[논문 리뷰] ProtChatGPT: Towards Understanding Proteins with Large Language Models
ProtChatGPT는 PLP-former와 다단계 어댑터를 통해 고정된 LLM에 단백질 서열 및 구조 임베딩을 정렬하는 ChatGPT 유사 시스템으로, 자연어 질의를 통한 인터랙티브한 단백질 이해 및 설계가 가능하게 한다.
Protein research is crucial in various fundamental disciplines, but understanding their intricate structure-function relationships remains challenging. Recent Large Language Models (LLMs) have made significant strides in comprehending task-specific knowledge, suggesting the potential for ChatGPT-like systems specialized in protein to facilitate basic research. In this work, we introduce ProtChatGPT, which aims at learning and understanding protein structures via natural languages. ProtChatGPT enables users to upload proteins, ask questions, and engage in interactive conversations to produce comprehensive answers. The system comprises protein encoders, a Protein-Language Pertaining Transformer (PLP-former), a projection adapter, and an LLM. The protein first undergoes protein encoders and PLP-former to produce protein embeddings, which are then projected by the adapter to conform with the LLM. The LLM finally combines user questions with projected embeddings to generate informative answers. Experiments show that ProtChatGPT can produce promising responses to proteins and their corresponding questions. We hope that ProtChatGPT could form the basis for further exploration and application in protein research. Code and our pre-trained model will be publicly available.
연구 동기 및 목표
- 단백질 데이터와 자연어 간의 모달리티 격차를 Q&A 및 설계 작업을 위해 해소한다.
- 사전 학습된 단백질 인코더와 LLM을 활용하여 전체 엔드투엔드 미세조정 없이 인터랙티브한 단백질 대화를 가능하게 한다.
- 단백질 표현을 텍스트 설명과 정렬하기 위한 두 단계 학습 구성(PLP-former 및 다단계 어댑터)을 도입한다.
- 단백질 이해 및 설계 작업에서 시스템을 시연하고 구성요소의 영향력을 분석한다.]
- methodACTUAL_PLACEHOLDER
- method
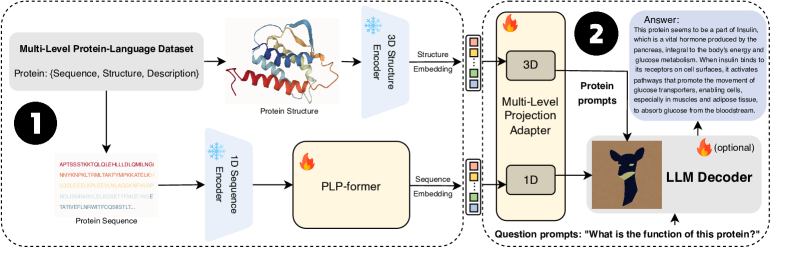
- [[Use two pre-trained protein encoders to obtain sequence and structure embeddings (ESM-1b for 1D sequences and ESM-IF1 for 3D structures).],[Introduce PLP-former to align protein embeddings with textual descriptions while keeping the LLM frozen.],[Develop a multi-level projection adapter to translate aligned protein embeddings into prompts compatible with the LLM.],[Fine-tune the PLP-former and adapter in a two-stage training regime using protein-description and protein-text generation objectives.],[Employ Vicuna-13b as the LLM decoder and concatenate protein prompts with user question prompts for generation.]]
- research_questions:[
제안 방법
- Use two pre-trained protein encoders to obtain sequence and structure embeddings (ESM-1b for 1D sequences and ESM-IF1 for 3D structures).
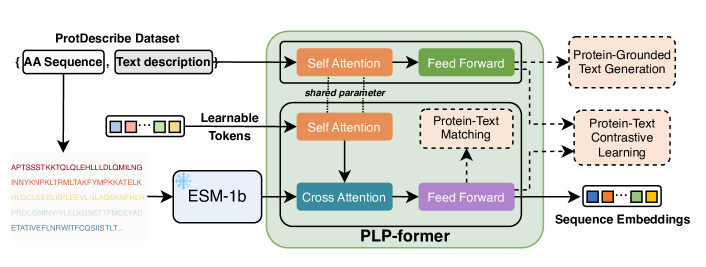
- Introduce PLP-former to align protein embeddings with textual descriptions while keeping the LLM frozen.
- Develop a multi-level projection adapter to translate aligned protein embeddings into prompts compatible with the LLM.
- Fine-tune the PLP-former and adapter in a two-stage training regime using protein-description and protein-text generation objectives.
- Employ Vicuna-13b as the LLM decoder and concatenate protein prompts with user question prompts for generation.
실험 결과
연구 질문
- RQ1Can a frozen LLM be effectively guided to answer protein-related questions using aligned multi-level protein embeddings?
- RQ2How do sequence-only versus sequence+structure encodings affect quality of protein-to-text alignment and generated explanations?
- RQ3What is the impact of the PLP-former and multi-level adapter on semantic quality of generated protein descriptions?
- RQ4Can ProtChatGPT support both understanding and design tasks for proteins through natural-language dialogue?
주요 결과
| Variant | BLEU-1 | BLEU-4 | ROUGE-L | METEOR | CIDEr | SPICE | PubMed BERTScore |
|---|---|---|---|---|---|---|---|
| w/o structure | 0.457 | 0.311 | 0.405 | 0.237 | 0.504 | 0.231 | 0.335 |
| w/o PLP-former | 0.581 | 0.352 | 0.463 | 0.270 | 0.572 | 0.276 | 0.421 |
| ProtChatGPT | 0.610 | 0.394 | 0.489 | 0.291 | 0.638 | 0.316 | 0.457 |
- ProtChatGPT는 구조나 PLP-former 구성요소가 없는 아블레이션보다 다수의 지표에서 더 높은 의미 평가 점수를 달성한다.
- 두 단계 학습(PLP-former와 어댑터)이 단백질 표현과 LLM을 효과적으로 정렬하여 정보적인 응답을 제공한다.
- 정성적 대화에서 ProtChatGPT가 단백질의 의미, 기능 및 응용을 논의할 수 있으며 설계 고려사항과 변이도 포함된다.
- 사례 연구는 상동 단백질의 차별화 및 맥락 프롬프트를 통한 상호 배타적 기능 처리 등을 입증한다.
- 1,000개의 테스트 단백질 쌍에 대한 정량적 테스트는 구조와 PLP-former의 중요성을 나타낸다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.