[논문 리뷰] SpeechPrompt v2: Prompt Tuning for Speech Classification Tasks
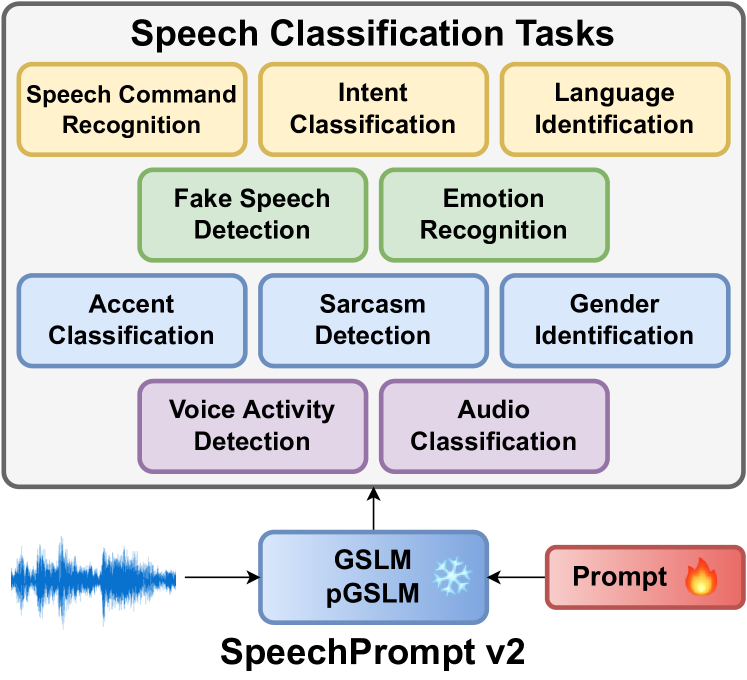
SpeechPrompt v2는 학습 가능한 발화기로 최소한의 학습 가능한 매개변수를 사용해 다양한 음성 분류 작업을 수행하며 여러 언어와 작업에서 경쟁력 있거나 최첨단 결과를 달성한다.
Prompt tuning is a technology that tunes a small set of parameters to steer a pre-trained language model (LM) to directly generate the output for downstream tasks. Recently, prompt tuning has demonstrated its storage and computation efficiency in both natural language processing (NLP) and speech processing fields. These advantages have also revealed prompt tuning as a candidate approach to serving pre-trained LM for multiple tasks in a unified manner. For speech processing, SpeechPrompt shows its high parameter efficiency and competitive performance on a few speech classification tasks. However, whether SpeechPrompt is capable of serving a large number of tasks is unanswered. In this work, we propose SpeechPrompt v2, a prompt tuning framework capable of performing a wide variety of speech classification tasks, covering multiple languages and prosody-related tasks. The experiment result shows that SpeechPrompt v2 achieves performance on par with prior works with less than 0.15M trainable parameters in a unified framework.
연구 동기 및 목표
- 매개변수 효율적이고 통합된 프롬프트를 통한 음성 분류의 필요성에 동기 부여.
- 내용 및 억양 작업과 다중 언어에 걸쳐 작동하는 프롬팅 프레임워크 개발.
- 경쟁력 있는 성능을 유지하면서 학습 가능한 매개변수 감소.
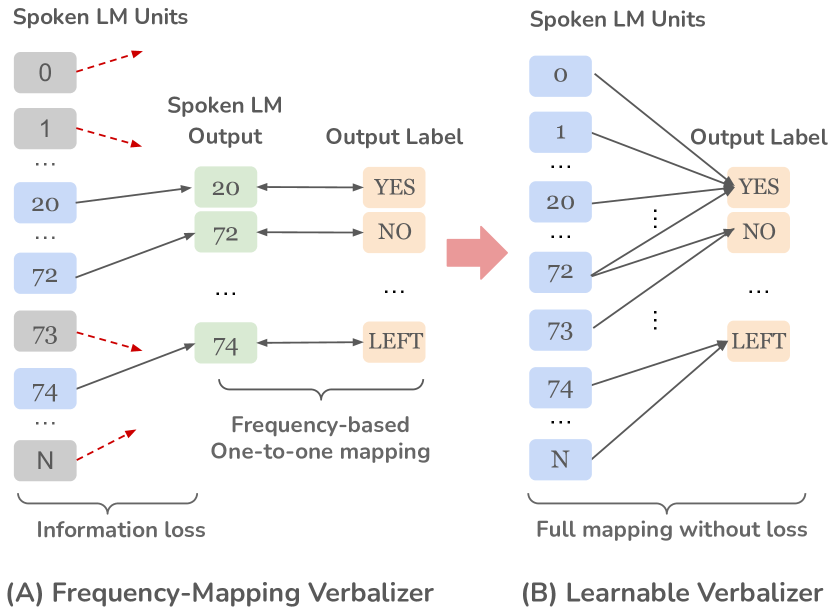
- LM 출력에서 작업 레이블로의 매핑을 개선하기 위한 학습 가능한 발화자 도입.
- 광범위한 작업군에서 일반화와 한계 평가.
제안 방법
- 고정된 사전 학습된 구어 LLM(GSLM 및 pGSLM)을 백본으로 사용하되 매개변수는 동결.
- 입력 임베딩과 결합된 작고 작업 특이적인 프롬프트 벡터를 학습하고 이를 Transformer 계층의 심층 prompting에 사용.
- 작업 레이블로 LM 출력 분포를 매핑하기 위해 학습 가능한 발화자(선형 모델)를 적용하고 프롬프트와 함께 공동으로 학습.
- 작업별 하이퍼파라미터 조정 없음; 고정 프롬프트 길이(l=5) 및 프롬프트 크기(~0.128M 매개변수).
- 14개 데이터셋에서 10개 음성 분류 작업을 다중 언어 및 음성 특성에 걸쳐 평가.
- 완전 감독 및 사전 학습/미세 조정 패러다임 하에서 SOTA와 비교.
실험 결과
연구 질문
- RQ1SpeechPrompt v2가 최소한의 학습 가능한 매개변수로 넓은 범위의 음성 분류 작업에서 경쟁력 있는 성능을 달성할 수 있는가?
- RQ2학습 가능한 발화자가 음성 LLM의 프롬프트 성능을 일관되게 향상시키는가?
- RQ3Content 관련 작업과 Prosody 관련 작업 및 언어 전반에서 SpeechPrompt v2의 성능 차이는 어떠한가?
- RQ4영어나 다양한 음성 데이터에서 프롬프트 튜닝의 한계 및 안정성 문제는 무엇인가?
주요 결과
| 작업 | 지표 | 데이터셋 | 언어 | 클래스 수 | SOTA(최고 성능) | GSLM | GSLM+ | pGSLM | pGSLM+ |
|---|---|---|---|---|---|---|---|---|---|
| SCR | ACC (↑) | Google SC v1 | En | 12 | 98.6 [10] | 94.5 | 94.6 | 94.3 | 94.7 (-3.9) |
| Grabo SC | ACC (↑) | Google SC v1? | Du | 36 | 98.9 [11] | 92.4 | 92.7 (-6.2) | 17.5 | 19.6 |
| Lithuanian SC | ACC (↑) | Lithuanian SC | Lt | 15 | 91.8 [9] | 93.2 | 95.5 (+3.7) | 90.9 | 79.5 |
| Arabic SC | ACC (↑) | Arabic SC | Ar | 16 | 98.9 [9] | 99.7 | 100.0 (+1.1) | 85.6 | 92.6 |
| IC | ACC (↑) | Fluent SC | En | 24 | 99.7 [12] | 97.2 | 97.3 | 98.1 | 98.2 (-1.5) |
| LID | ACC (↑) | Voxforge | En, Es, Fr De, Ru, It | 6 | 99.8 [13] | 90.9 | 94.2 (-5.6) | 81.8 | 80.4 |
| FSD | EER (↓) | ASVspoof | En | 2 | 2.5 [13] | 18.5 | 13.5 | 13.1 (+10.6) | 18.3 |
| ER | ACC (↑) | IEMOCAP | En | 4 | 79.2 [13] | 42.1 | 44.3 | 49.9 | 50.2 (-29) |
| AcC | ACC (↑) | AccentDB | En | 9 | 99.5 [14] | 78.9 | 83.4 | 86.5 | 87.1 (-12.4) |
| SD | F1 (↑) | MUStARD | En | 2 | 64.6 [15] | 55.0 | 77.8 | 74.4 | 78.7 (+13.1) |
| GI D | F1 (↑) | VoxCeleb1 | En | 2 | 98.3 [17] | 86.2 | 87.3 | 91.6 (-6.7) | 86.2 |
| VAD | ACC (↑) | Google SC v2 & Freesound | En | 2 | 98.8 [18] | 96.6 | 96.9 | 98.3 (-0.5) | 98.1 |
| AuC | ACC (↑) | ESC-50 | ✖ | 50 | 97.0 [19] | 9.0 | 37.5 (-59.5) | 20.3 | 27.0 |
- SpeechPrompt v2는 여러 작업에서 경쟁력 있는 성능을 달성하며, 일부 작업에서 최첨단 상태의 결과를 보여준다(예: Lithuanian SCR, Arabic SCR, Sarcasm Detection).
- 프레임워크는 매개변수 효율적이어서 작업당 학습 가능한 음성-LM 매개변수의 비율이 0.1% 미만(~0.15M)이다.
- 학습 가능한 발화자는 대부분의 작업에서 성능을 향상시키며, 단위-레이블 매핑에 대한 SHAP 분석으로 설명 가능성을 일반적으로 높인다.
- 프롬프트 튜닝은 비영어권 또는 매우 다양한 음성 데이터에서 불안정성과 성능 편차를 보이는 경향이 있으며, 작업별 하이퍼파라미터 최적화는 수행되지 않았다.
- 프롬oting은 하나의 통합된 단순화된 파이프라인을 가능하게 하여 넓은 음성 분류 작업군에서 SOTA에 접근하거나 이를 따라잡을 수 있지만 일부 작업은 완전 감독 또는 사전 학습/미세 조정 방법보다 뒤처질 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.