[논문 리뷰] Safeguarding Large Language Models: A Survey
LLM 보호 가드레일의 체계적 문헌고찰로 프레임워크, 평가지표, 공격 및 방어, 그리고 포괄적이고 다학제적 가드레일 설계로의 경로를 검토한다.
In the burgeoning field of Large Language Models (LLMs), developing a robust safety mechanism, colloquially known as "safeguards" or "guardrails", has become imperative to ensure the ethical use of LLMs within prescribed boundaries. This article provides a systematic literature review on the current status of this critical mechanism. It discusses its major challenges and how it can be enhanced into a comprehensive mechanism dealing with ethical issues in various contexts. First, the paper elucidates the current landscape of safeguarding mechanisms that major LLM service providers and the open-source community employ. This is followed by the techniques to evaluate, analyze, and enhance some (un)desirable properties that a guardrail might want to enforce, such as hallucinations, fairness, privacy, and so on. Based on them, we review techniques to circumvent these controls (i.e., attacks), to defend the attacks, and to reinforce the guardrails. While the techniques mentioned above represent the current status and the active research trends, we also discuss several challenges that cannot be easily dealt with by the methods and present our vision on how to implement a comprehensive guardrail through the full consideration of multi-disciplinary approach, neural-symbolic method, and systems development lifecycle.
연구 동기 및 목표
- 현재 공급자 및 오픈 소스 커뮤니티에서 LLM 출력을 제어하는 데 사용되는 현재의 가드레일 프레임워크를 이해한다.
- 바람직한 속성(예: 환각 억제, 공정성, 프라이버시, 로버스트니스)과 이를 평가/향상하는 방법을 식별한다.
- 가드레일에 대한 공격 방법, 방어 및 강화 전략을 검토하여 가드레일을 강화한다.
- 개발 수명주기에 걸친 안전 표준에서 영감을 받은 포괄적이고 다학제적 가드레일 설계 경로를 논의한다.
제안 방법
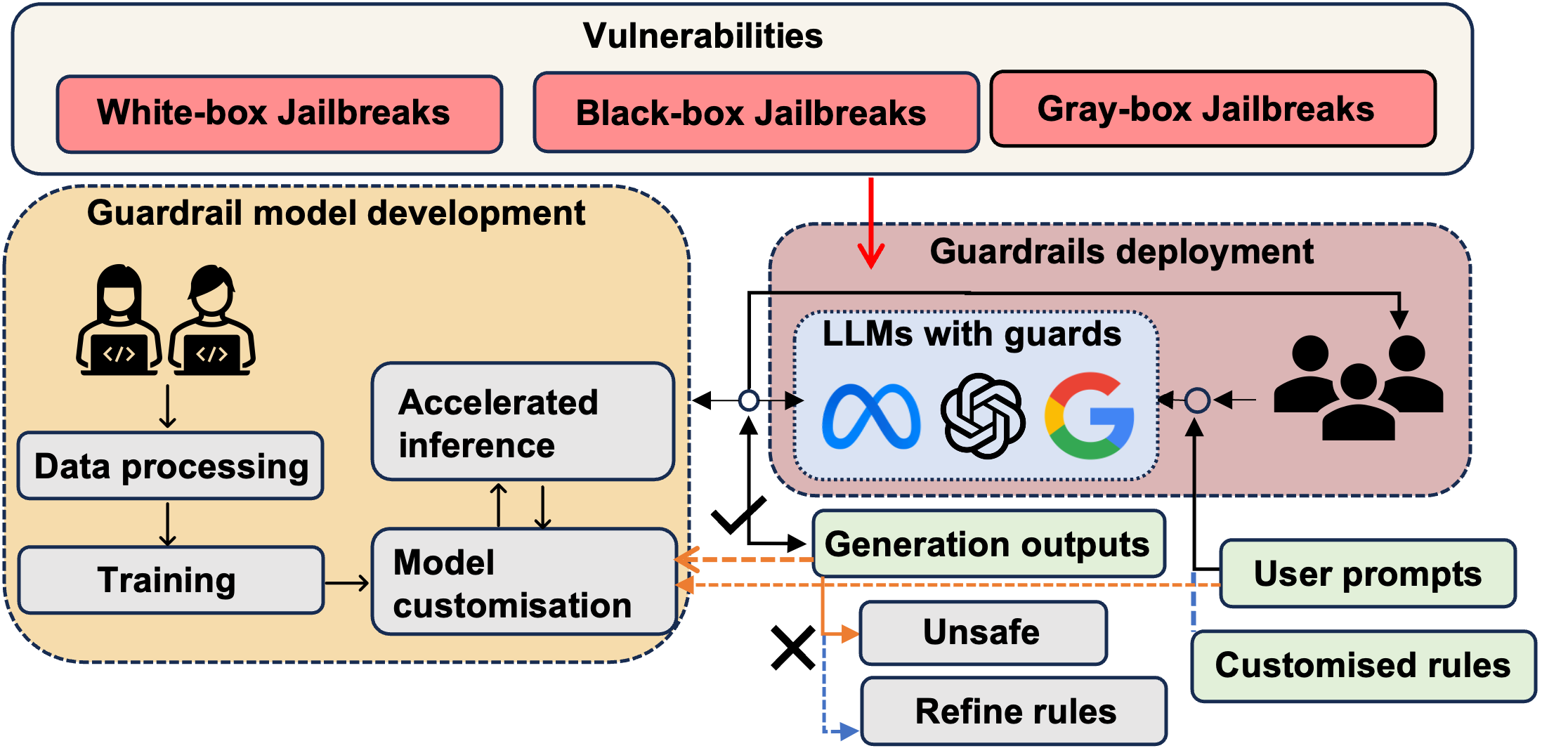
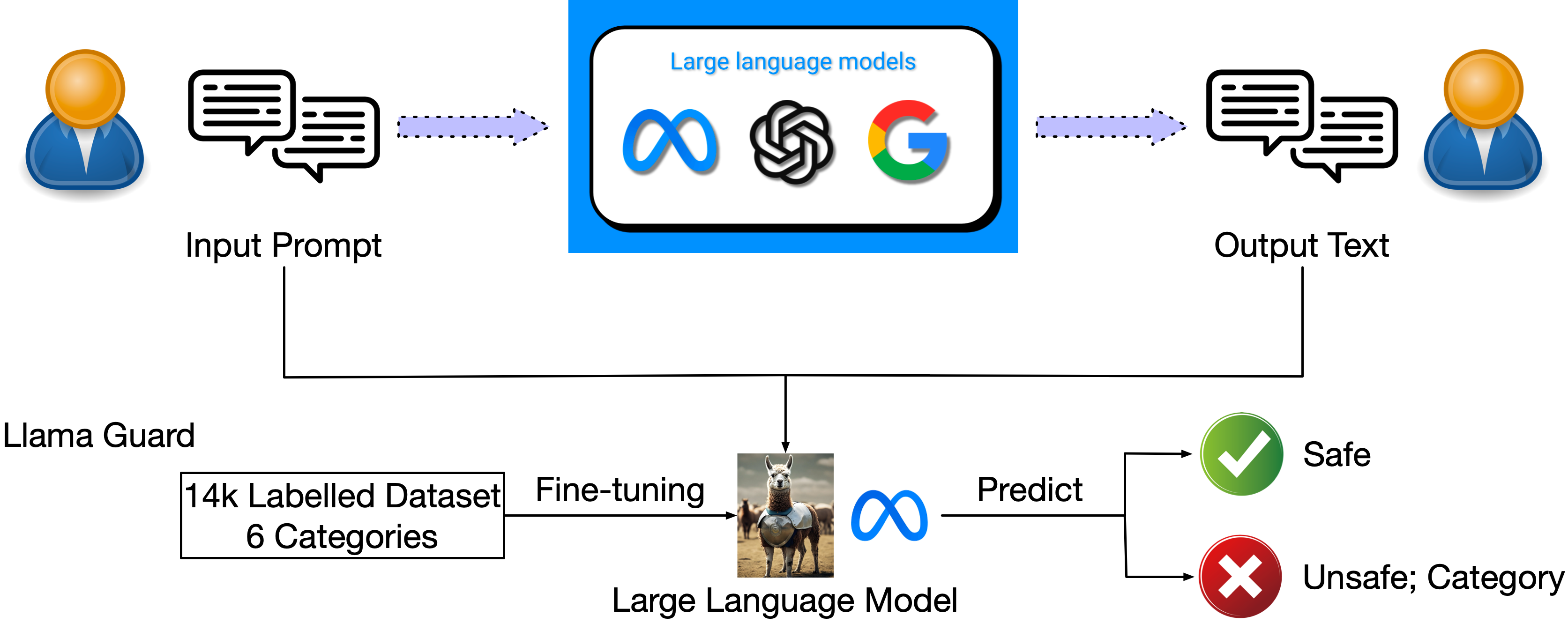
- 가드레일 프레임워크 및 지원 소프트웨어 패키지(예: Llama Guard, Nvidia NeMo, Guardrails AI, TruLens, Guidance AI, LMQL) 를 조사한다.
- 가드레일이 환각, 공정성, 프라이버시, 로버스트니스, 독성, 합법성, OOD, 불확실성 등의 속성을 어떻게 강제하는지 분석한다.
- 가드레일과 관련된 공격, 방어 및 강화 기법을 검토한다.
- 안전 중요 소프트웨어 표준(예: ISO-26262, DO-178B/C) 및 신경-기호 통합에서 영감을 받은 설계 고려사항을 논의한다.
- 가드레일 구현 또는 평가에 사용되는 도구 및 파이썬 패키지(LangChain, AIF360, ART, Fairlearn, Detoxify)를 강조한다.
실험 결과
연구 질문
- RQ1생산 및 오픈 소스 맥락에서 LLM 출력을 제어하기 위해 현재 배포된 가드레일 프레임워크와 워크플로우는 무엇인가?
- RQ2가드레일이 강제해야 하는 속성은 무엇이며, 이를 어떻게 정의하고 측정하며 향상시킬 수 있는가?
- RQ3가드레일을 우회하는 공격은 무엇이며, 이를 방어하거나 강화하는 전략은 무엇인가?
- RQ4가드레일을Specification, 설계, 구현, 통합, 검증, 생산에 이르는 포괄적이고 다학제적 시스템으로 설계할 수 있는가?
주요 결과
- 여러 가드레일 솔루션이 존재하며(예: Llama Guard, Nvidia NeMo, Guardrails AI) 환각, 독성, 합법성, OOD 및 불확실성에 대한 커버리지가 상이하다.
- 가드레일은 일반적으로 여러 신경-기호 설계 패턴 중 하나에 속하며, 느슨하게 결합된 구조에서 더 통합된 접근 방식까지 다양하고, 보편적인 신뢰성 보장을 결여하고 있다.
- 공격은 가드레일을 우회할 수 있으며, 방어 및 강화 전략은 지속적인 평가와 업데이트가 필요한 활발한 연구 영역이다.
- 포괄적 가드레일은 다학제적 방법, 신경-기호 기술 및 안전 표준에 맞춘 시스템 개발 수명주기가 필요하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.