[논문 리뷰] Rethinking the Role of Token Retrieval in Multi-Vector Retrieval
XTR은 다중 벡터 검색에서 토큰 검색의 관점을 재정의하여 검색된 토큰만으로 문서를 직접 점수화하고 수집 단계를 제거하며 점수 계산 비용을 크게 줄이는 한편 BEIR/LoTTE에서 최첨단 성능과 강력한 MS MARCO 성능을 달성합니다.
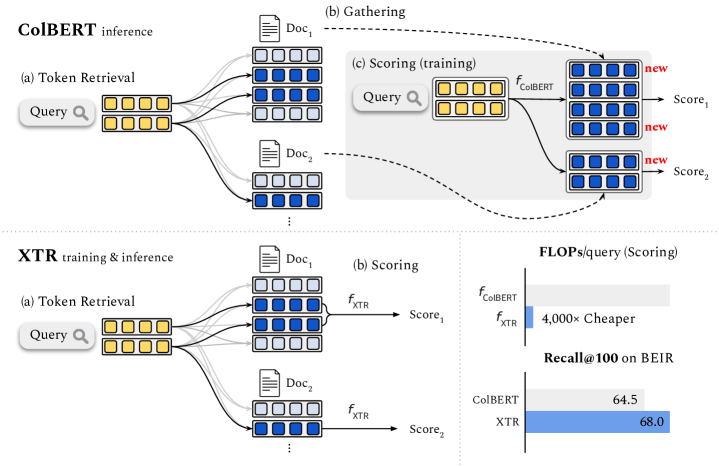
Multi-vector retrieval models such as ColBERT [Khattab and Zaharia, 2020] allow token-level interactions between queries and documents, and hence achieve state of the art on many information retrieval benchmarks. However, their non-linear scoring function cannot be scaled to millions of documents, necessitating a three-stage process for inference: retrieving initial candidates via token retrieval, accessing all token vectors, and scoring the initial candidate documents. The non-linear scoring function is applied over all token vectors of each candidate document, making the inference process complicated and slow. In this paper, we aim to simplify the multi-vector retrieval by rethinking the role of token retrieval. We present XTR, ConteXtualized Token Retriever, which introduces a simple, yet novel, objective function that encourages the model to retrieve the most important document tokens first. The improvement to token retrieval allows XTR to rank candidates only using the retrieved tokens rather than all tokens in the document, and enables a newly designed scoring stage that is two-to-three orders of magnitude cheaper than that of ColBERT. On the popular BEIR benchmark, XTR advances the state-of-the-art by 2.8 nDCG@10 without any distillation. Detailed analysis confirms our decision to revisit the token retrieval stage, as XTR demonstrates much better recall of the token retrieval stage compared to ColBERT.
연구 동기 및 목표
- 전통적인 세 단계 멀티 벡터 검색 파이프라인(토큰 검색, 수집, 점수화)의 단순화를 촉진한다.
- 먼저 중요한 문서 토큰의 검색을 촉진하는 학습 목표를 제안한다.
- 검색된 토큰에 대해 작동하고 누락 토큰 임퓨테이션을 지원하여 전체 문서 점수를 근사하는 점수화 메커니즘을 개발한다.
- 증류나 하드 네거티브 마이닝 없이 BEIR 및 LoTTE에서 제로샷 IR의 최첨단 성능을 입증한다.
- ColBERT에 비해 점수 계산 계산량을 크게 줄이면서도 도메인 내 성능을 유지한다.
제안 방법
- XTR을 도입하고, 배치 내 정렬(batch alignment)에서 A_ij=1은 질의 토큰 i에 대해 d_j가 배치 내 상위 k_train 안에서 검색될 때만 설정되는 새로운 배치 내 정렬 전략을 가진 맥락화된 토큰 검색기.
- f_XTR(Q,D) 정의: (1/Z) Σ_i max_j A_ij q_i^T d_j, 여기서 Z는 하나 이상의 문서 토큰을 검색한 질의 토큰의 수(정규화자).
- 추론 시, 검색된 토큰만 사용하여 문서를 점수화하고 수집 단계를 제거하며, 효율성을 위해 검색 점수를 재사용한다.
- 비검색 토큰의 점수를 추정하기 위한 f_XTR'의 누락 유사도 임퓨테이션을 도입하여 top-k' 검색 점수에 기초한 상한을 제공한다.
- 관련 문서의 토큰이 더 자주 검색되도록 XTR 점수 함수를 사용하되 표준 교차 엔트로피 손실로 학습한다.
- 마지막으로 검색된 토큰 점수를 이용해 누락된 유사도에 대한 상한 임퓨테이션 m_i를 제공하여 점수화를 강화한다.
실험 결과
연구 질문
- RQ1토큰 검색만으로 다중 벡터 검색에서 경쟁력 있는 또는 더 우수한 문서 순위를 얻을 수 있는가?
- RQ2효과적인 다운스트림 점수를 위해 토큰 검색을 어떻게 학습시켜 중요한 문서 토큰의 우선순위를 정할 것인가?
- RQ3점수화 단계를 검색된 토큰과 누락 유사도 임퓨테이션에만 의존해 한 차원 이상으로 더 저렴하게 만들 수 있는가?
- RQ4제안된 학습 목표와 누락 유사도 임퓨테이션이 제로샷 벤치마크(BEIR/LoTTE)에 이익을 주는가?
- RQ5증류나 추가 사전 학습 없이 XTR이 다국어 검색 작업에 미치는 영향은 무엇인가?
주요 결과
- XTR은 증류나 하드 네거티브 마이닝 없이 BEIR에서 제로샷 설정으로 최첨단 성능을 달성한다.
- XTR은 검색된 토큰에 의존하고 수집 단계를 제거함으로써 점수 계산 계산량을 ColBERT 대비 최대 수십 배까지 크게 줄인다.
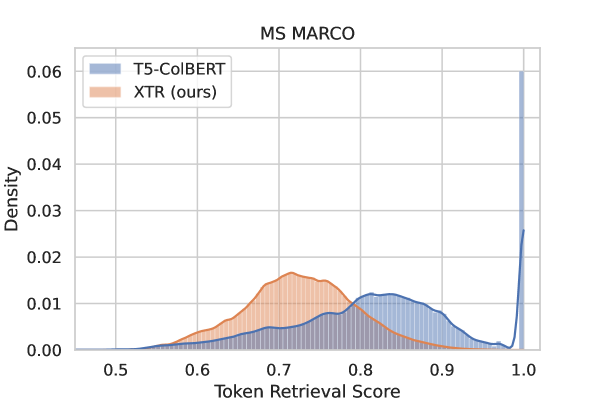
- 배치 내 토큰 검색 objective로 학습하면 상위-k 검색 토큰에서 골드 토큰의 재현율이 크게 향상된다.
- XTR은 ColBERT에 비해 맥락적 토큰 검색이 우수하여 골드 토큰 검색 확률과 맥락 매칭이 향상된다.
- 다국어 XTR(mXTR)은 MIRACL에서 대조학습 사전학습 기반선(mContriever 등)보다 우수하여 추가 사전학습 없이도 강력한 다국어 검색을 보여준다.
- 임퓨테이션 기반 점수화(XTR')은 추가 계산을 더 줄이면서도 경쟁력 있는 결과를 달성할 수 있으며 k'가 커질수록 재현율이 향상된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.