[논문 리뷰] Relating the Partial Dependence Plot and Permutation Feature Importance to the Data Generating Process
이 논문은 Partial Dependence(PD)와 Permutation Feature Importance(PFI)를 ground truth DGP 속성의 추정기로 formalize하고, 모델 학습 분산을 고려한 분산 및 신뢰구간 방법을 개발한다. 또한 모델 재적합에서의 불확실성을 포착하기 위해 learner-PD와 learner-PFI를 도입한다.
Scientists and practitioners increasingly rely on machine learning to model data and draw conclusions. Compared to statistical modeling approaches, machine learning makes fewer explicit assumptions about data structures, such as linearity. However, their model parameters usually cannot be easily related to the data generating process. To learn about the modeled relationships, partial dependence (PD) plots and permutation feature importance (PFI) are often used as interpretation methods. However, PD and PFI lack a theory that relates them to the data generating process. We formalize PD and PFI as statistical estimators of ground truth estimands rooted in the data generating process. We show that PD and PFI estimates deviate from this ground truth due to statistical biases, model variance and Monte Carlo approximation errors. To account for model variance in PD and PFI estimation, we propose the learner-PD and the learner-PFI based on model refits, and propose corrected variance and confidence interval estimators.
연구 동기 및 목표
- 모델 해석 도구를 데이터 생성 프로세스(DGP)와 연결할 필요성에 대한 동기 부여.
- PD와 PFI를 ground truth DGP 속성(DGP-PD, DGP-PFI)의 추정기로 Formalize.
- PD/PFI 오차를 편향, 분산(모델 및 몬테 카를로)으로 분해하고 분산 보정 방법 제안.
- 학습 과정 분산을 고려하기 위해 모델-PD/PFI와 학습자-PD/학습자-PFI를 구분.
- PD/PFI에 대해 수정된 분산 추정치와 신뢰구간을 포함한 추론 도구 제공.
제안 방법
- DGP-PD 및 DGP-PFI를 DGP의 실제 함수 f에 적용된 ground truth PD/PFI로 정의.
- PD 및 PFI를 편향, 모델 분산, 몬테카를로 오차를 포함하는 추정치로 표현하고 편향-분산 분해를 도출.
- 고정 모델인 모델-PD/모델-PFI와 모델 재적합에서 평균화한 학습자-PD/학습자-PFI를 추론 대상으로 도입.
- 모델-PD 및 모델-PFI에 대한 분산 추정치를 도출하고 점별 신뢰구간을 구성.
- Nadeau-Bengio 유형 보정으로 학습 과정의 불확실성을 더 잘 반영하기 위한 학습자-PD/학습자-PFI의 분산 보정 제안.
- 데이터 분할과 다중 재적합을 이용해 학습자-PD/학습자-PFI를 계산하는 방법 논의.
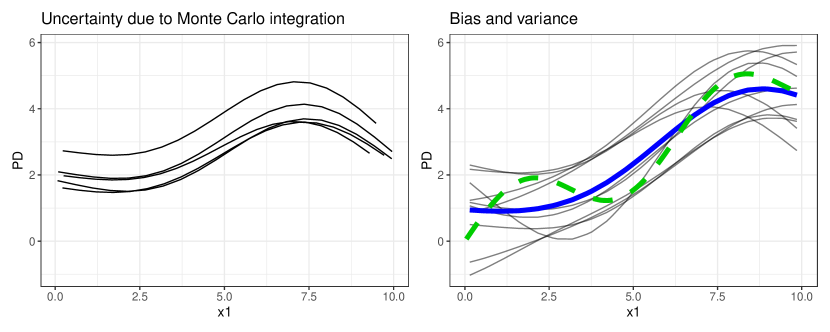
실험 결과
연구 질문
- RQ1PD와 PFI를 ground truth estimands(DGP-PD, DGP-PFI)로 통해 데이터 생성 프로세스와 어떻게 연결할 수 있는가?
- RQ2바이어스, 모델 분산, 몬테카를로 오차가 PD/PFI 추정치에 어떤 영향을 미치고 이를 어떻게 정량화할 수 있는가?
- RQ3고정된 모델(model-PD/PFI) 하에서 및 모델 재적합 하에서 PD/PFI에 대한 적절한 분산 추정치와 신뢰구간은 무엇인가?
- RQ4학습자-PD/학습자-PFI를 도입해 모델 분산을 반영하면 실제 해석과 불확실성 정량에 어떤 변화가 생기는가?
- RQ5재샘플링(resampling)을 이용해 다수의 모델 적합을 생성할 때 분산 추정을 개선하는 보정은 무엇인가?
주요 결과
- PD와 PFI는 ground-truth DGP의 양(DGP-PD, DGP-PFI)의 추정기로 취급될 수 있다.
- PD/PFI 추정은 바이어스와 두 가지 분산 원천을 포함한다: 모델 분산과 몬테카를로(MC) 분산.
- Model-PD/Model-PFI는 MC 분산만을 정량화하고 학습 과정 분산을 무시하므로 DGP에 대한 추론이 제한적이다.
- Learner-PD/Learner-PFI는 다수의 모델 재적합에서 평균화하고 전체 학습 과정 불확실성을 포착해 DGP에 대한 추론을 개선한다.
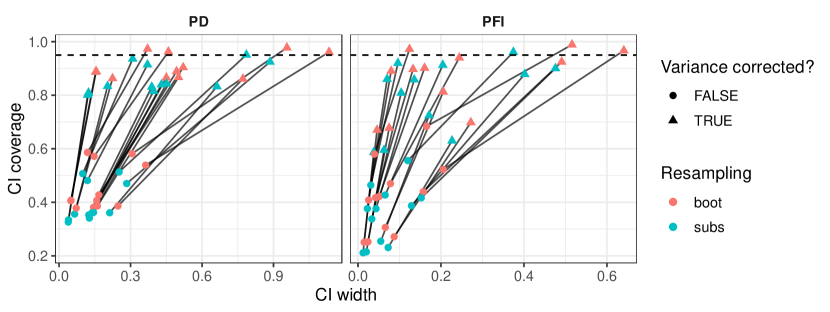
- Learner-PD/PFI의 분산 추정에는 재샘플링 사용 시 과소 추정 문제를 보정하는 항을 포함한다.
- Learner-PD/PFI에 대한 신뢰구간은 자유도와 함께 t-분포를 사용해 구성된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.