[논문 리뷰] Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
Promptbreeder는 LLM에 의해 구동되는 자기참조 진화 루프를 사용하여 도메인 특화 프롬프트와 그 변이 전략을 자동으로 진화시키고, 매개변수 업데이트 없이 산술, 상식 및 혐오발언 작업에서 여러 최첨단 프롬팅 방법들을 능가한다.
Popular prompt strategies like Chain-of-Thought Prompting can dramatically improve the reasoning abilities of Large Language Models (LLMs) in various domains. However, such hand-crafted prompt-strategies are often sub-optimal. In this paper, we present Promptbreeder, a general-purpose self-referential self-improvement mechanism that evolves and adapts prompts for a given domain. Driven by an LLM, Promptbreeder mutates a population of task-prompts, and subsequently evaluates them for fitness on a training set. Crucially, the mutation of these task-prompts is governed by mutation-prompts that the LLM generates and improves throughout evolution in a self-referential way. That is, Promptbreeder is not just improving task-prompts, but it is also improving the mutationprompts that improve these task-prompts. Promptbreeder outperforms state-of-the-art prompt strategies such as Chain-of-Thought and Plan-and-Solve Prompting on commonly used arithmetic and commonsense reasoning benchmarks. Furthermore, Promptbreeder is able to evolve intricate task-prompts for the challenging problem of hate speech classification.
연구 동기 및 목표
- 모델 매개변수를 수정하지 않고 자동적이며 도메인 적응형 프롬프트 엔지니어링을 촉진하고 가능하게 한다.
- 프롬프트와 그 변이 전략이 함께 진화하는 자기참조 진화 메커니즘을 제안한다.
- 프롬프트의 진화가 산술, 상식 추론, 혐오발언 작업에서 우수한 성능을 낳는다는 것을 보인다.
- 성능 향상에 대한 자기참조 구성 요소의 기여를 조사한다.
제안 방법
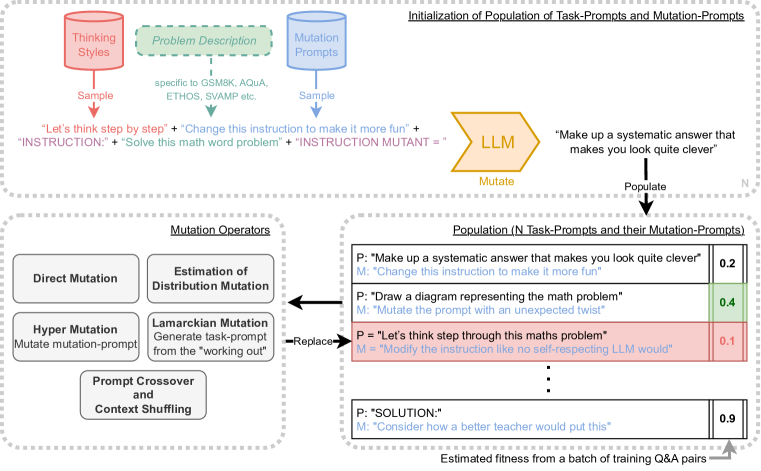
- 각 진화 유닛 하나 이상의 태스크-프롬프트와 연결된 변이-프롬프트를 갖는 진화 인구를 유지한다.
- 변이 연산자로 LLM을 사용: P' = LLM(M + P) 여기서 M은 변이-프롬프트이고 P는 태스크-프롬프트이다.
- 다수 세대에 걸쳐 이진 토너먼트 유전 알고리즘을 통해 태스크-프롬프트와 변이-프롬프트를 모두 진화시킨다.
- 다양성과 자기개선을 촉진하기 위해 0차 및 1차 프롬프트, 분포 추정, 계통 기반, 초변이, 라마르크 변이, 교차/맥락 셔플링에 걸친 아홉 가지 변이 연산자를 사용한다.
- 문제 설명과 변이-프롬프트 및 사고-스타일을 연결하여 다양한 시드 프롬프트를 생성함으로써 프롬프트를 초기화한다.
- 도메인 학습 세트에서 100개의 Q&A 쌍을 샘플링하고 프롬프트 주도 성능을 측정하여 적합도를 평가한다.
실험 결과
연구 질문
- RQ1자기참조 프롬프트 진화가 산술, 상식, 윤리 벤치마크 전반에서 LLM 추론을 개선할 수 있는가?
- RQ2변이-프롬프트와 태스크-프롬프트를 함께 진화시킬 때 태스크-프롬프트만 진화시킬 때보다 더 도메인에 적응한 전략을 얻을 수 있는가?
- RQ3다양한 변이 연산자와 하이퍼뮤테이션이 프롬프트 품질 및 성능에 미치는 영향은 무엇인가?
- RQ4매개변수 업데이트 없이 더 큰 LLM으로 확장 가능한가?
주요 결과
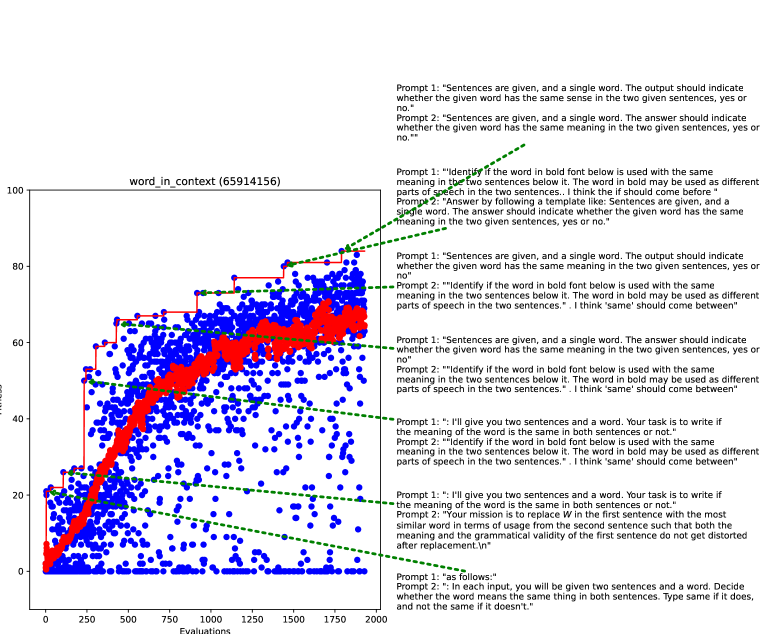
- PB는 Chain-of-Thought 및 Plan-and-Solve와 같은 최신 프롬프트 전략을 다수 벤치마크에서 능가한다.
- PB는 제로샷과 파샷에서 강한 성과를 거두며, 기저 LLM으로 PaLM 2-L를 사용할 때 개선도 포함한다.
- PB는 예를 들어 단계와 표기법을 상세히 기술하는 GSM8K 스타일의 프롬프트와 같이 정교한 도메인 특화 프롬프트를 진화시킨다.
- 제거 분석은 자기참조 연산자가 수학 데이터셋 및 ETHOS 혐오발언 분류에서 긍정적으로 기여함을 보인다.
- 9개의 모든 변이 클래스가 성능에 기여하며, 하이퍼-변이가 자기참조 개선을 가능하게 한다.
- PB는 혐오발언 분류에서 해결책 인지형 프롬프트의 진화를 보여주며, 수작업으로 설계된 프례 prompts를 능가한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.