[논문 리뷰] RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose
RTMPose는 MMPose를 기반으로 한 실시간 상단-다운 다중 인원 포즈 추정 프레임워크로, SimCC 기반 좌표 분류, CSPNeXt 백본, 배포 친화적 최적화를 사용하여 CPU, GPU, 모바일에서 높은 정확도와 낮은 지연을 달성합니다.
Recent studies on 2D pose estimation have achieved excellent performance on public benchmarks, yet its application in the industrial community still suffers from heavy model parameters and high latency. In order to bridge this gap, we empirically explore key factors in pose estimation including paradigm, model architecture, training strategy, and deployment, and present a high-performance real-time multi-person pose estimation framework, RTMPose, based on MMPose. Our RTMPose-m achieves 75.8% AP on COCO with 90+ FPS on an Intel i7-11700 CPU and 430+ FPS on an NVIDIA GTX 1660 Ti GPU, and RTMPose-l achieves 67.0% AP on COCO-WholeBody with 130+ FPS. To further evaluate RTMPose's capability in critical real-time applications, we also report the performance after deploying on the mobile device. Our RTMPose-s achieves 72.2% AP on COCO with 70+ FPS on a Snapdragon 865 chip, outperforming existing open-source libraries. Code and models are released at https://github.com/open-mmlab/mmpose/tree/1.x/projects/rtmpose.
연구 동기 및 목표
- 실시간 2D 다중 인원 포즈 추정 성능에 영향을 미치는 요인들(패러다임, 백본, 로컬라이제이션, 학습, 배포)을 조사한다.
- 산업 현장 배치를 위한 속도와 정확도의 균형을 갖춘 실시간 포즈 추정 프레임워크를 개발한다.
- 다양한 백엔드와 탐지기를 사용하여 CPU, GPU, 및 모바일 기기 간의 이식성을 입증한다.
- 산업 도입을 촉진하기 위해 오픈 소스 모델 및 배포 지침을 제공한다.
제안 방법
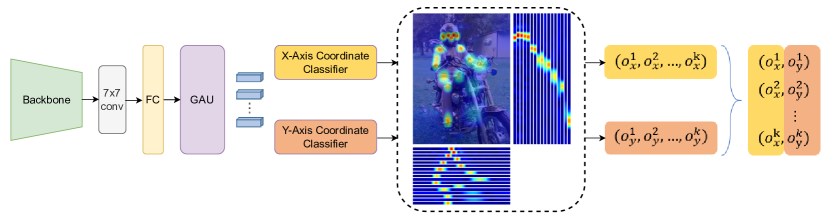
- 효율적인 탐지기와 각 대상마다 경량 포즈 추정기를 갖춘 상단-다운 파이프라인을 채택한다.
- 속도-정확도 균형 및 배포 친화성을 고려한 CSPNeXt 백본을 사용한다.
- 가우시안 소프트 레이블과 온도 스케일링을 포함하여 SimCC 기반 좌표 분류 방식(x 및 y를 각각)으로 키포인트를 예측한다.
- 키포인트 표현을 향상시키기 위해 Self-attention 정제(Gated Attention Unit, GAU)를 도입한다.
- UDP 사전 학습, EMA, 평탄 코사인 학습률 및 두 단계의 강한 후 약한 증강을 포함한 훈련 전략을 적용한다.
- 생략 프레임 감지, 포즈 NMS(OKS 기반), OneEuro 스무딩으로 추론 파이프라인을 최적화하고, PyTorch, ONNX Runtime, TensorRT, 및 ncnn에 배포한다.
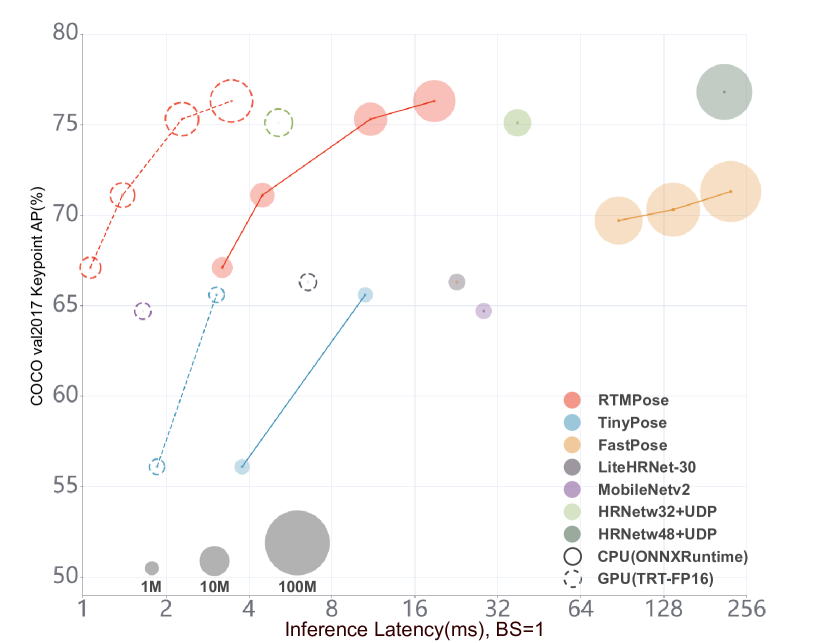
실험 결과
연구 질문
- RQ1실시간 다중 인원 포즈 추정에서 가장 좋은 속도-정확도 트레이드오프를 얻기 위한 패러다임, 백본, 로컬라이제이션 방법의 조합은 무엇인가?
- RQ2목표 지향 학습 및 구조적 선택을 갖춘 SimCC 기반 좌표 분류가 히트맵 기반 방법의 정확도에 필적하거나 이를 초과하면서 계산량을 줄일 수 있는가?
- RQ3배포 최적화와 플랫폼별 백엔드가 CPU, GPU, 모바일 하드웨어에서 실시간 성능에 어떤 영향을 미치는가?
주요 결과
| 방법 | 백본 | 감지기 | 감지 입력 크기 | 포즈 입력 크기 | GFLOPs | AP | 추가 데이터 |
|---|---|---|---|---|---|---|---|
| PaddleDetection TinyPose | Wider NLiteHRNet | YOLOv3 | 608x608 | 128x96 | 0.08 | 52.3 | |
| PaddleDetection TinyPose | Wider NLiteHRNet | YOLOv3 | 608x608 | 256x192 | 0.33 | 60.9 | |
| PaddleDetection TinyPose | Wider NLiteHRNet | Faster-RCNN | N/A | 128x96 | 0.08 | 56.1 | AIC(220K) |
| PaddleDetection TinyPose | Wider NLiteHRNet | Faster-RCNN | N/A | 256x192 | 0.33 | 65.6 | +Internal(unknown) |
| PaddleDetection TinyPose | Wider NLiteHRNet | PicoDet-s | 320x320 | 128x96 | 0.08 | 48.4 | |
| PaddleDetection TinyPose | Wider NLiteHRNet | PicoDet-s | 320x320 | 256x192 | 0.33 | 56.5 | |
| AlphaPose | FastPose | YoloV3 | 608x608 | 256x192 | 5.91 | 71.2 | - |
| MMPose | RTMPose-t | Faster-RCNN | N/A | 256x192 | 0.36 | 65.8 | - |
| MMPose | RTMPose-s | Faster-RCNN | N/A | 256x192 | 0.68 | 69.6 | - |
| MMPose | RTMPose-m | Faster-RCNN | N/A | 256x192 | 1.93 | 73.6 | - |
| MMPose | RTMPose-l | Faster-RCNN | N/A | 256x192 | 4.16 | 74.8 | - |
| MMPose | RTMPose-t | YOLOv3 | 608x608 | 256x192 | 0.36 | 66.0 | AIC(220K) |
| MMPose | RTMPose-s | YOLOv3 | 608x608 | 256x192 | 0.68 | 70.3 | |
| MMPose | RTMPose-m | YOLOv3 | 608x608 | 256x192 | 1.93 | 74.7 | |
| MMPose | RTMPose-l | YOLOv3 | 608x608 | 256x192 | 4.16 | 75.7 | |
| MMPose | RTMPose-m | RTMDet-nano | 320x320 | 256x192 | 1.93 | 73.2 | |
| MMPose | RTMPose-s | RTMDet-nano | 320x320 | 256x192 | 0.68 | 68.5 | |
| MMPose | RTMPose-m | RTMDet-nano | 320x320 | 256x192 | 1.93 | 73.2 | |
| MMPose | RTMPose-m | RTMDet-m | 640x640 | 256x192 | 1.93 | 75.7 | |
| MMPose | RTMPose-l | RTMDet-m | 640x640 | 256x192 | 4.16 | 76.6 |
- RTMPose-m은 COCO val에서 75.8% AP를 달성하고 CPU에서 90+ FPS, GTX 1660 Ti GPU에서 430+ FPS를 달성한다.
- RTMPose-l은 COCO에서 74.8% AP를 달성하고 보고된 구성에서 76.6 GFLOPs를 나타내며, 중간 정도의 연산으로 강력한 정확도를 시사한다.
- RTMPose-s는 COCO에서 72.2% AP를 달성하고 Snapdragon 865에서 70+ FPS를 기록하여 기존 오픈 소스 모바일 솔루션을 능가한다.
- SimCC와 CSPNeXt 백본 및 GAU 기반 정제를 사용하면 히트맵 기반 접근법(예: CT 기반 또는 트랜스포머 중심 베이스라인)보다 계산 비용이 낮으면서도 경쟁력 있는 정확도를 얻는다.
- 두 단계 학습( COCO에 UDP로 사전 학습 후 강-약 증강으로 미세 조정)과 EMA는 AP를 수치상 몇 포인트 향상시키며, 차등 분석에서 이를 입증한다.
- 생략 프레임 감지 및 후처리(OKS 기반 NMS 및 OneEuro 필터)로 지연을 줄이고 프레임 간 포즈 견고성을 향상시킨다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.