[논문 리뷰] Proto-CLIP: Vision-Language Prototypical Network for Few-Shot Learning
Proto-CLIP은 고정된 CLIP 백본에서 이미지 프로토타입과 텍스트 프로토타입을 결합하고, 어댑터와 메모리를 학습하여 이미지와 텍스트 프로토타입을 정렬해 적은 샷 분류를 개선한다.
We propose a novel framework for few-shot learning by leveraging large-scale vision-language models such as CLIP. Motivated by unimodal prototypical networks for few-shot learning, we introduce Proto-CLIP which utilizes image prototypes and text prototypes for few-shot learning. Specifically, Proto-CLIP adapts the image and text encoder embeddings from CLIP in a joint fashion using few-shot examples. The embeddings from the two encoders are used to compute the respective prototypes of image classes for classification. During adaptation, we propose aligning the image and text prototypes of the corresponding classes. Such alignment is beneficial for few-shot classification due to the reinforced contributions from both types of prototypes. Proto-CLIP has both training-free and fine-tuned variants. We demonstrate the effectiveness of our method by conducting experiments on benchmark datasets for few-shot learning, as well as in the real world for robot perception. The project page is available at https://irvlutd.github.io/Proto-CLIP
연구 동기 및 목표
- 로봇 공학과 일반 비전 과제에서 소수의 예제만으로 새로운 물체를 인식하기 위해 대형 비전-언어 모델(CLIP)을 활용하여 소샷 학습을 동기 부여한다.
- 적은 샷 데이터로 CLIP 인코더를 적응시키는 이미지-텍스트 공통 프로토타입 프레임워크를 제안한다.
- 각 클래스에 대해 이미지 프로토타입과 텍스트 프로토타입을 정렬하여 소샷 분류를 향상시킨다.
- 표준 소샷 벤치마크와 FewSOL에서 Proto-CLIP을 평가하고, 실제 로봇 인지 실험을 포함한다.
제안 방법
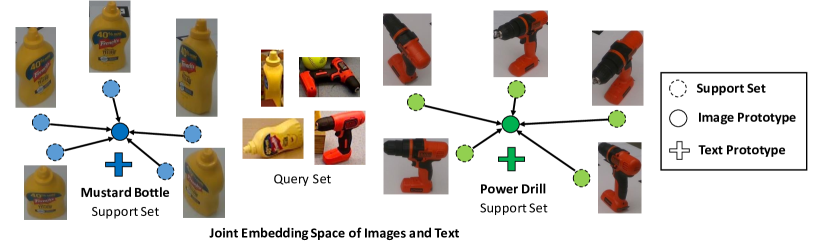
- 적응된 임베딩으로 계산된 이미지 프로토타입 c_k^x와 텍스트 프로토타입 c_k^y를 형성하기 위해 CLIP 이미지 인코더와 텍스트 인코더를 모두 사용한다.
- CLIP을 학습 가능한 이미지 메모리, 텍스트 메모리 및 쿼리 이미지에 적용되는 어댑터 네트워크를 통해 적응시키되, CLIP 인코더는 동결된 상태로 유지한다.
- 이미지 기반 예측과 텍스트 기반 예측의 볼록 결합으로 클래스 조건부 확률을 계산한다: P(y=k|x^q,S) = alpha P(y=k|x^q,S_x) + (1-alpha) P(y=k|x^q,S_y).
- 프로토타입은 임베딩의 평균으로 학습된다: c_k^x = (1/M_k) sum φ_Image(x_i^s) and c_k^y = (1/Ṁ_k) sum φ_Text(Prompt_j(y_i^s=k)).
- 결합 손실로 학습한다: 질의 분류에 대한 L1과 이미지/텍스트 프로토타입을 InfoNCE(대비) 손실로 정렬하기 위한 L2 및 L3.
- 학습 중 S(지원) 및 Q(질의) 세트는 일반적으로 CLIP 기반 소샷 방법과 동일하며, 이미지/텍스트 인코더는 동결되고 메모리와 어댑터만 학습된다.
실험 결과
연구 질문
- RQ1CLIP의 이미지와 텍스트 인코더를 공동으로 적응시키는 것이 단일 모드의 프로토타입 방법에 비해 소샷 분류를 개선할 수 있는가?
- RQ2InfoNCE 목적 하에 이미지 및 텍스트 프로토타입을 정렬하는 것이 소샷 설정에서 새로운 클래스의 인식을 향상시키는가?
- RQ3학습 가능한 이미지/텍스트 메모리와 다양한 어댑터 설계가 다양한 데이터셋에서 소샷 성능에 어떤 영향을 미치는가?
- RQ4Proto-CLIP에서 질의 데이터 증강과 메모리 기반 적응 간의 트레이드오프는 무엇인가?
주요 결과
- Proto-CLIP은 여러 데이터셋에서 제로샷 CLIP 및 여러 CLIP 기반의 소샷 기준선보다 지속적으로 성능을 향상시키며, 샷 수가 증가할수록 이득이 커진다.
- 대비 손실(L2, L3)을 통해 이미지 및 텍스트 프로토타입을 정렬하는 것이 성능에 이득을 주며, 공동 임베딩 가설을 확인한다.
- 학습 가능한 이미지/텍스트 메모리와 어댑터를 사용하면 CLIP 특징을 그대로 사용하는 것보다 더 나은 적응이 가능하며, 어댑터의 선택(MLP 대 합성곱)은 데이터셋에 따라 달라질 수 있다.
- 백본 선택(예: CLIP ViT 대 ResNet)이 결과에 영향을 미치며, 비전-언어 백본은 일반적으로 소샷 상황에서 더 강한 성능을 보인다.
- 학습 중 질의 증강(Q^T)을 적용하는 Proto-CLIP 변형은 비증강 버전보다 종종 더 높은 샷 설정에서 우수한 성능을 보인다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.