[논문 리뷰] OWQ: Outlier-Aware Weight Quantization for Efficient Fine-Tuning and Inference of Large Language Models
OWQ는 이상치 인식 가중치 양자화를 통해 약한 열은 더 높은 정밀도로 유지하고 나머지는 양자화하며, Weak Column Tuning(WCT)으로 작업별 적응을 가능하게 하여 약 3.1비트 수준에서 4비트 OPTQ와 비슷한 품질을 달성하고 효율적인 미세조정을 가능하게 한다.
Large language models (LLMs) with hundreds of billions of parameters require powerful server-grade GPUs for inference, limiting their practical deployment. To address this challenge, we introduce the outlier-aware weight quantization (OWQ) method, which aims to minimize LLM's footprint through low-precision representation. OWQ prioritizes a small subset of structured weights sensitive to quantization, storing them in high-precision, while applying highly tuned quantization to the remaining dense weights. This sensitivity-aware mixed-precision scheme reduces the quantization error notably, and extensive experiments demonstrate that 3.1-bit models using OWQ perform comparably to 4-bit models optimized by OPTQ. Furthermore, OWQ incorporates a parameter-efficient fine-tuning for task-specific adaptation, called weak column tuning (WCT), enabling accurate task-specific LLM adaptation with minimal memory overhead in the optimized format. OWQ represents a notable advancement in the flexibility, efficiency, and practicality of LLM optimization literature. The source code is available at https://github.com/xvyaward/owq
연구 동기 및 목표
- 대규모 언어 모델의 추론 및 미세조정 중 메모리와 계산량을 줄이는 것을 동기로 삼는다.
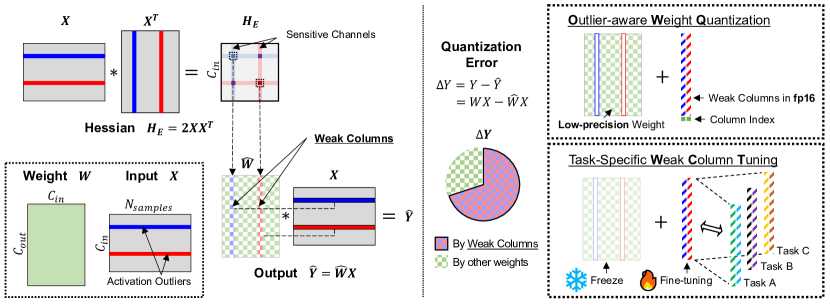
- LLM에서 양자화 오차의 주요 원인으로 활성화 이상치를 식별한다.
- 민감한(약한) 열을 보호하고 나머지는 과감하게 양자화하기 위해 OWQ를 제안한다.
- OWQ 양자화 모델에서 매개변수 효율적인 작업 적응을 가능하게 하는 WCT를 도입한다.
- 낮은 오버헤드로 OPT 및 LLaMA 계열 전반에 걸친 이득을 입증한다.]
- method_
- Identify weak columns by computing a channel-wise sensitivity using the Hessian diagonal and weight perturbation magnitude (sensitivity_j = lambda_j * ||Delta W_:,j||^2).
- Exclude weak columns from quantization and apply mixed-precision by quantizing remaining columns with OPTQ-based techniques, including a truncation-enhanced configuration search.
- Store weak columns in fp16 and a small index per column to designate weak columns with negligible storage overhead (~0.3%).
- Apply OPTQ to the non-weak columns with a modified configuration search that includes truncation and per-channel quantization considerations.
- Introduce Weak Column Tuning (WCT) that fine-tunes only the previously identified weak columns after OWQ quantization to improve task adaptation with minimal memory overhead.
- Demonstrate real-device acceleration via a customized OWQ CUDA kernel that handles weak-column on-the-fly processing.
제안 방법
- 채널별 민감도와 가중치 섭동 크기를 이용해 Hessian 대각선으로 약한 열을 식별한다(sensitivity_j = lambda_j * ||Delta W_:,j||^2).
- 약한 열은 양자화에서 제외하고 나머지 열에 대해 OPTQ 기반 기법으로 혼합정밀도를 적용하며, 절단/자르는 구성을 포함한 구성을 탐색한다.
- 약한 열은 fp16으로 저장하고 열마다 작은 인덱스를 두어 저장 오버헤드를 거의 0.3% 수준으로 식별한다.
- 비약한 열에 대해서는 절단 및 채널당 양자화를 고려한 수정된 구성 탐색을 통해 OPTQ를 적용한다.
- OWQ 양자화 후 이전에 식별된 약한 열만 미세조정하는 Weak Column Tuning(WCT)을 도입해 메모리 오버헤드를 최소화하며 작업 적응을 향상시킨다.
- 혼합정밀 처리에도 불구하고 약한 열-컬럼을 다루는 맞춤형 OWQ CUDA 커널을 통해 실제 디바이스에서 가속을 시연한다.
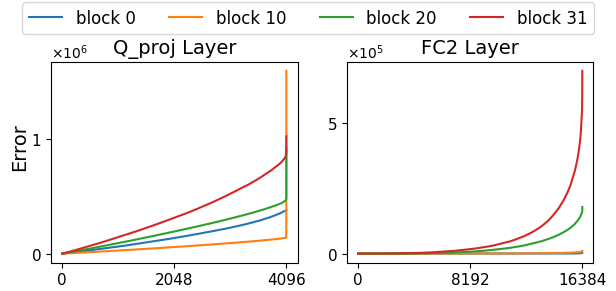
실험 결과
연구 질문
- RQ1활성화 이상치를 가중치 양자화에서 효과적으로 반영하여 LLM의 양자화 오차를 줄일 수 있는가?
- RQ2약한 열 인식 혼합정밀도 체계(OWQ)가 더 높은 비트 기준선(예: 4비트 OPTQ)과 비교해 낮은 유효 비트폭에서 유사한 성능을 달성하는가?
- RQ3Weak Column Tuning(WCT)이 OWQ 양자화 모델의 미세조정을 메모리 오버헤드를 크게 증가시키지 않으면서 경쟁력 있거나 우수한 성능을 가능하게 하는가?
- RQ4OPT 및 LLaMA와 같은 대형 모델에서 추론 및 미세조정에서 OWQ의 실제 오버헤드(대기시간 및 저장소)는 어느 정도인가?
주요 결과
- 3.1-bit OWQ 모델은 WikiText-2의 perplexity 및 관련 지표에서 모델 규모에 관계없이 4-bit OPTQ와 대등한 성능을 달성한다.
- 3.01-bit OWQ 모델은 결과를 더욱 개선하며 3-bit OPTQ를 능가하고 OPT 및 LLaMA 계열 전반에서 이득이 관찰된다.
- OWQ는 다양한 모델 규모에서 OPTQ보다 일관되게 모델 품질을 향상시키며, 양자화 감소가 더 두드러지는 더 작은 모델에서도 그렇다.
- 약한 열 인식은 소수의 열만 고정정밀도로 유지하는 방식으로 저장 오버헤드가 거의 없으며(≈0.3%), 상당한 정확도 이득을 제공한다.
- WCT는 QLoRA보다 훨씬 적은 학습 가능한 매개변수로 작업별 적응을 가능하게 하며 추론 중 메모리 사용이 훨씬 낮은 상태에서 전체 정밀도 LoRA 성능에 근접할 수 있다.
- 특정 OWQ CUDA 커널을 통해 혼합정밀 처리에도 불구하고 실제 양자화 속도를 유지한다(예: A100에서 66B 모델 양자화에 거의 ~3시간 이내).
- 미세조정 시 OWQ+WCT는 경쟁적인 PTQ 기반 미세조정 방법을 능가할 수 있으며 GPT-4 기반 점수를 사용하는 Vicuna Benchmark 평가에서 개방형-LM 작업에서 강한 성능을 달성한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.