[논문 리뷰] SELFormer: Molecular Representation Learning via SELFIES Language Models
SELFormer는 SELFIES 입력을 사용하는 트랜스포머 기반 화학 언어 모델로, 2백만 개의 ChEMBL 분자에 대해 사전 학습되고 분자 특성 예측을 위해 미세 조정되었으며, 주요 작업에서 SMILES 기반 및 그래프 기반 방법을 능가합니다.
Automated computational analysis of the vast chemical space is critical for numerous fields of research such as drug discovery and material science. Representation learning techniques have recently been employed with the primary objective of generating compact and informative numerical expressions of complex data. One approach to efficiently learn molecular representations is processing string-based notations of chemicals via natural language processing (NLP) algorithms. Majority of the methods proposed so far utilize SMILES notations for this purpose; however, SMILES is associated with numerous problems related to validity and robustness, which may prevent the model from effectively uncovering the knowledge hidden in the data. In this study, we propose SELFormer, a transformer architecture-based chemical language model that utilizes a 100% valid, compact and expressive notation, SELFIES, as input, in order to learn flexible and high-quality molecular representations. SELFormer is pre-trained on two million drug-like compounds and fine-tuned for diverse molecular property prediction tasks. Our performance evaluation has revealed that, SELFormer outperforms all competing methods, including graph learning-based approaches and SMILES-based chemical language models, on predicting aqueous solubility of molecules and adverse drug reactions. We also visualized molecular representations learned by SELFormer via dimensionality reduction, which indicated that even the pre-trained model can discriminate molecules with differing structural properties. We shared SELFormer as a programmatic tool, together with its datasets and pre-trained models. Overall, our research demonstrates the benefit of using the SELFIES notations in the context of chemical language modeling and opens up new possibilities for the design and discovery of novel drug candidates with desired features.
연구 동기 및 목표
- 학습을 위해 100% 유효하고 강건한 분자 표현을 개선하도록 동기를 부여
- 트랜스포머 언어 모델과 함께 강건한 문자열 기반 분자 표기법인 SELFIES를 활용
- 대규모 약물 유사 분자 코퍼스에서 사전 학습하고 다양한 특성 예측 작업에 맞게 미세 조정
- 다수의 벤치마크에서 SMILES 기반 및 그래프 기반 모델과의 성능을 비교
- 연구 커뮤니티에 코드, 데이터셋, 사전 학습 모델의 오픈 액세스를 제공
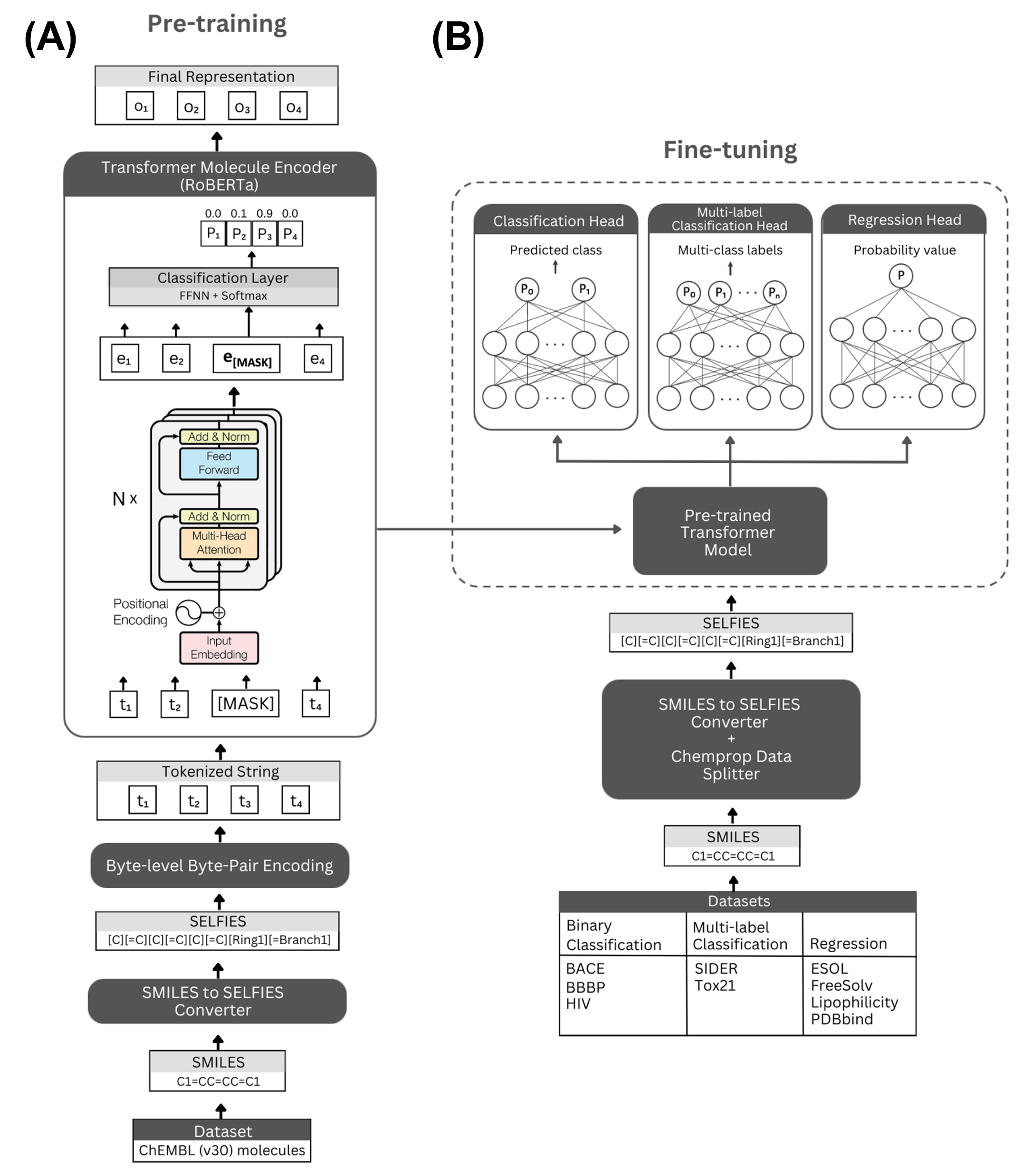
제안 방법
- SMILES를 SELFIES로 변환하고 RoBERTa와 유사한 바이트 레벨 BPE를 사용해 토큰화
- 2M ChEMBL 분자에서 마스킹된 언어 모델링으로 RoBERTa 유사한 트랜스포머 인코더를 사전 학습
- SELFormer 및 SELFormer-Lite를 선택하기 위한 주의: 어텐션 헤드, 층 수, 학습률, 배치 크기, 에포크 수 등 하이퍼파라미터 탐색 수행
- 사전 학습 모델을 MoleculeNet 분류 및 회귀 작업에 두 레이어 선형 헤드로 미세 조정
- 분류에는 ROC-AUC 및 PRC, 회귀에는 RMSE로 평가하고, scaffold 및 무작위 분할을 사용
- 사전 학습된 모델과 표현을 공개적으로 이용 가능하게 만들다
실험 결과
연구 질문
- RQ1SELFIES 기반 트랜스포머가 SMILES 기반 모델보다 더 강건한 분자 표현을 학습할 수 있는가?
- RQ2큰 SELFIES 코퍼스에서의 사전 학습이 다운스트림 분자 특성 예측 성능에 어떠한 영향을 미치는가?
- RQ3표준 MoleculeNet 작업에서 사전 학습 표현을 사용하는 것과 미세 조정의 차이가 어느 정도인가?
- RQ4분류 및 회귀 벤치마크에서 SELFIES 기반 모델이 그래프 기반 및 SMILES 기반 언어 모델과 어떻게 비교되는가?
주요 결과
- SELFormer는 수용성 예측 및 부작용(SIDER, ESOL 등) 예측에서 경쟁 방법을 능가합니다.
- 추가 다운스트림 작업에서 SELFIES 기반 모델이 다른 방법들과 유사한 결과를 달성합니다.
- 강한 미세 조정 이전의 사전 학습 표현도 시각화 분석에서 서로 다른 구조적 특성을 가진 분자를 구별합니다.
- 비교 연구에서 SELFormer가 대부분의 작업에서 경량 버전 SELFormer-Lite를 지속적으로 능가하고, 미세 조정으로 성능이 향상됩니다.
- 최적화된 하이퍼파라미터로 미세 조정하면 여러 벤치마크에서 현저한 이점을 얻고, SELFIES는 입체화학에 민감한 작업에서 성능 향상에 기여합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.