[논문 리뷰] RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
RLEF는 강화 학습으로 실행 피드백을 활용하여 다-turn에서 코드 생성 LLM을 훈련시키고, CodeContests에서 샘플 수를 줄인 상태에서 최첨단 해결률을 달성하며 HumanEval+ 및 MBPP+에 혜택을 분산시킨다.
Large language models (LLMs) deployed as agents solve user-specified tasks over multiple steps while keeping the required manual engagement to a minimum. Crucially, such LLMs need to ground their generations in any feedback obtained to reliably achieve the desired outcomes. We propose an end-to-end reinforcement learning method for teaching models to leverage execution feedback in the realm of code synthesis, where state-of-the-art LLMs struggle to improve code iteratively compared to independent sampling. We benchmark on competitive programming tasks, where we achieve new state-of-the art results with both small (8B parameters) and large (70B) models while reducing the amount of samples required by an order of magnitude. Our analysis of inference-time behavior demonstrates that our method produces LLMs that effectively leverage automatic feedback over multiple steps.
연구 동기 및 목표
- 환경 피드백에서 코드 생성 LLM의 접지를 통해 반복적 수리 및 최종 정확성을 개선한다는 동기를 부여한다.
- 코드 실행으로부터의 피드백을 보상으로 사용하는 엔드 투 엔드 RL 프레임워크(RLEF)를 제안한다.
- RLEF가 더 작은 모델과 더 적은 샘플로 competitive programming 벤치마크의 해결률을 개선하는지 보여준다.
- RLEF의 개선이 다른 코드 생성 벤치마크(HumanEval+, MBPP+) 및 더 높은 턴 예산으로 일반화되는지를 입증한다.
제안 방법
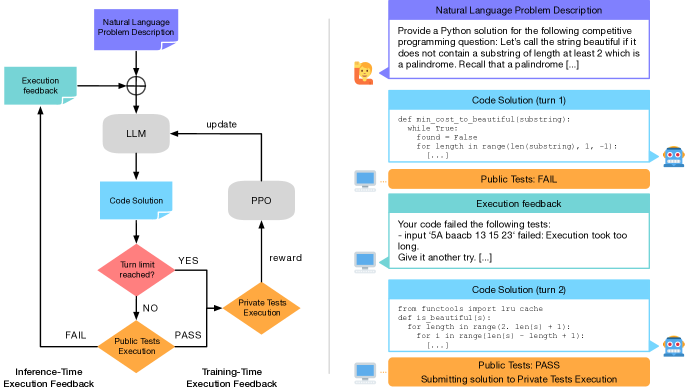
- 각 턴에서 코드가 생성되고 실행 피드백이 수신되는 다-turn 대화로 반복적 코드 합성을 모델링한다.
- 오염(Leakage)을 방지하고 견고한 평가를 보장하기 위해 학습 중 공개(feedback) 세트와 최종 평가를 위한 비공개(test) 세트를 사용한다.
- 문제를 부분 관측 가능 MDP로 프레이밍하고 초기 정책으로의 regularization을 위한 KL-penalty가 있는 Proximal Policy Optimization(PPO)으로 최적화한다.
- 정책을 토큰 수준의 행동으로 취급하고 턴 수준 가치 함수로 피드백 정보를 반영한 업데이트를 가능하게 한다.
- 이진 최종 보상과 잘못된 코드에 대한 페널티, 탐사와 충실성의 균형을 맞추는 KL 항을 도입한다.
실험 결과
연구 질문
- RQ1실행 피드백을 통한 강화 학습이 독립 샘플링을 초과하는 반복적 코드 합성을 개선할 수 있는가?
- RQ2RLEF가 LLM이 다중 턴에 걸친 맥락 내 실행 피드백을 효과적으로 활용하도록 하는가?
- RQ3RLEF의 개선이 CodeContests를 넘어 다른 코드 생성 벤치마크로 일반화되는가?
- RQ4RLEF가 소형 모델과 대형 모델에서 샘플 효율성과 턴 예산 활용에 어떤 영향을 미치는가?
주요 결과
| 모델 | 출처 | n@k | 유효 세트 | 테스트 세트 |
|---|---|---|---|---|
| AlphaCode 9B | Li et al. (2022) | 10@1k | 16.9 | 13.3 |
| AlphaCode 41B + clustering | Li et al. (2022) | 10@1k | 21.0 | 16.4 |
| Code Llama 34B + PPO | Xu et al. (2024) | 10@1k | 19.7 | 22.4 |
| AlphaCodium gpt-3.5-turbo-16k | Ridnik et al. (2024) | 5@100 | 25 | 17 |
| AlphaCodium gpt-4-0613 | Ridnik et al. (2024) | 5@100 | 44 | 29 |
| MapCoder gpt-3.5-turbo-1106 | Islam et al. (2024) | 1@23 | - | 12.7 |
| MapCoder gpt-4-1106-preview | Islam et al. (2024) | 1@19 | - | 28.5 |
| Llama 3.0 8B Instruct | Ours | 1@3 | 4.1 | 3.2 |
| 1ex + RLEF | Ours | 1@3 | 12.5 | 12.1 |
| Llama 3.1 8B Instruct | Ours | 1@3 | 8.9 | 10.5 |
| 1ex + RLEF | Ours | 1@3 | 17.2 | 16.0 |
| Llama 3.1 70B Instruct | Ours | 1@3 | 25.9 | 27.5 |
| 1ex + RLEF | Ours | 1@3 | 37.5 | 40.1 |
| Llama 3.1 8B Instruct | Ours | 10@100 | 21.7 | 24.8 |
| 1ex + RLEF | Ours | 10@100 | 29.8 | 28.7 |
| Llama 3.1 70B Instruct | Ours | 10@100 | 50.2 | 50.3 |
| 1ex + RLEF | Ours | 10@100 | 54.5 | 54.5 |
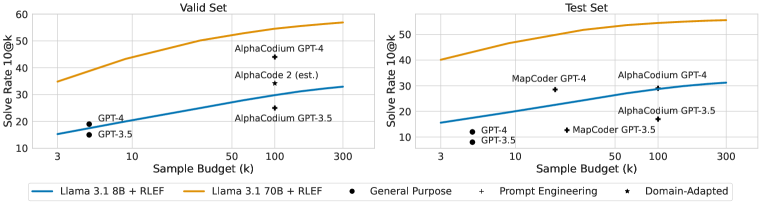
- RLEF로 학습된 모델은 8B 및 70B LLM 모두에 대해 CodeContests에서 새로운 최첨단 결과를 달성했고 샘플 요구량이 크게 감소했다.
- 테스트 세트에서 70B 모델이 RLEF 적용 후 각각 37.5와 40.1을 달성하며(1@3) 및 (1ex+RLEF 1@3)에서 이전 방법을 능가한다.
- RLEF의 개선이 HumanEval+ 및 MBPP+ 벤치마크로 전이되며 더 큰 샘플 예산에서도 지속된다.
- 추론 시 피드백은 다중 턴 자기 수정과 다양한(그러나 목표지향적인) 편집을 가능하게 하여 독립 샘플링에 대한 의존도를 감소시킨다.
- 참 피드백이 무작위 피드백보다 더 큰 이득을 가져오며, 이는 방법이 실행 신호의 의미 있는 피드백에 의존함을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.