[논문 리뷰] RWKV: Reinventing RNNs for the Transformer Era
RWKV는 Transformer의 학습 효율성과 RNN의 추론 효율성을 결합한 하이브리드 아키텍처를 도입하여 선형 메모리/계산 확장을 달성하고, 동일 규모의 Transformers까지 최대 14B parameters로 경쟁한다.
Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, thus parallelizing computations during training and maintains constant computational and memory complexity during inference. We scale our models as large as 14 billion parameters, by far the largest dense RNN ever trained, and find RWKV performs on par with similarly sized Transformers, suggesting future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling trade-offs between computational efficiency and model performance in sequence processing tasks.
연구 동기 및 목표
- Self-attention의 메모리 및 이차 복잡도 병목 현상을 긴 시퀀스에서 해결한다.
- Transformer처럼 학습되지만 RNN처럼 추론될 수 있는 모델을 제안하여 시간과 공간에서 선형 확장을 달성한다.
- RWKV가 수십억 매개변수로 확장 가능하며 표준 NLP 벤치마크에서 트랜스포머 기준선과 경쟁할 수 있음을 보인다.
- 대규모 시퀀스 모델링을 위한 사전 학습된 RWKV 모델을 제공하고 실용적 이점을 입증한다.
제안 방법
- 시간-혼합 및 채널-혼합 블록을 결합한 Receptance Weighted Key Value (RWKV) 아키텍처를 도입한다.
- 전통적인 dot-product 주의(attention) 대신 채널별로 시간이 지나도 감소하는 선형 시간 WKV 연산자를 사용한다.
- 그라디언트를 안정화하고 레이어 정규화를 통한 깊은 스택을 가능하게 하는 토큰 시프트와 시간 의존 소프트맥스를 사용한다.
- Transformer와 유사한 학습은 시간 병렬 모드를 통해 가능하게 하고, RNN과 같은 자동회귀 추론은 가능하도록 한다.
- 대규모 모델에서의 효율성과 수렴을 개선하기 위해 커스텀 커널 및 초기화 전략을 적용한다.
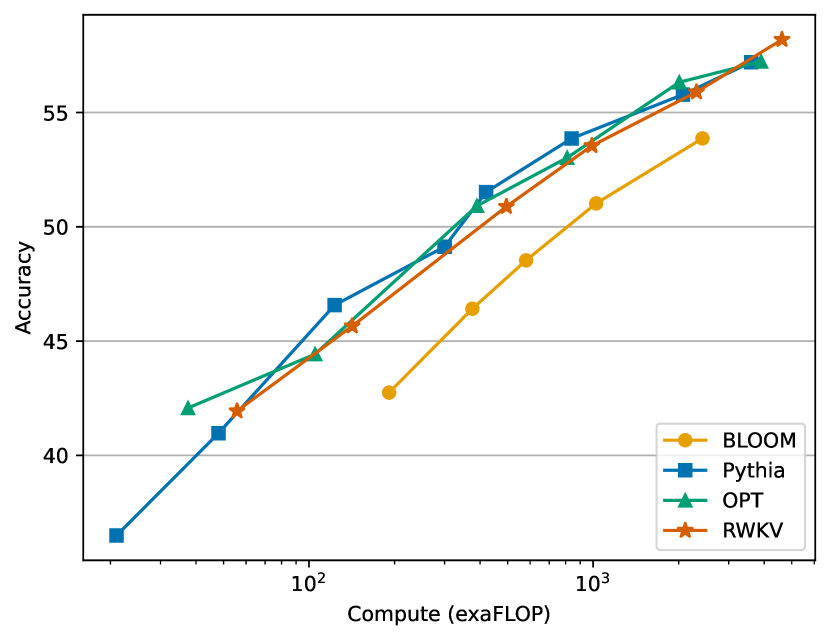
실험 결과
연구 질문
- RQ1RWKV가 Transformer's의 학습 병렬성을 달성하면서도 RNN의 선형 추론 비용을 유지할 수 있는가?
- RQ2RWKV가 비슷한 계산 예산에서 이차-Transformers 아키텍처와 비교하여 어떻게 확장되고 성능이 나오는가?
- RQ3긴 컨텍스트 처리 및 컨텍스트 길이가 RWKV의 성능과 효율성에 어떤 영향을 미치는가?
- RQ4대규모 말뭉치에서 매우 큰 RWKV 모델을 학습시키기 위한 최적화 및 초기화 전략은 무엇인가?
주요 결과
- RWKV 모델은 최대 14B parameters까지 학습 가능하며, 비슷한 규모의 Transformers와 경쟁력 있는 성능을 달성한다.
- RWKV는 시퀀스 길이에 대해 선형 추론 비용을 보이며, Transformer의 이차 확장과 대조를 이룬다.
- RWKV는 모델 규모에 따른 손실-계산 증가에 대해 Transformers와 유사한 확장 형태를 따르며 강한 적합도를 보인다.
- 미세조정(finetuning) 중 컨텍스트 길이를 증가시키면 테스트 손실이 감소하여 긴 문맥 정보를 효과적으로 활용함을 시사한다.
- RWKV는 표준 NLP 벤치마크에서 제로샷(zero-shot) 결과가 경쟁력 있으며 CPU/GPU 추론 시 텍스트 생성 속도/메모리 프로파일이 우수하다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.