[논문 리뷰] PaDeLLM-NER: Parallel Decoding in Large Language Models for Named Entity Recognition
PaDeLLM-NER은 모든 라벨-언급 쌍의 병렬 디코딩으로 NER 추론을 가속화하여 출력 길이와 지연 시간을 감소시키면서 예측 품질을 유지합니다.
In this study, we aim to reduce generation latency for Named Entity Recognition (NER) with Large Language Models (LLMs). The main cause of high latency in LLMs is the sequential decoding process, which autoregressively generates all labels and mentions for NER, significantly increase the sequence length. To this end, we introduce Parallel Decoding in LLM for NE} (PaDeLLM-NER), a approach that integrates seamlessly into existing generative model frameworks without necessitating additional modules or architectural modifications. PaDeLLM-NER allows for the simultaneous decoding of all mentions, thereby reducing generation latency. Experiments reveal that PaDeLLM-NER significantly increases inference speed that is 1.76 to 10.22 times faster than the autoregressive approach for both English and Chinese. Simultaneously it maintains the quality of predictions as evidenced by the performance that is on par with the state-of-the-art across various datasets.
연구 동기 및 목표
- 대형 언어 모델을 사용한 명명 엔터티 인식의 생성 지연 시간 감소.
- 새로운 모듈이나 구조적 변경을 추가하지 않고 병렬 디코딩을 통합.
- 영어와 중국어 NER 데이터셋 전반에서 예측 품질을 유지하거나 향상.
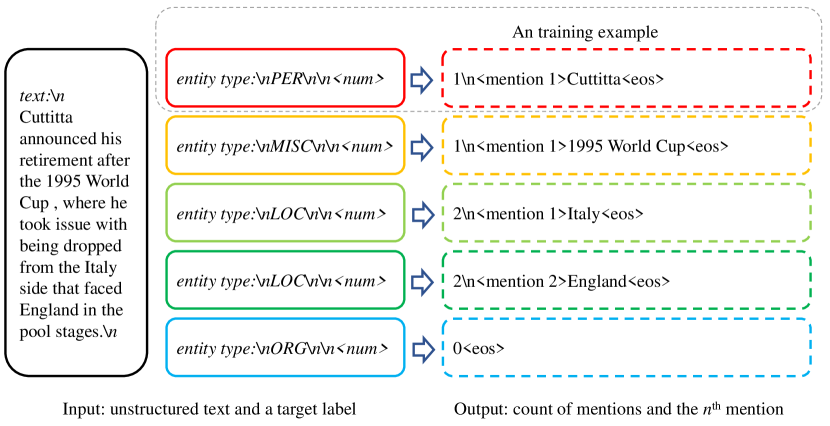
- 레이블당 언급 개수를 세고 n번째 언급을 식별하도록 학습 방식을 재구성.
- 병렬 디코딩된 라벨-언급 쌍의 집계 및 중복 제거를 가능하게 한다.
제안 방법
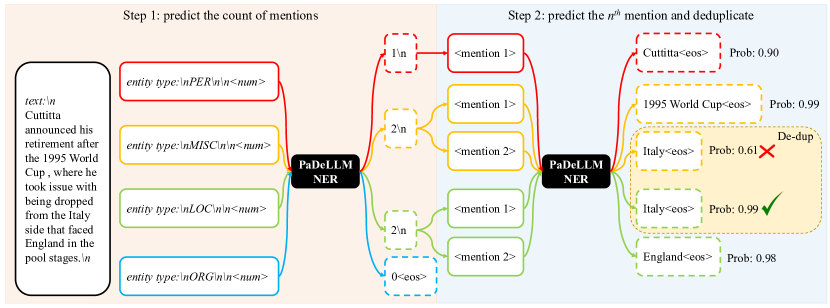
- 입력에서 각 라벨의 언급 수와 n번째 언급을 예측하도록 LLM을 학습시키기 위해 지시 미세조정(instruction-tuning)을 재구성한다.
- 추론 중에는 먼저 각 라벨의 언급 수를 예측한 뒤 병렬로 모든 라벨-언급 쌍을 생성하고 결과를 집계한다.
- 고유 텍스트당 가장 높은 확률 인스턴스를 보관하여 라벨 간 언급 중복을 제거한다.
- 두 가지 추론 모드를 사용한다: PaDeLLM Multi(다중 GPU, 시퀀스당 GPU) 및 PaDeLLM Batch(배치 처리 단일 GPU).
- 카운트 예측 뒤의 시퀀스 토큰에 대해 크로스 엔트로피 손실로 학습하되, 제거 실험 결과에 따라 언급 구간 토큰은 무시한다.
실험 결과
연구 질문
- RQ1라벨-언급 쌍의 병렬 디코딩이 정확도를 희생하지 않으면서 NER 추론 지연 시간을 줄일 수 있는가?
- RQ2카운팅-언급의 두 단계 전략이 영어 및 중국어 NER 데이터셋의 예측 품질에 어떤 영향을 미치는가?
- RQ3중복 제거가 다중 라벨 NER 출력의 정밀도, 재현율 및 전체 F1에 미치는 영향은?
- RQ4PaDeLLM-NER의 속도 향상이 언어 간 flat 및 nested NER 작업에서 자동회귀 기준 대비 어떤가?
주요 결과
- 추론 지연 시간은 PaDeLLM-NER으로 크게 감소하며 자동회귀 기준 대비 (1.76x에서 10.22x 속도 향상).
- 예제당 평균 시퀀스 길이가 자동회귀 방식의 약 13%로 감소하여 속도 향상에 기여.
- PaDeLLM-NER은 평균 micro-F1이 약 84.79로 베이스라인을 능가하고, 영어 및 중국어 데이터셋 중 여러 곳에서 우수합니다(9개 데이터셋 중 4개에서 최상).
- 두 단계의 카운팅-언급 방법은 배치에서 라벨-언급 쌍의 병렬 디코딩을 가능하게 한다.
- 레이블 간의 최상위 확률 인스턴스를 선택해 중복 제거하면 재현율의 큰 손실 없이 정밀도가 향상된다.
- 이 방법은 많은 데이터셋에서 최첨단 방법과 경쟁력을 유지하며 특히 Weibo, Youku, ACE2005에서 뛰어나다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.