[논문 리뷰] Orca 2: Teaching Small Language Models How to Reason
Orca 2는 소형 LMs를 다양한 추론 전략과 Prompt Erasing 기법으로 학습시켜 주의 깊은 추론가가 되도록 하고, 강력한 제로샷 성능을 달성하며 훨씬 더 큰 모델들과 경쟁합니다. 가중치는 공개되었습니다.
Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LMs' reasoning abilities. Research on training small LMs has often relied on imitation learning to replicate the output of more capable models. We contend that excessive emphasis on imitation may restrict the potential of smaller models. We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task. We evaluate Orca 2 using a comprehensive set of 15 diverse benchmarks (corresponding to approximately 100 tasks and over 36,000 unique prompts). Orca 2 significantly surpasses models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. make Orca 2 weights publicly available at aka.ms/orca-lm to support research on the development, evaluation, and alignment of smaller LMs
연구 동기 및 목표
- 모방 학습을 넘어서 작은 LMs의 추론 능력을 향상시키려는 동기를 부여합니다.
- 작은 LMs가 여러 추론 전략을 활용하도록 가르칩니다(단계별, 기억-생성, 기억-추론-생성, 직접 답변 등).
- 작업별로 가장 효과적인 전략을 선택하도록 모델을 가능하게 합니다(작업 기반 전략 선택).
- 약 100개의 작업과 15개의 벤치마크에서 Orca 2를 평가하고 더 큰 기준선과 비교합니다.
- 소형 LM 개발, 평가 및 정렬에 대한 연구를 지원하기 위해 Orca 2 가중치를 공개적으로 제공합니다.
제안 방법
- 능력 있는 교사로부터 풍부한 추론 신호를 제공하기 위해 Explanation Tuning을 활용합니다.
- 원을 제공하기 위해 Prompt Erasing을 도입합니다(원래 프롬프트에 접근하지 않고도 전략을 추론하는 신중한 추론자를 학습시키기 위해).
- FLAN-v2, Orca 1, Orca 2 출처에서 점진적 학습으로 Orca 2 데이터셋(~817K 학습 인스턴스)을 구성합니다.
- FLAN-v2에서 시작하고, 그다음 Orca 1 데이터, 그리고 GPT-4 데이터와의 혼합을 LLaMA-2 기반에서 적용합니다.
- 32개의 A100 GPU에서 bf16로 학습을 최적화하기 위해 패킹과 최대 시퀀스 길이 4096 토큰을 사용합니다; 손실은 교사 생성 토큰에 의해서만 계산됩니다.
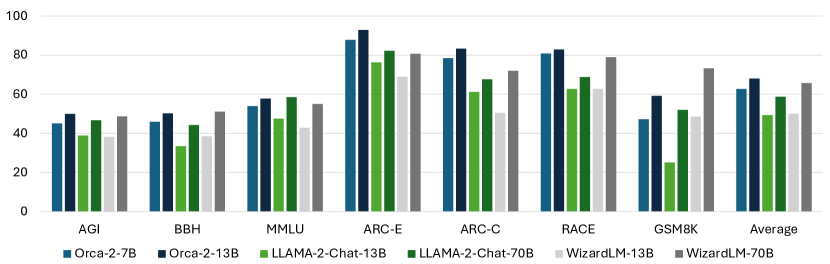
실험 결과
연구 질문
- RQ1더 큰 모델의 모방을 넘어 다양한 추론 전략의 레퍼토리를 소형 LMs가 학습하고 적용할 수 있을까요?
- RQ2주어진 작업에 대해 소형 LM이 가장 효과적인 추론 전략을 어떻게 선택해야 할까요?
- RQ3Prompt Erasing을 사용한 신중한 추론이 표준 모방 기반 접근법과 비교해 제로샷 성능을 개선합니까?
- RQ4다양한 추론 벤치마크에서 Orca 2 모델은 더 큰 모델과 어떻게 비교됩니까?
주요 결과
| 모델 | AGI | BBH | DROP | CRASS | RACE | GSM8K |
|---|---|---|---|---|---|---|
| Orca 2-7B | 45.10 | 45.93 | 60.26 | 84.31 | 80.79 | 47.23 |
| Orca 2-7B w/ cautious sm | 43.97 | 42.80 | 69.09 | 88.32 | 75.82 | 55.72 |
| Orca 2-13B | 49.93 | 50.18 | 57.97 | 86.86 | 82.87 | 59.14 |
| Orca 2-13B w/ cautious sm | 48.18 | 50.01 | 70.88 | 87.59 | 79.16 | 65.73 |
| Orca-1-13B | 45.69 | 47.84 | 53.63 | 90.15 | 81.76 | 26.46 |
| LLaMA-2-Chat-13B | 38.85 | 33.6 | 40.73 | 61.31 | 62.69 | 25.09 |
| WizardLM-13B | 38.25 | 38.47 | 45.97 | 67.88 | 62.77 | 48.60 |
| LLaMA-2-Chat-70B | 46.70 | 44.68 | 54.11 | 74.82 | 68.79 | 52.01 |
| WizardLM-70B | 48.73 | 51.08 | 59.62 | 86.13 | 78.96 | 73.24 |
| ChatGPT | 53.13 | 55.38 | 64.39 | 85.77 | 67.87 | 79.38 |
| GPT-4 | 70.40 | 69.04 | 71.59 | 94.53 | 83.08 | 85.52 |
- Orca 2-13B는 같은 크기의 모델들보다 제로샷 추론 작업에서 현저히 우수합니다.
- Orca 2-13B는 여러 복잡한 추론 벤치마크에서 5~10배 더 큰 모델들과 맞먹거나 능가합니다.
- 신중한 시스템 프롬프트를 활용하면 Orca 2는 CRASS, DROP, RACE, GSM8K 등 여러 데이터셋에서 주목할 만한 이득을 달성합니다.
- 전체적으로 Orca 2–13B는 70B 매개변수 rival와 경쟁력 있는 성능과 더 강한 제로샷 추론 능력을 보여줍니다.
- 이 연구는 AGIeval, BBH, DROP, CRASS, RACE, GSM8K 등에서 자세한 제로샷 결과를 보고하며 강건한 추론 능력을 보여줍니다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.