[논문 리뷰] Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
소피아는 대각 Hessian 프리-컨디셔너와 각 좌표 클리핑을 사용하는 가벼운 2차 최적화기를 도입하여, 큰 오버헤드 없이 GPT 유사 언어 모델 사전 학습에서 AdamW 대비 약 2배의 속도 개선을 달성한다.
Given the massive cost of language model pre-training, a non-trivial improvement of the optimization algorithm would lead to a material reduction on the time and cost of training. Adam and its variants have been state-of-the-art for years, and more sophisticated second-order (Hessian-based) optimizers often incur too much per-step overhead. In this paper, we propose Sophia, Second-order Clipped Stochastic Optimization, a simple scalable second-order optimizer that uses a light-weight estimate of the diagonal Hessian as the pre-conditioner. The update is the moving average of the gradients divided by the moving average of the estimated Hessian, followed by element-wise clipping. The clipping controls the worst-case update size and tames the negative impact of non-convexity and rapid change of Hessian along the trajectory. Sophia only estimates the diagonal Hessian every handful of iterations, which has negligible average per-step time and memory overhead. On language modeling with GPT models of sizes ranging from 125M to 1.5B, Sophia achieves a 2x speed-up compared to Adam in the number of steps, total compute, and wall-clock time, achieving the same perplexity with 50% fewer steps, less total compute, and reduced wall-clock time. Theoretically, we show that Sophia, in a much simplified setting, adapts to the heterogeneous curvatures in different parameter dimensions, and thus has a run-time bound that does not depend on the condition number of the loss.
연구 동기 및 목표
- 언어 모델의 사전 학습 비용이 높은 문제와 Adam 및 단순한 1차 방법을 넘어 더 빠른 최적화기의 필요성을 동기 부여하고 해결한다.
- _CURVE_ 정보를 활용하면서도 per-step 오버헤드를 줄이는 경량 2차 최적화기를 개발한다.
- 모델 성능을 해치지 않으면서 학습 단계 수, 총 컴퓨트, 실제 벽시계 시간을 크게 감소시킨다.
- 대각 Hessian 프리-컨디셔너가 매개변수 간 이질적인 곡률에 적응한다는 이론적·경험적 증거를 제공한다.]
- method2_singleton_placeholder
제안 방법
- 소피아를 제안하는데, 이는 업데이트 방향으로 도함수의 이동 평균을 대각 Hessian 추정치의 이동 평균으로 나눈 값을 사용한다.
- k 간격(k=10)으로 대각 Hessian을 추정하는 두 가지 옵션을 사용한다: Hutchinson의 편향되지 않은 추정기(Hessian-벡터 곱) 및 Gauss-Newton-Bartlett(GNB) 추정기(가우스-노튼의 대각선).
- 최악의 업데이트 크기를 제어하고 비凸 환경에서 견고한 동작을 보장하기 위해 좌표별 클리핑을 적용한다.
- 업데이트 규칙은 그래디언트 EMA, 대각 Hessian 프리-컨디셔너, 그리고 클리핑이 결합되어: theta_{t+1} = theta_t - eta_t * clip(m_t / max{gamma * h_t, epsilon}, 1).
- PSD 프리-컨디셔너를 보장하기 위해 양의 대각 Hessian 항목을 유지하여 하강 방향을 확보한다.
- 기존 파이프라인에 최소한의 오버헤드로 Practical하게 통합 가능하며 PyTorch/JAX와 호환됨을 시연한다.]
- research_questions1_placeholder
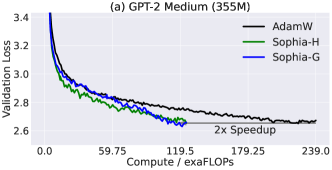
실험 결과
연구 질문
- RQ1짧은 요약: 가벼운 대각 Hessian 기반 프리-컨디셔너와 클리핑은 AdamW에 비해 언어 모델 사전 학습 속도를 높일 수 있는가?
- RQ2두 가지 추정기(Hutchinson 및 Gauss-Newton-Bartlett)가 큰 언어 모델에서 합리적인 오버헤드로 신뢰할 수 있는 대각 Hessian 추정치를 제공하는가?
- RQ3125M에서 6.6B 매개변수에 이르는 모델 규모에서, 동일한 검증 손실에 도달하는 단계 수와 총 컴퓨트 측면에서 소피아의 성능은 어떠한가?
- RQ4좌표별 클리핑 메커니즘이 비凸 LLM 풍경에서 안정성과 수렴성을 개선하는가?
- RQ5이론적 통찰은 소피아의 이질적 곡률에 대한 적응과 조건수에 무관한 런타임 특성을 어떻게 설명하는가?
주요 결과
- 소피아는 GPT-2 및 GPT NeoX 사전 학습에서 모델 규모에 관계없이 단계 수, 총 컴퓨트, 실제 벽시계 시간 면에서 AdamW에 비해 약 2배의 속도 향상을 달성한다.
- 소피아는 약 50% 적은 단계 수, 약 50% 적은 총 컴퓨트 및 벽시계 시간으로 같은 검증 사전 학습 손실에 도달한다.
- 125M에서 1.5B+ 매개변수에 이르는 모델 규모 전반에서 소피아와 AdamW 간의 성능 격차가 커지며, 더 큰 모델에서 더 큰 이점이 나타난다.
- 두 가지 대각 Hessian 추정기(Hutchinson 및 Gauss-Newton-Bartlett)는 매 단계 오버헤드를 약 5% 정도 도입하지만 확장 가능한 프리-컨디셔닝을 가능하게 한다.
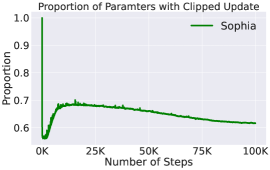
- 클리핑 메커니즘은 음의 곡률과 급격한 Hessian 변화에 대한 안전장을 제공하여 견고한 학습을 가능하게 하고 Newton 유사 실패를 방지한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.