[논문 리뷰] Stable Diffusion-based Data Augmentation for Federated Learning with Non-IID Data
Gen-FedSD는 사전 학습된 Stable Diffusion 모델을 사용하여 클라이언트별 합성 데이터를 생성하고, 로컬 FL 데이터를 IID에 더 가깝게 만들어 비 IID 분포에서 성능과 수렴을 개선합니다.
The proliferation of edge devices has brought Federated Learning (FL) to the forefront as a promising paradigm for decentralized and collaborative model training while preserving the privacy of clients' data. However, FL struggles with a significant performance reduction and poor convergence when confronted with Non-Independent and Identically Distributed (Non-IID) data distributions among participating clients. While previous efforts, such as client drift mitigation and advanced server-side model fusion techniques, have shown some success in addressing this challenge, they often overlook the root cause of the performance reduction - the absence of identical data accurately mirroring the global data distribution among clients. In this paper, we introduce Gen-FedSD, a novel approach that harnesses the powerful capability of state-of-the-art text-to-image foundation models to bridge the significant Non-IID performance gaps in FL. In Gen-FedSD, each client constructs textual prompts for each class label and leverages an off-the-shelf state-of-the-art pre-trained Stable Diffusion model to synthesize high-quality data samples. The generated synthetic data is tailored to each client's unique local data gaps and distribution disparities, effectively making the final augmented local data IID. Through extensive experimentation, we demonstrate that Gen-FedSD achieves state-of-the-art performance and significant communication cost savings across various datasets and Non-IID settings.
연구 동기 및 목표
- 비 IID 데이터 분포하에서 프라이버시를 보장하는 분산 학습 패러다임으로 연합학습의 동기를 제시한다.
- 합성 데이터를 생성하여 각 클라이언트의 데이터 분포를 글로벌 분포와 정렬함으로써 FL 성능 저하의 근본 원인을 해결한다.
- 각 클라이언트의 데이터 격차에 맞춘 고품질의 클래스-조건 이미지 합성을 Gen-FedSD로 제안한다.
- 클라이언트별 확산 모델 데이터 증강이 IID에 가까운 로컬 데이터를 생성하고 표준 데이터셋에서 FL 벤치마크를 향상시킴을 입증한다.
제안 방법
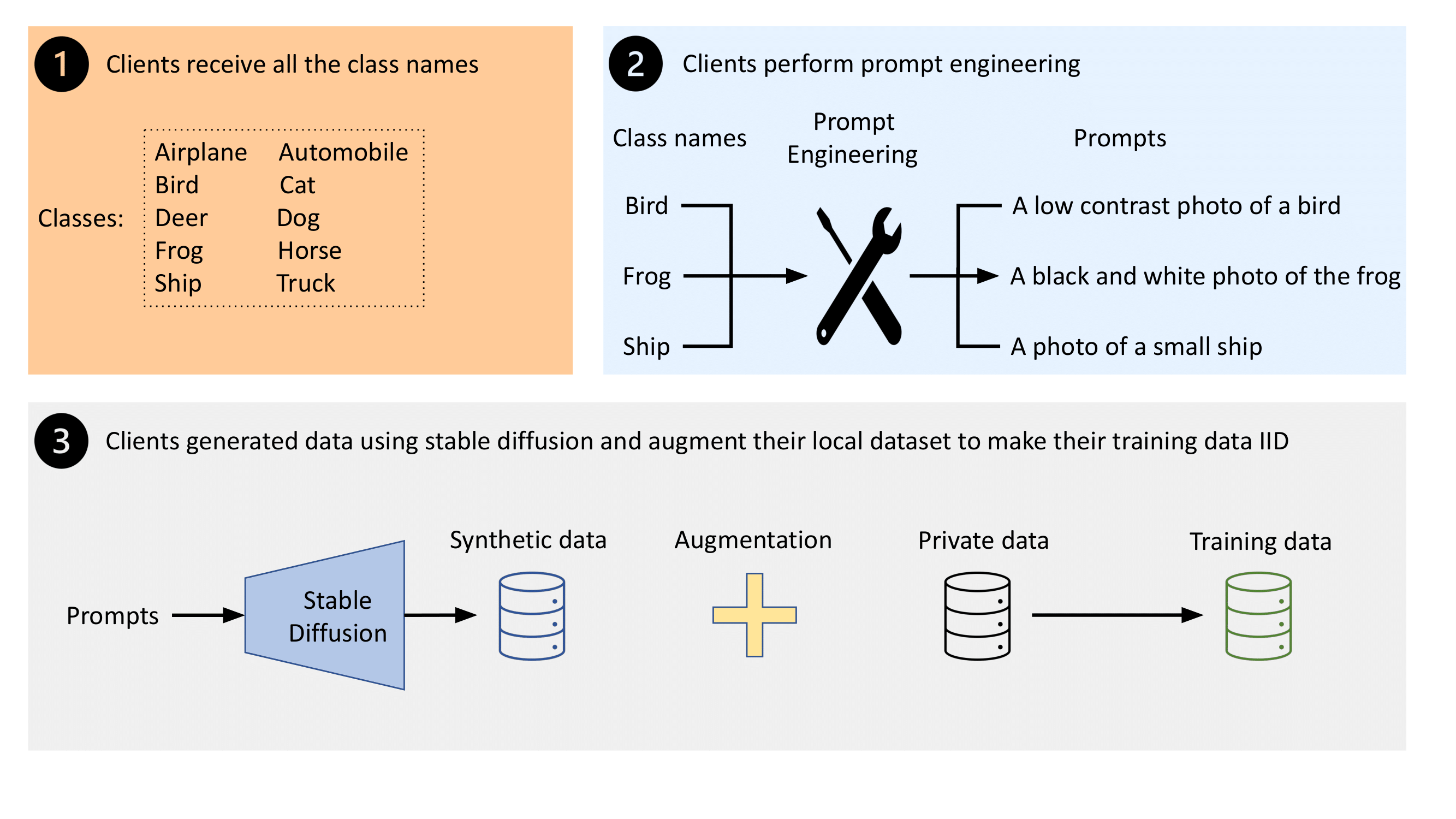
- 클라이언트는 서버로부터 전역 클래스 라벨을 받고 각 클래스를 설명하는 텍스트 프롬프트를 생성한다.
- 프롬프트에서 클래스 조건 이미지를 합성하기 위해 사전 학습된 Stable Diffusion 모델을 사용한다.
- 각 클라이언트마다 클래스별 카운트를 균형화하기 위한 합성 데이터를 생성하여 글로벌 분포에 대해 IID인 보강된 로컬 데이터셋을 얻는다.
- 보강된 데이터를 로컬 데이터와 결합하여 FL 모델을 학습시키고 클라이언트 드리프트를 줄인다.
- 성능에 대한 프롬프트 다양성의 영향을 연구하기 위해 서로 다른 프롬프트 설계(표준 프롬프트 vs. 다양 프롬프트)를 평가한다.
- 표준 FL 벤치마크(FedAvg, FedProx, FedNova, Scaffold)와 Gen-FedSD를 비교한다.
실험 결과
연구 질문
- RQ1클라이언트별 확산 기반 데이터 증강이 로컬 클라이언트 분포를 글로벌 데이터 분포와 정렬하여 FL의 비 IID 효과를 완화할 수 있는가?
- RQ2프롬프트 설계(다양한 프롬프트 vs. 고정 프롬프트)가 합성 데이터의 품질과 FL 성능에 어떤 영향을 미치는가?
- RQ3다양한 비 IID 설정에서 CIFAR-10 및 CIFAR-100에 걸친 Gen-FedSD의 정확도 향상 및 통신 비용 영향은 무엇인가?
- RQ4Gen-FedSD가 확산 모델의 온-디바이스 추론을 가능하게 하면서 프라이버시를 보존하는가?
주요 결과
- Gen-FedSD는 비 IID 설정에서 FL 벤치마크의 정확도를 상당히 높이며(예: 경미한 이질성에서 CIFAR-10은 최소 12%, CIFAR-100은 6%).
- 극단적인 비 IID에서 Gen-FedSD는 최소 20%의 정확도 향상(CIFAR-10)과 7%(CIFAR-100)를 보인다.
- Gen-FedSD는 수렴 속도를 높이고 평가된 데이터셋 전반에서 통신 비용을 감소시킨다.
- 프롬프트 다양성은 고정 프롬프트에 비해 Gen-FedSD 성능을 더 향상시킨다.
- 보강이 적용될 때 Gen-FedSD가 여러 베이스라인의 성능을 향상시키고 때로는 FedAvg를 능가한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.