[논문 리뷰] SLiC-HF: Sequence Likelihood Calibration with Human Feedback
SLiC-HF는 Sequence Likelihood Calibration을 적용하여 인간의 선호로부터 학습하고, Reddit TL;DR 요약에서 및 오프 폴시 피드백 데이터에서 RLHF-PPO에 비해 더 단순하고 효율적인 대안을 제시하며 경쟁력 있는 결과를 보여줍니다.
Learning from human feedback has been shown to be effective at aligning language models with human preferences. Past work has often relied on Reinforcement Learning from Human Feedback (RLHF), which optimizes the language model using reward scores assigned from a reward model trained on human preference data. In this work we show how the recently introduced Sequence Likelihood Calibration (SLiC), can also be used to effectively learn from human preferences (SLiC-HF). Furthermore, we demonstrate this can be done with human feedback data collected for a different model, similar to off-policy, offline RL data. Automatic and human evaluation experiments on the TL;DR summarization task show that SLiC-HF significantly improves supervised fine-tuning baselines. Furthermore, SLiC-HF presents a competitive alternative to the PPO RLHF implementation used in past work while being much simpler to implement, easier to tune and more computationally efficient in practice.
연구 동기 및 목표
- 참조 요약을 넘어 인간의 선호와 일치시키는 언어 모델을 정렬하도록 유도합니다.
- SLiC-HF를 인간 피드백을 사용하는 시퀀스 수준 보정 방법으로 도입합니다.
- 다른 모델의 오프 폴시 피드백 데이터를 SLiC-HF가 활용할 수 있음을 보여줍니다.
- Reddit TL;DR 요약에서 SLiC-HF를 평가하고 RLHF 기준과 비교합니다.
제안 방법
- 표준 데이터에서 SFT 모델을 미세 조정한 다음 인간 선호 데이터를 사용하여 SLiC 보정을 적용합니다.
- 랭크 보정 손실 사용: Lcal = max(0, delta - log P_theta(y+|x) + log P_theta(y-|x)).
- 모델이 지나치게 벗어나지 않도록 목표 시퀀스 y_ref를 사용한 교차 엔트로피 정규화 항을 사용합니다.
- 변형을 탐구합니다: SLiC-HF-sample-rank(보상/랭킹 모델로 순위 매긴 샘플 후보)와 SLiC-HF-direct(HF 데이터에 직접 보정).
- HF 데이터로 랭킹 및 보상 모델을 학습하여 후보 디코드를 점수화하고 보정을 안내합니다.
- 정규화 대상 비교: SFT 데이터의 y_ref와 디코딩에서 최상 랭크된 후보 간 비교.
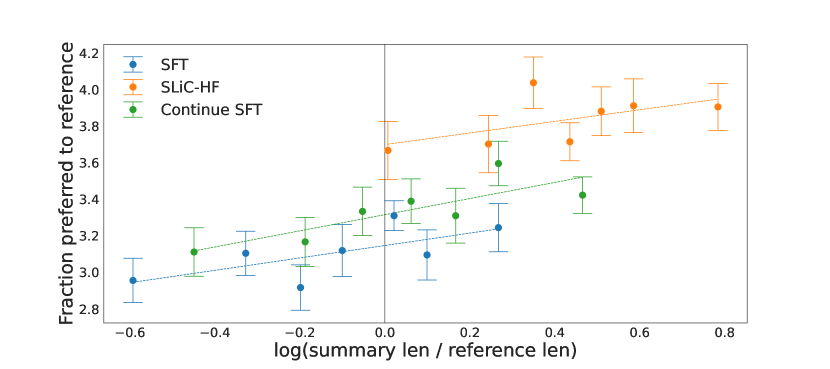
실험 결과
연구 질문
- RQ1SLiC-HF가 인간 선호 데이터로부터 학습하여 요약을 SFT 기준선보다 개선할 수 있나요?
- RQ2성능, 학습의 간단함, 계산 효율성 측면에서 SLiC-HF와 RLHF-PPO는 어떻게 비교되나요?
- RQ3다른 모델에 대해 수집된 데이터인 오프 폴시 인간 피드백이 SLiC-HF에서 효과적으로 전달되나요?
- RQ4다른 SLiC-HF 변형(sample-rank, direct) 및 정규화 대상이 성능에 미치는 influence은 무엇인가요?
- RQ5랭킹 기반 피드백 모델과 보상 기반 모델이 SLiC 보정 안내에 얼마나 다르게 기여하나요?
주요 결과
- SLiC-HF는 인간 평가에서 Reddit TL;DR에서 감독 학습 미세조정 기준선을 크게 개선합니다.
- 랭킹 기반 HF 모델이 보상 기반 HF 모델보다 더 높은 정렬성을 달성합니다(랭킹 정확도 약 73.2% 대 71.3%).
- 랭킹을 사용하는 SLiC-HF-sample-rank가 테스트된 변형 중 가장 높은 승률을 보고했으며(랭커 승률 최대 86.21%).
- SLiC-HF가 RLHF-PPO에 비해 경쟁력 있는 성능을 달성하며, 일부 변형은 인간 평가에서 RLHF-PPO 기준선을 능가합니다.
- SLiC-HF-direct는 더 간단하지만 출력이 길어지고 수렴이 덜 안정적일 수 있으며, SLiC-HF-sample-rank는 여전히 견고합니다.
- 모델 크기를 확장하면 SLiC-HF 성능이 향상됩니다(예: 11B 랭킹 모델과 770M 생성 모델의 조합에서 이득이 있음).
- 다수의 기준선에 걸친 인간 평가에서 SLiC-HF가 최우수 모델로 선택된 비율이 73%에 이릅니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.