[논문 리뷰] Revisiting Feature Prediction for Learning Visual Representations from Video
이 논문은 2M 비디오에서 특징 예측 목표만으로 사전 학습된 V-JEPA 계열 비전 모델을 소개하며, 고정된 백본과 더 짧은 사전 학습으로 강력한 모션 및 외관 표현을 달성합니다.
This paper explores feature prediction as a stand-alone objective for unsupervised learning from video and introduces V-JEPA, a collection of vision models trained solely using a feature prediction objective, without the use of pretrained image encoders, text, negative examples, reconstruction, or other sources of supervision. The models are trained on 2 million videos collected from public datasets and are evaluated on downstream image and video tasks. Our results show that learning by predicting video features leads to versatile visual representations that perform well on both motion and appearance-based tasks, without adaption of the model's parameters; e.g., using a frozen backbone. Our largest model, a ViT-H/16 trained only on videos, obtains 81.9% on Kinetics-400, 72.2% on Something-Something-v2, and 77.9% on ImageNet1K.
연구 동기 및 목표
- 단독 특징 예측 목표를 사용하여 비디오에서 감독 없는 시각 표현 학습의 동기를 부여한다.
- 사전 학습된 인코더나 픽셀 재구성 없이 소스 표현으로 대상 표현을 예측하는 JEPA 기반 프레임워크를 개발한다.
- 고정(frozen) 및 미세 조정(fine-tuning) 설정에서 특징 예측 사전 학습이 다운스트림 이미지 및 비디오 작업으로 얼마나 transferring 되는지 평가한다.
- 비디오 기반 표현 학습의 성능에 영향을 미치는 마스킹, 데이터 분포, 풀링 등의 설계 선택을 분석한다.
제안 방법
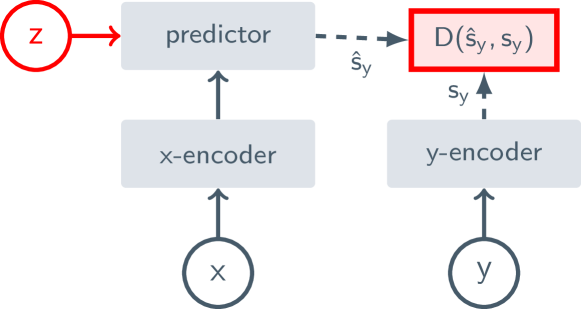
- 비디오 입력 내에서 x로부터 y를 예측하여 학습하기 위해 결합 임베딩 예측 아키텍처(JEPA)를 채택한다.
- x가 비디오의 마스킹된 부분집합이고 y가 보완 대상인 마스크된 특징 예측 작업을 사용하며, L1 손실과 stop-gradient/EMA 붕괴 방지로 학습한다.
- x와 y를 ViT 기반 인코더와 마스킹된 토큰 시퀀스에서 학습 가능한 마스크 토큰으로 작동하는 가벼운 예측기로 표현한다.
- 대규모 연속 시공간 영역을 마스킹하는 다중 블록 마스킹 전략을 사용하여 도전적인 예측 작업을 만든다.
- 주목 기반 프로빙, 적응형 풀링, 엔드-투-엔드 미세 조정을 통해 고정 및 미세 조정 성능을 평가한다.
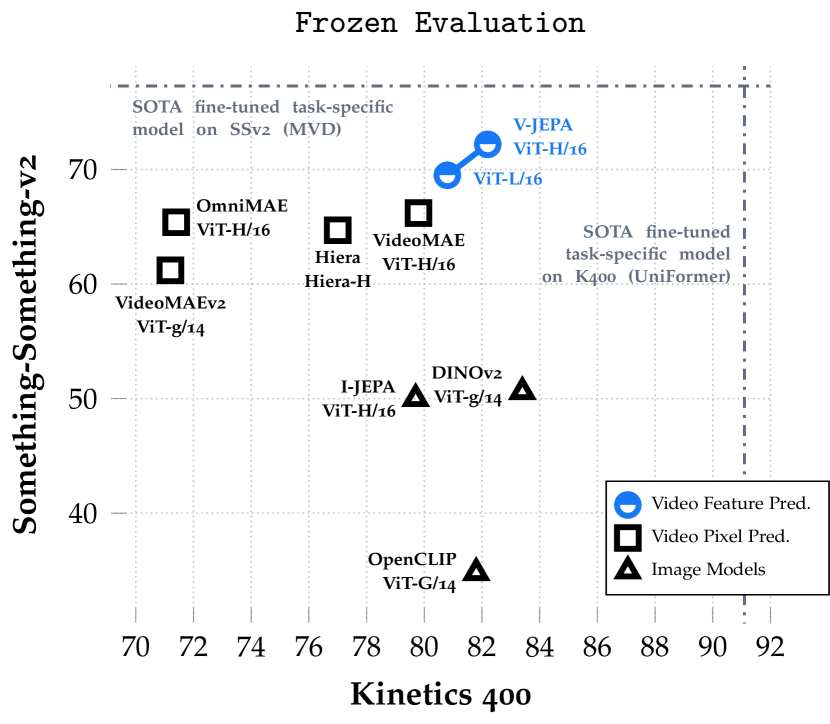
실험 결과
연구 질문
- RQ1독립적인 목표로서 특징 예측이 비디오에서 시각 표현의 감독 없는 학습에 얼마나 효과적인가?
- RQ2비디오 기반 특징 예측이 모델 가중치를 바꾸지 않고도 모션 기반과 외관 기반 다운스트림 작업으로 잘 전달되는 표현을 생성할 수 있는가?
- RQ3어떤 설계 선택(마스킹 전략, 데이터 혼합, 풀링)이 비디오로부터 학습된 표현의 품질에 가장 큰 영향을 미치는가?
주요 결과
- V-JEPA의 특징 예측은 고정된 백본을 사용하여 모션 기반 작업(Something-Something-v2)과 외관 기반 작업(Kinetics-400)에서 잘 수행하는 다재다능한 표현을 제공합니다.
- 고정 평가에서 픽셀 예측 기준선보다 특징 예측 사전 학습이 우수하고, 미세 조정에서도 경쟁력 있으며 더 짧은 사전 학습 일정과 함께합니다.
- 교차 주의를 이용한 적응형 풀링은 단순 평균 풀링에 비해 다운스트림 성능을 크게 향상시키며(K400 및 SSv2에서 특히),
- 사전 학습 데이터 크기를 늘리면 평균 다운스트림 성능이 향상되며, 작업에 특화된 데이터 혼합으로 작업별 최적 결과를 얻을 수 있다(일반적으로 VideoMix2M이 최상의 평균치를 제공).
- V-JEPA는 표적 데이터가 적은 상황에서 픽셀 예측 기준선 대비 큰 차이를 보이며 라벨 효율성을 입증한다.
- 픽셀 예측 비디오 모델과 비교하여, V-JEPA는 더 적은 사전 학습 샘플과 더 적은 계산으로 경쟁력 있거나 더 우수한 성능을 달성한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.