[논문 리뷰] RA-DIT: Retrieval-Augmented Dual Instruction Tuning
RA-DIT는 두 단계의 미세조정 프로세스를 통해 모든 사전학습된 LLM에 검색 기능을 보강합니다(검색 정보를 활용하기 위한 LM 미세조정과 관련 결과를 반환하기 위한 retriever 미세조정). 지식 의존적 작업에서 특히 제로샷 및 파샷 설정에서 최첨단 성과를 달성합니다.
Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
연구 동기 및 목표
- 전체 재훈련이나 사전 훈련 없이 LLM의 지식 활용도와 맥락 인식을 개선하도록 동기를 부여한다.
- 사전 학습된 모든 LLM과 retriever에 검색 기능을 재장착하기 위한 경량의 두 단계 미세조정 절차를 제안하여 어떤 사전학습된 LLM과 retriever에도 검색 기능을 재적용한다.
- LM-ft와 R-ft를 결합하면 지식 의존적 작업에서 가산 이득이 발생함을 보여준다.
- RA-DIT 65B가 제로샷 및 파샷 벤치마크 전반에서 최첨단 성능을 달성함을 보인다.
제안 방법
- 백본으로 사전 학습된 LLaMA 모델을 사용하고 Dense retriever로 Dragon+를 사용한다.
- 각 프롬프트에 대해 상위 k 개의 텍스트 청크를 검색하고 이를 Instruction의 Background 필드로 앞에 추가하여 청크 간의 병렬 앙상블을 가능하게 한다.
- LM fine-tuning (LM-ft): 확장된 background c i 및 지시 x를 사용하여 p(y|c i ∘ x)를 최대화하도록 LLM을 학습시켜 검색된 background를 활용하고 오해를 일으키는 내용을 무시하도록 모델을 유도한다.
- Retriever fine-tuning (R-ft): 쿼리 인코더를 학습시켜 pR(c|x)와 LM 가능도 pLM(y|c∘x)에 기반해 학습된 LM-감독 검색 분포 pLSR(c|x,y) 간의 KL 발산을 최소화하도록 한다.
- 합이 증가하도록 LM-ft와 R-ft를 결합하고, 미세조정 중에 보지 못한 지식 집중 작업에서 평가한다.

실험 결과
연구 질문
- RQ1경량의 이중 단계 미세조정으로 기존 LLM에 검색 기능을 추가하는 것이 전체 사전 학습 없이 가능한가?
- RQ2상이한 LM-ft 및 R-ft 단계가 가산 이득을 가져오는가, 결합될 때 어떤 상호작용이 있는가?
- RQ3RA-DIT가 제로샷 및 파샷 지식집약 벤치마크에서 일반 LLM+retriever 방식 및 지속적으로 사전학습된 RALMs와 비교해 어떤 성능을 보이는가?
주요 결과
- RA-DIT 65B는 제로샷 및 파샷 지식집약 벤치마크에서 최첨단 성과를 달성하고, MMLU, NQ, TQA, ELI5에서 0-shot에서 맥락 내 RALMs보다 평균적으로 최대 8.9포인트, 5-shot에서 최대 1.4포인트 앞서는 등 크게 우수한 성과를 보였다.
- RA-DIT은 8개 과제 중 6개에서 Atlas(64-shot 미세조정된 인코더-디코더 RALM)를 평균 4.1점 차이로 앞섰다.
- LM-ft와 R-ft 모두 이득에 기여하며, 최상의 결과는 두 가지를 결합했을 때 나왔다(5-shot에서 평균 약 0.8포인트 차이로 RA-DIT이 RePlug를 능가).
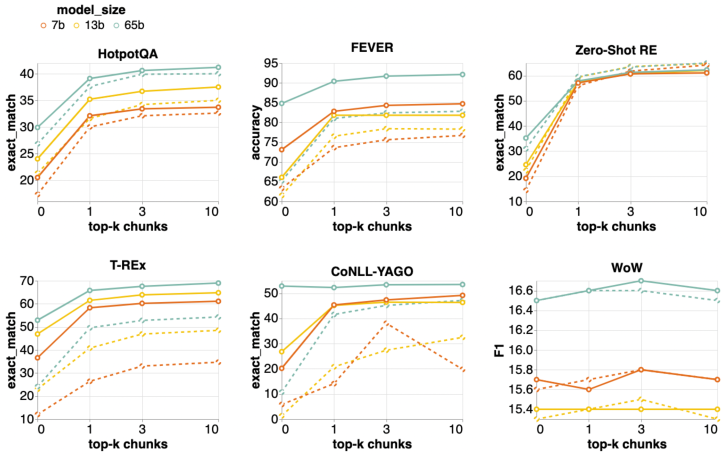
- 검색 보강은 65B 매개변수의 LLaMA에서도 단일 상위 1개 청크로 제한되더라도 향상을 보이며, 더 많은 청크를 사용할수록 추가 이득이 있다.
- 코퍼스 데이터를 사용한 retriever의 미세조정은 일반적으로 MTI 데이터만 사용하는 것보다 일반화가 더 잘되며, 문서 인코더를 고정하고 쿼리 인코더만 미세조정하는 것이 강한 결과를 낸다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.