[논문 리뷰] Reward Design with Language Models
본 논문은 자연어 프롬프트로 RL 에이전트를 학습하기 위해 대형 언어 모델을 프록시 보상 함수로 사용하는 것을 제안하고, 사용자 목표를 소샷(few-shot) 또는 제로샷(zero-shot)으로 명시할 수 있게 하며, Ultimatum Game, Matrix Games, DealOrNoDeal 협상에서 경쟁력 있는 정렬을 보인다.
Reward design in reinforcement learning (RL) is challenging since specifying human notions of desired behavior may be difficult via reward functions or require many expert demonstrations. Can we instead cheaply design rewards using a natural language interface? This paper explores how to simplify reward design by prompting a large language model (LLM) such as GPT-3 as a proxy reward function, where the user provides a textual prompt containing a few examples (few-shot) or a description (zero-shot) of the desired behavior. Our approach leverages this proxy reward function in an RL framework. Specifically, users specify a prompt once at the beginning of training. During training, the LLM evaluates an RL agent's behavior against the desired behavior described by the prompt and outputs a corresponding reward signal. The RL agent then uses this reward to update its behavior. We evaluate whether our approach can train agents aligned with user objectives in the Ultimatum Game, matrix games, and the DealOrNoDeal negotiation task. In all three tasks, we show that RL agents trained with our framework are well-aligned with the user's objectives and outperform RL agents trained with reward functions learned via supervised learning
연구 동기 및 목표
- 핸드크래프트 보상이나 라벨링된 데이터를 넘어서 더 쉽고 직관적인 보상 명시를 가능하게 한다.
- RL 알고리즘의 변경 없이 LLM을 프록시 보상 함수로 사용하는 일반적인 RL 프레임워크를 제안한다.
- LLM 기반 보상이 SL 학습 보상보다 에이전트를 사용자 목표에 더 잘 정렬시킬 수 있음을 보인다.
- 다수의 대화형 작업에서 단일샷 및 다중샷 프롬프트에 대해 방법을 평가한다.
제안 방법
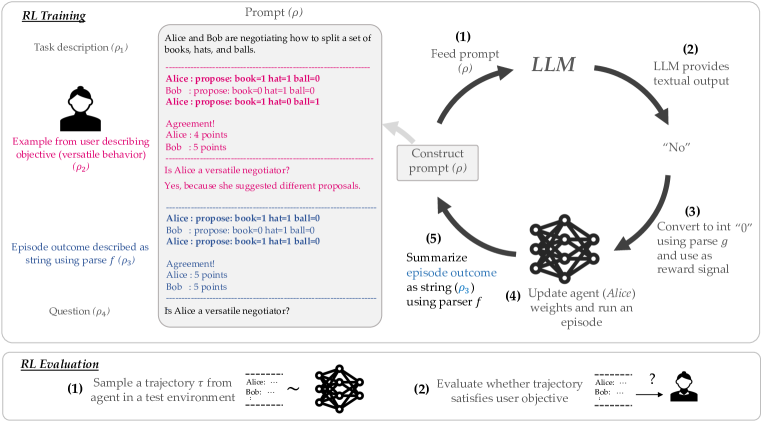
- 보상을 LLM이 과제 프롬프트와 에피소드 설명을 바탕으로 생성하는 MDP로 문제를 형식화한다.
- 작업 설명, 사용자 지정 목표(예시 또는 설명), 에피소드 결과, 그리고 목표 만족도에 관한 질문을 연결하여 프롬프트 ρ를 구성한다.
- 작업 특화 파서 g로 LLM의 출력을 해석하여 RL 업데이트에 사용할 스칼라 보상을 얻는다.
- LLM 유도 보상을 사용하여 임의의 RL 알고리즘으로 RL 에이전트를 학습한다.
- LLM 보상 신호의 라벨링 정확도와 실제 보상에 대비한 하류 RL 에이전트의 성능을 평가한다.
- 사용자 목표와의 주관적 정렬을 평가하기 위한 예비 인간 사용자 연구를 수행한다.
실험 결과
연구 질문
- RQ1Q1: 적은 샷 프롬 prompting에서 LLM이 사용자 목표와 일치하는 보상 신호를 생성할 수 있는가?
- RQ2Q2: 잘 알려진 목표에 대해 제로샷 프롬 prompting에서 객관적 목표에 일치하는 보상을 생성할 수 있는가?
- RQ3Q3: 협상과 같은 장기적 시나리오에서 목표에 정렬된 보상을 제공할 수 있는가?
주요 결과
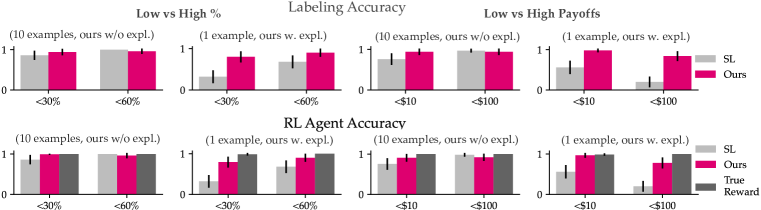
- LLMs는 소샷 프롬프트에서 사용자 목표와 일치하는 보상 신호를 제공하며, 설명이 정확도 향상에 크게 기여한다.
- Matrix 게임에서 제로샷 프롬 prompting은 잘 알려진 개념에 대해 목표에 정렬된 보상을 생성하고, No Objective 기준선 대비 라벨링 정확도를 향상시킨다.
- DealOrNoDeal에서 LLM 기반 보상은 에이전트 정확도를 평균 46% 향상시키고, 실제 보상 성능에 4% 이내로 근접하게 한다.
- 예비 사용자 연구에서 사용자 지정 스타일과 정렬된 에이전트가 현저하게 더 높은 정렬로 평가되었다(p<0.001).
- SL 기준선과 비교할 때, LLM 보상이 데이터 효율이 더 높다; SL은 유사한 정확도에 도달하기 위해 수백 개의 추가 라벨링 샘플이 필요하다.
- 프롬프트 설계의 강건성 분석에 따르면 설명은 더 높은 정확도의 핵심 요인이며, 프롬프트는 어휘 변화에 비교적 강건할 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.