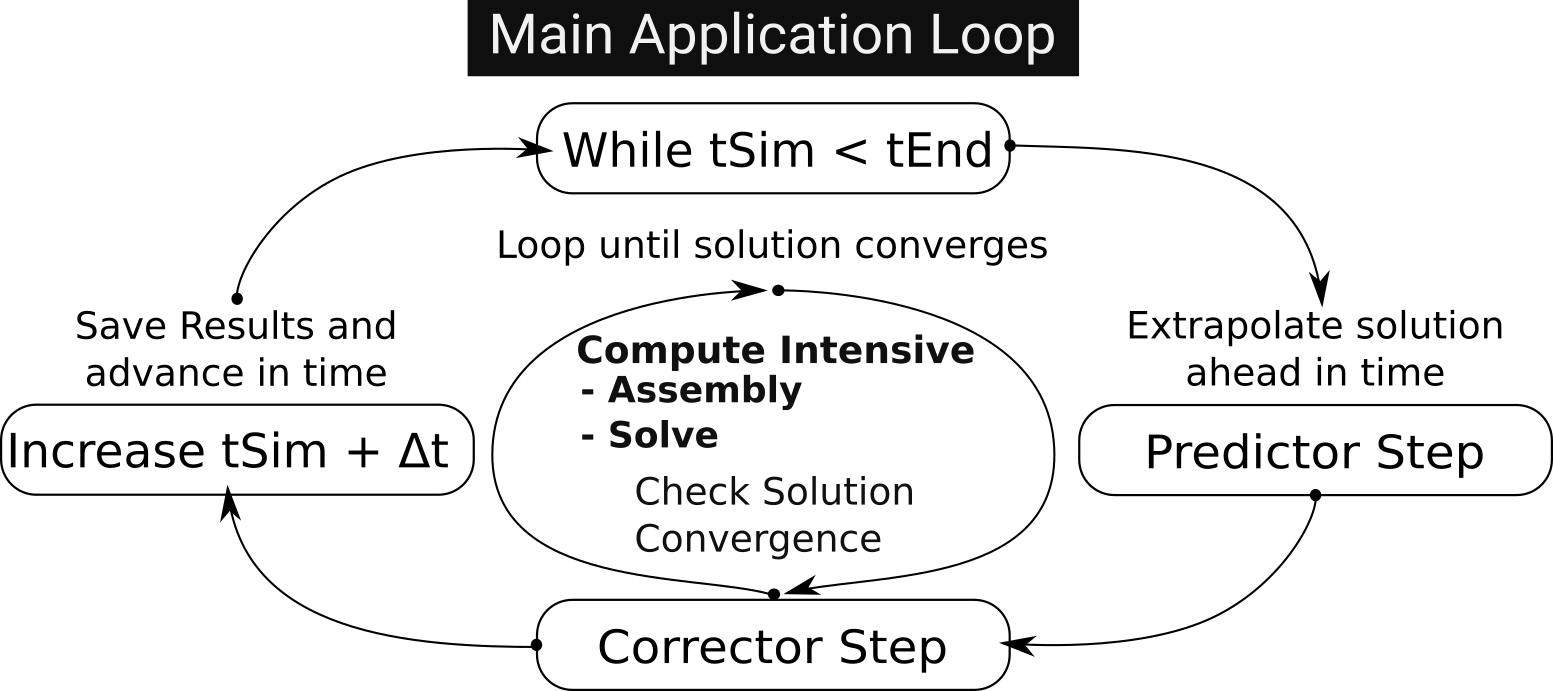
실험 결과
연구 질문
- RQ1다양한 메쉬와 기계에서 MAGMA, cuSOLVER, QRMumps 등 서로 다른 희소 해법이 런타임과 확장성에 대해 어떻게 비교되는가?
- RQ2GPU 가속 및 해법 구성의 수치 품질에 대한 영향이 PSNR으로 측정될 때 순차 RAFEM 결과에 비해 어떤가?
- RQ3재배치 전략과 해법 허용오차가 수렴성, 정확도 및 전체 실행 시간에 어떤 영향을 미치는가?
- RQ4허용오차를 줄이거나 서로 다른 해법을 사용할 때 수치 정확도와 속도 사이에 뚜렷한 트레이드오프가 존재하는가?
- RQ5데이터 이동(CPU↔GPU)로 인한 오버헤드가 있으며, 이를 통해 전체 워크로드에서 성능에 어떤 영향을 미치는가?
주요 결과
- QRMumps는 기계와 워크로드 전반에서 다른 해법보다 더 빠른 해를 consistently 달성했다.
- 전반적인 속도 향상은 순차 RAFEM 버전에 비해 2.12x에서 40.4x까지 나타났으며, 더 강력한 GPU일수록 상승 폭이 더 컸다.
- cuSOLVER는 더 큰 메쉬에서 확장성이 떨어지는 것으로 나타나, 더 큰 문제에서 그 해법의 확장성 문제가 존재함을 시사한다.
- MAGMA GMRES를 느슨한 허용오차(10^-6)로 사용하면 총 시간이 최대 약 20% 감소했으나 수치 정확도 및 일부 단계의 수렴이 악화될 수 있다.
- PSNR 분석은 서로 다른 해법이 질적으로 비슷한 결과를 낳지만, MAGMA의 낮은 허용오차에서 특히 mesh A에 대해 PSNR이 현저히 낮아지고 수치 차이가 커지는 경향이 있음을 보였다.
- 메모리 전송 오버헤드는 해법 시간을 줄일 때 더 크게 나타나므로 비동기 중첩(overlap)을 통한 최적화 가능성을 시사한다.
- 더 강력한 GPU 하드웨어(Tupi 대 Hype 등)가 가속을 강화하여 하드웨어 발전의 이점을 확인시켜 준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.