[논문 리뷰] Resurrecting Recurrent Neural Networks for Long Sequences
본 논문은 Linear Recurrent Units (LRUs)를 갖춘 심층 RNN 아키텍처가 세밀한 선형화, 대각화, 안정적 초기화, 그리고 정규화를 통해 Long Range Arena와 같은 장거리 시퀀스 작업에서 심층 상태공간 모델과 대등하게 작동하면서도 학습 효율성을 유지할 수 있음을 시사한다.
Recurrent Neural Networks (RNNs) offer fast inference on long sequences but are hard to optimize and slow to train. Deep state-space models (SSMs) have recently been shown to perform remarkably well on long sequence modeling tasks, and have the added benefits of fast parallelizable training and RNN-like fast inference. However, while SSMs are superficially similar to RNNs, there are important differences that make it unclear where their performance boost over RNNs comes from. In this paper, we show that careful design of deep RNNs using standard signal propagation arguments can recover the impressive performance of deep SSMs on long-range reasoning tasks, while also matching their training speed. To achieve this, we analyze and ablate a series of changes to standard RNNs including linearizing and diagonalizing the recurrence, using better parameterizations and initializations, and ensuring proper normalization of the forward pass. Our results provide new insights on the origins of the impressive performance of deep SSMs, while also introducing an RNN block called the Linear Recurrent Unit that matches both their performance on the Long Range Arena benchmark and their computational efficiency.
연구 동기 및 목표
- Transformer와 SSM이 강점을 보인 장거리 시퀀싱에 RNN을 활용하는 연구를 자극한다.
- 깊은 RNN이 장거리 작업에서 깊은 SSM과 대등한 성능을 낼 수 있는지 식별한다.
- RNN에서 장거리 추론에 영향을 미치는 아키텍처 및 초기화 선택을 격리하고 제거한다.
- 장거리 시퀀스에서 경쟁력 있는 성능과 효율성을 달성하는 원리적이고 확장 가능한 RNN 설계(LRU)를 제공한다.
제안 방법
- vanilla RNN과 Long Range Arena 벤치마크에서 SSM들(S4 등)과의 비교를 수행한다.
- S4와 같은 SSM 레이어를 선형 RNN 레이어로 교체하고 비선형 MLP 블록을 쌓아 Linear Recurrent Unit (LRU)을 구성한다.
- recurrence의 비선형성을 제거하는 것이 깊은 구조에서 성능을 향상시킬 수 있음을 시연한다.
- 학습이 긴 기간에 걸쳐 안정적으로 이루어지도록 학습가능 매개변수의 모수화를 가능하게 하는 복소 대각 선형 행렬 및 지수 매개화를 도입한다.
- 초길이 작업에서 학습을 안정시키기 위해 은닉 활성의 정규화를 적용한다.
- 대각화, 초기화 스펙트럼, 정규화가 작업 성능에 미치는 영향을 보여주는 ablation을 제공한다.
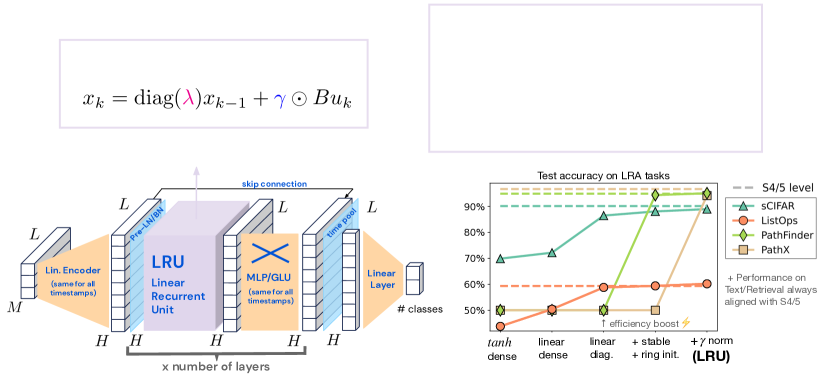
실험 결과
연구 질문
- RQ1깊은 RNN이 긴 거리 추론 작업에서 깊은 연속시간 SSM의 성능을 따라잡을 수 있는가?
- RQ2RNN으로 SSM과 같은 성능을 달성하기 위해 필요한 건 architectural 및 초기화 변화인가?
- RQ3적절한 대각화 및 정규화가 선형 반복에서 긴 시퀀스의 효율적 학습을 가능하게 하는가?
- RQ4고유값 안정화 전략이 LRUs의 장거리 의존성 학습에 어떤 영향을 미치는가?
주요 결과
- 깊은 비선형성이 없는 깊은 선형 반복은 여러 Long Range Arena 작업에서 비선형 RNN 변형보다 우수한 성능을 보일 수 있다.
- 복소수로 구성된 대각 행렬로 반복을 대각화하면 학습 속도가 빨라지고 LRA 작업에서 S4/S5의 성능을 맞출 수 있다.
- 대각 스펙트럼의 지수 매개화는 안정적인 학습을 가능하게 하고 특히 Pathfinder와 같은 더 어려운 작업에서 장거리 추론을 개선한다.
- Forward 패스 중 은닉 활성의 정규화는 장거리 작업에서 딥 SSM과의 차이를 좁히는 데 결정적이다.
- 단위 원판 근처의 스펙트럼으로 초기화하고 정규화를 적용하면 LRUs가 LRA 벤치마크에서 깊은 SSM과 경쟁력 있는 성능을 얻는다.
![Figure 4: Evolution of $x\in\mathbb{R}^{3}$ under impulse input $u=(1,0,0,\dots,0)\in\mathbb{R}^{16k}$ . Plotted in different colors are the 3 components of $x$ . $\Lambda$ has parameters $\nu_{j}=0.00005$ and $\theta_{j}$ sampled uniformly in $[0,2\pi]$ or with small phase $[0,\pi/50]$ . For small](https://ar5iv.labs.arxiv.org/html/2303.06349/assets/x6.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.