[논문 리뷰] RemoteCLIP: A Vision Language Foundation Model for Remote Sensing
RemoteCLIP은 원격 sensing을 위한 비전-언어 기초 모델로, Box-to-Caption 및 Mask-to-Box 변환으로 데이터 확장을 통해 이미지-텍스트 표현을 정렬하고 다양한 데이터셋에서 제로샷 및 검색 작업을 가능하게 한다.
General-purpose foundation models have led to recent breakthroughs in artificial intelligence. In remote sensing, self-supervised learning (SSL) and Masked Image Modeling (MIM) have been adopted to build foundation models. However, these models primarily learn low-level features and require annotated data for fine-tuning. Moreover, they are inapplicable for retrieval and zero-shot applications due to the lack of language understanding. To address these limitations, we propose RemoteCLIP, the first vision-language foundation model for remote sensing that aims to learn robust visual features with rich semantics and aligned text embeddings for seamless downstream application. To address the scarcity of pre-training data, we leverage data scaling which converts heterogeneous annotations into a unified image-caption data format based on Box-to-Caption (B2C) and Mask-to-Box (M2B) conversion. By further incorporating UAV imagery, we produce a 12 $ imes$ larger pretraining dataset than the combination of all available datasets. RemoteCLIP can be applied to a variety of downstream tasks, including zero-shot image classification, linear probing, $ extit{k}$-NN classification, few-shot classification, image-text retrieval, and object counting in remote sensing images. Evaluation on 16 datasets, including a newly introduced RemoteCount benchmark to test the object counting ability, shows that RemoteCLIP consistently outperforms baseline foundation models across different model scales. Impressively, RemoteCLIP beats the state-of-the-art method by 9.14% mean recall on the RSITMD dataset and 8.92% on the RSICD dataset. For zero-shot classification, our RemoteCLIP outperforms the CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets. Project website: https://github.com/ChenDelong1999/RemoteCLIP
연구 동기 및 목표
- 원격 탐색에서 비전-언어 모델의 사전 학습 데이터 부족 문제를 해결한다.
- 다운스트림 tasks를 위한 풍부한 의미론과 정렬된 텍스트 임베딩으로 견고한 시각적 특징을 학습한다.
- 단일 이미지-캡션 데이터 포맷으로 제로샷, 소수샷 및 검색 기반 응용 프로그램을 원격 탐지에서 가능하게 한다.
- 대규모 사전 학습을 위해 이질적 주석을 활용하는 데이터 확장 기술을 입증한다.
제안 방법
- InfoNCE 손실을 최적화하기 위해 이미지 인코더와 텍스트 인코더를 사용하는 CLIP 스타일 대조학습(pretraining)을 수행한다.
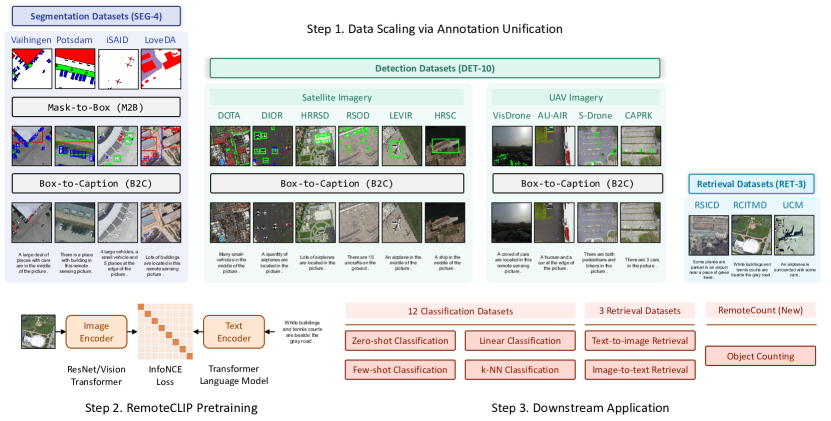
- Box-to-Caption(B2C) 생성과 Mask-to-Box(M2B) 변환을 통해 이질적 원격 탐색 주석을 이미지-텍스트 쌍으로 통일한다.
- DET-10, SEG-4, RET-3, 및 UAV 영상 데이터를 포함하여 합쳐진 오픈 데이터셋의 12배로 사전 학습 데이터를 확장한다.
- 16개 다운스트림 데이터셋에서 제로샷, 선형 탐색, k-NN, 소수샷 및 이미지-텍스트 검색 작업에 걸쳐 RemoteCLIP를 평가한다.
- 다수의 백본 크기(ResNet-50, ViT-Base-32, ViT-Large-14) 지원하여 모델 및 데이터 규모 효과를 보여준다.
- 원격 탐지에서 객체 카운팅을 위한 새로운 RemoteCount 벤치마크를 제공한다.
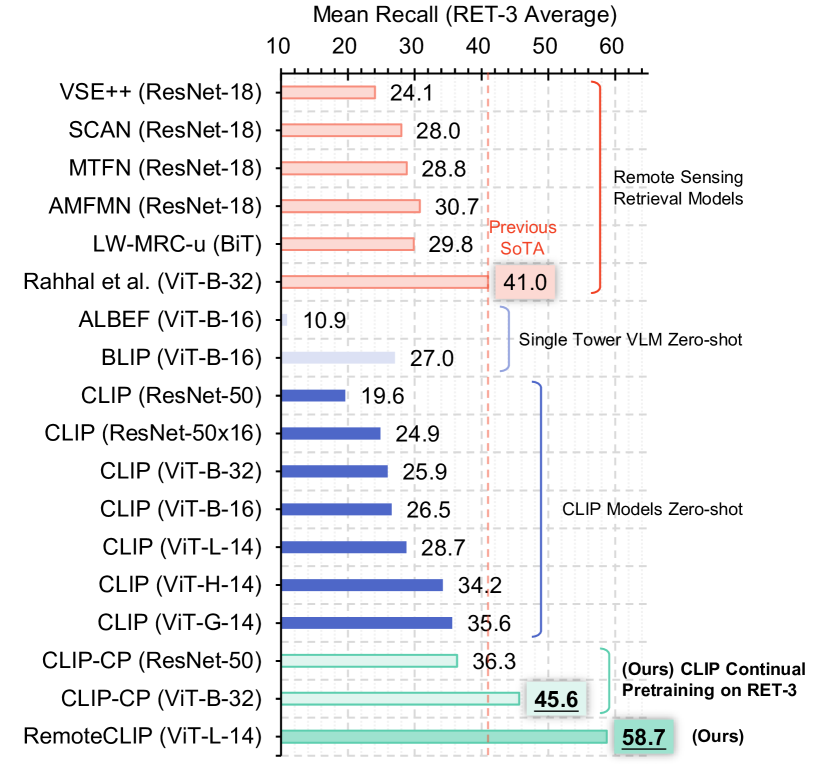
실험 결과
연구 질문
- RQ1대규모 통합 원격 탐지 이미지-캡션 데이터로 학습된 비전-언어 기초 모델이 다양한 다운스트림 작업에서 도메인 특화 기준을 능가할 수 있는가?
- RQ2주석의 통일(B2C 및 M2B)을 통한 데이터 확성이 더 강한 의미 정렬과 제로샷/소수샷 성능을 원격 탐지에서 열어주는가?
- RQ3서로 다른 백본 크기가 원격 탐지의 분류 및 검색 작업에서 RemoteCLIP의 성능에 어떤 영향을 미치는가?
- RQ4도메인 내 데이터에 대한 지속적 사전학습이 CLIP 기반 모델에 도움이 되는가?
- RQ5하나의 모델이 위성 및 UAV 등 여러 원격 탐지 모달리티 및 작업(카운팅, 검색, 분류)을 강하게 수행할 수 있는가?
주요 결과
- RemoteCLIP의 제로샷 분류 성능은 12개 다운스트림 데이터셋에서 CLIP 베이스라인보다 평균 정확도 최대 6.39% 향상이다.
- 지속적 사전학습(CLIP-CP)은 검색 벤치마크를 크게 향상시키며 RSITMD, RSICD, UCM에서 새로운 최첨단을 확립한다.
- RET-3/SEG-4/DET-10+ 데이터셋의 12배 규모로 데이터 확장은 작은 규모의 지속적 사전학습에 비해 상당한 이점을 제공한다.
- RemoteCLIP는 ResNet-50에서 ViT-Large-14에 이르는 16개 원격 탐지 데이터셋에서 작업 및 모델 규모 전반에서 베이스라인 기초 모델を 능가한다.
- RSITMD 및 RSICD의 이득은 각각 관련 베이스라인 대비 평균 리콜 9.14% 및 8.92%의 개선을 포함한다.
- 제로샷, 선형 탐색, k-NN, 소수샷 분류 및 이미지-텍스트 검색에서 모델의 다재다능함을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.