[논문 리뷰] Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion은 환경 피드백을 기반으로 구두 반성을 생성하여 trial-and-error에서 학습하도록 언어 에이전트를 가능하게 하며, 에피소드 기억에 저장되어 향후 시도를 안내하고, 가중치 업데이트 없이 코딩, 추론, 의사결정 벤치마크에서 최첨단 성과를 달성합니다.
Large language models (LLMs) have been increasingly used to interact with external environments (e.g., games, compilers, APIs) as goal-driven agents. However, it remains challenging for these language agents to quickly and efficiently learn from trial-and-error as traditional reinforcement learning methods require extensive training samples and expensive model fine-tuning. We propose Reflexion, a novel framework to reinforce language agents not by updating weights, but instead through linguistic feedback. Concretely, Reflexion agents verbally reflect on task feedback signals, then maintain their own reflective text in an episodic memory buffer to induce better decision-making in subsequent trials. Reflexion is flexible enough to incorporate various types (scalar values or free-form language) and sources (external or internally simulated) of feedback signals, and obtains significant improvements over a baseline agent across diverse tasks (sequential decision-making, coding, language reasoning). For example, Reflexion achieves a 91% pass@1 accuracy on the HumanEval coding benchmark, surpassing the previous state-of-the-art GPT-4 that achieves 80%. We also conduct ablation and analysis studies using different feedback signals, feedback incorporation methods, and agent types, and provide insights into how they affect performance.
연구 동기 및 목표
- 전통적인 RL의 경량 대안을 제시하여 가중치 업데이트가 아닌 구두 피드백을 활용합니다.
- 자가 반성 및 에피소드 기억이 의사결정, 추론, 프로그래밍 작업에서 과제 수행을 향상시키는지 입증합니다.
- 새로운 LeetcodeHardGym 벤치마크를 포함하여 다양한 환경과 언어에서 확장성을 입증합니다.
- 피드백 타입과 기억이 성능에 미치는 영향을 이해하기 위한 차등 분석을 제공합니다.
제안 방법
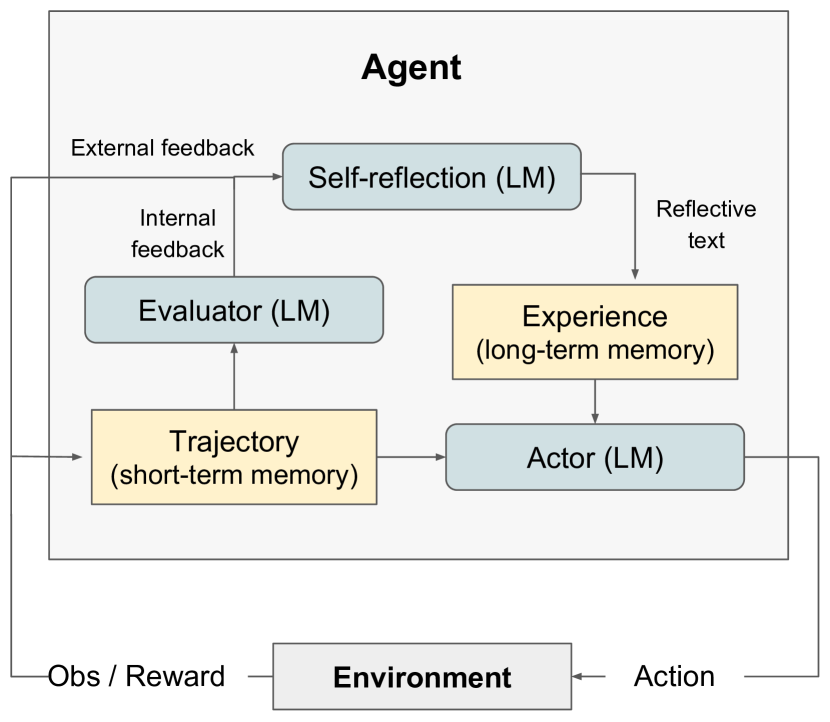
- 세 가지 모델로 구성된 모듈식 Reflexion 프레임워크를 제안합니다: Actor(텍스트와 행동을 생성하는 LLM 기반 생성기), Evaluator(Actor 출력의 점수 매기기), Self-Reflection(메모리를 보강하는 구두 피드백 생성기).
- 환경 피드백을 구두 반성으로 변환하고 이를 메모리 버퍼에 저장하여 미래 에피소드를 영향합니다.
- 단기(trajectory) 메모리와 장기(자기 반성) 메모리를 사용하여 Actor의 의사를 조건화합니다.
- 다양한 피드백 신호(이진, 휴리스틱, 자기 평가) 및 다양한 작업 유형(의사결정, 추론, 프로그래밍)을 실험합니다.
- Reflexion 알고리즘은 각 시도가 궤적, Evaluator 점수, 그리고 이후 시도를 위한 메모리에 추가되는 자기 반성을 생성하는 반복 루프로 기술됩니다.

실험 결과
연구 질문
- RQ1구두 자기 반성과 에피소드 기억이 그래디언트 기반 미세조정 없이도 LLM 기반 에이전트가 드물고 시도-오류 피드백에서 학습할 수 있게 합니까?
- RQ2다양한 피드백 신호와 기억 구성은 의사결정, 추론, 프로그래밍 작업에서 성능에 어떤 영향을 줍니까?
- RQ3기존 벤치마크와 새로운 코드 생성 환경에서 Reflexion의 이점은 무엇입니까?
- RQ4프로그래밍 작업에서 언어와 도구 사용에 대해 Reflexion이 로버스트하게 작동합니까?
주요 결과
| 벤치마크 + 언어 | Prev SOTA Pass@1 | SOTA Pass@1 | Reflexion Pass@1 |
|---|---|---|---|
| HumanEval (PY) | 65.8 (CodeT+GPT-3.5) | 80.1 (GPT-4) | 91.0 |
| HumanEval (RS) | – | 60.0 (GPT-4) | 68.0 |
| MBPP (PY) | 67.7 (CodeT+Codex) | 80.1 (GPT-4) | 77.1 |
| MBPP (RS) | – | 70.9 (GPT-4) | 75.4 |
| Leetcode Hard (PY) | – | – | 15.0 |
- Reflexion은 의사결정, 추론 및 프로그래밍 작업에서 강력한 기준선과 비교하여 성능을 향상시킵니다.
- AlfWorld 의사결정에서 간단한 휴리스틱 자기 평가를 가진 Reflexion은 상당한 이점을 달성하고 12회의 시도에서 거의 완벽에 근접한 성능에 도달합니다.
- HotPotQA 추론 태스크에서 Reflexion은 기준선보다 현저히 우수한 성능을 보이며 CoT 및 ReAct 변형 대비 큰 이점을 보여줍니다.
- HumanEval 프로그래밍(Python 및 Rust)에서 Reflexion은 SOTA에 준하는 합격율을 달성하며, 특히 Python HumanEval에서 GPT-4를 사용해 91.0으로 사상의 SOTA를 상회합니다.
- LeetcodeHardGym은 자기 생성 유닛 테스트 접근법으로 어려운 코딩 문제를 처리하는 Reflexion의 능력을 보여주며 강한 pass@1 결과를 달성합니다.
- 차등 분석은 자기 반성과 기억의 중요성을 보여주며, 어느 한 구성요소를 제거하면 성능이 하락합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.