[논문 리뷰] SHViT: Single-Head Vision Transformer with Memory Efficient Macro Design
SHViT는 메모리 효율적인 매크로 설계와 단일 헤드 자기 주의 모듈을 도입하여 GPU, CPU 및 모바일 장치에서 빠르고 정확한 비전 트랜스포머를 달성합니다. 큰 스톱 16x16 패치 스템과 SHSA를 갖춘 3단계 아키텍처를 사용하여 다양한 작업에서 속도-정확도 간 최대화를 달성합니다.
Recently, efficient Vision Transformers have shown great performance with low latency on resource-constrained devices. Conventionally, they use 4x4 patch embeddings and a 4-stage structure at the macro level, while utilizing sophisticated attention with multi-head configuration at the micro level. This paper aims to address computational redundancy at all design levels in a memory-efficient manner. We discover that using larger-stride patchify stem not only reduces memory access costs but also achieves competitive performance by leveraging token representations with reduced spatial redundancy from the early stages. Furthermore, our preliminary analyses suggest that attention layers in the early stages can be substituted with convolutions, and several attention heads in the latter stages are computationally redundant. To handle this, we introduce a single-head attention module that inherently prevents head redundancy and simultaneously boosts accuracy by parallelly combining global and local information. Building upon our solutions, we introduce SHViT, a Single-Head Vision Transformer that obtains the state-of-the-art speed-accuracy tradeoff. For example, on ImageNet-1k, our SHViT-S4 is 3.3x, 8.1x, and 2.4x faster than MobileViTv2 x1.0 on GPU, CPU, and iPhone12 mobile device, respectively, while being 1.3% more accurate. For object detection and instance segmentation on MS COCO using Mask-RCNN head, our model achieves performance comparable to FastViT-SA12 while exhibiting 3.8x and 2.0x lower backbone latency on GPU and mobile device, respectively.
연구 동기 및 목표
- 효율 ViT의 매크로 및 마이크로 설계의 계산 중복 식별.
- 메모리 액세스 및 지연을 줄이기 위한 메모리 효율적 매크로 설계 제안.
- 다중 헤드 중복을 완화하기 위한 Single-Head Self-Attention (SHSA) 개발.
- 빠른 추론을 유지하면서 SHViT 패밀리 구축.
- ImageNet 분류 및 COCO 탐지/세분화에서 SHViT의 효과성 시연.
제안 방법
- 4x4 패치 임베딩과 더 큰 스트라이드 스템 및 3단계 설계와의 비교를 통해 매크로 설계의 중복성 분석.
- 16x16 패치화 스템과 단계별 토큰 축소를 활용한 메모리 효율적 매크로 설계 제안.
- 단일 헤드가 채널의 부분 집합에서 작동하고 다른 채널은 잔여로 남겨두는 방식을 통해 SHSA를 도입.
- BN 패스스루 및 ReLU 활성화로 속도를 높인 Depthwise 합성곱, SHSA 및 FFN으로 SHViT 블록 구성.
- 다양한 깊이/너비로 SHViT 변형(S1–S4) 4종을 대량 채널 수와 중첩 패치 임베딩을 활용해 학습.
- ImageNet-1K에서 분류 및 COCO에서 RetinaNet/Mask R-CNN에서 모바일 대기시간 포함으로 SHViT를 평가.
- SHViT를 SOTA 효율 모델 및 ONNX 런타임 성능과 비교 조정.
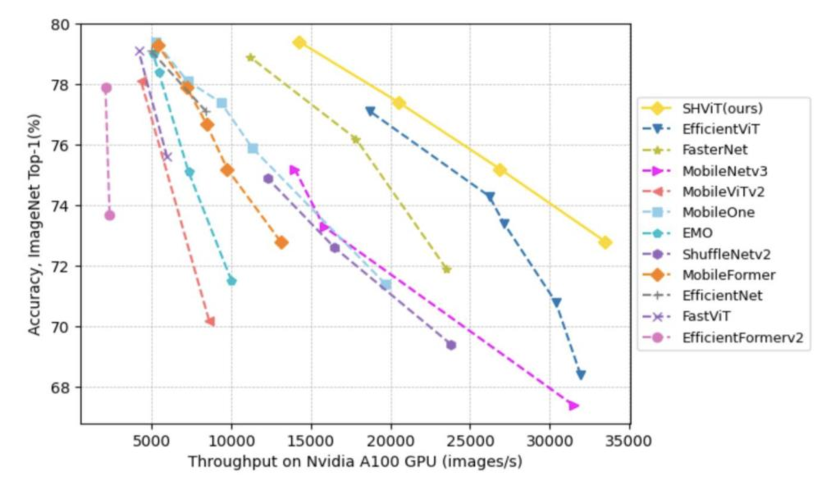
실험 결과
연구 질문
- RQ1더 큰 스트라이드 패치 임베딩 스템이 정확성을 유지하면서 메모리 액세스 비용을 줄이는가?
- RQ2초기 단계에서 주의력을 회로 대신 컨볼루션으로 대체해 속도를 개선할 수 있는가?
- RQ3이후 MHSA 계층에서 단일 헤드 설계로 크게 헤드 중복을 완화할 수 있는가?
- RQ4SHViT가 GPU, CPU, 모바일 등 다양한 디바이스와 작업(분류, 탐지, 세분화)에서 SOTA 효율 모델과 비교했을 때 어떤 성능을 보이는가?
주요 결과
- 16x16 패치 스템과 3단계 설계가 메모리 액세스를 줄이고 4x4 스템에 비해 경쟁력 있는 정확성을 유지합니다.
- 초기 단계의 컨볼루션이 주의에 비해 효율성이 높아 지연을 줄일 수 있습니다.
- Single-Head Self-Attention (SHSA)는 부분 채널 집합에서 주의를 계산하고 모든 채널에 최종 투영을 적용하여 헤드 중복과 메모리 바운드 연산을 감소시킵니다.
- SHViT 변형은 GPU, CPU 및 모바일 장치에서 속도-정확도 간 우수한 Trade-off를 달성하며, 예를 들어 SHViT-S4가 유사한 모델에 비해 상당한 처리량 및 Top-1 정확도 이점을 보입니다.
- COCO에서 SHViT 백본은 RetinaNet 및 Mask R-CNN 헤드에서 낮은 지연으로 경쟁력 있는 혹은 우수한 AP 지표를 제공합니다.
- ONNX 런타임은 SHViT의 축소된 재구성 및 메모리 바운드 연산의 이점을 통해 실시간 성능을 향상시킵니다.
![Figure 2 : Macro design analysis. All stages are composed of MetaFormer blocks [ 28 ] . The stages depicted in blue and red utilize depthwise convolution and attention layers as token mixer, respectively. In the table below, the macro design numbers represent the number of channels, while the number](https://ar5iv.labs.arxiv.org/html/2401.16456/assets/x2.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.