[논문 리뷰] Suspicion-Agent: Playing Imperfect Information Games with Theory of Mind Aware GPT-4
본 논문은 구조화된 프롬프트와 마인드 이론(ToM) 추론을 활용하여 특수 훈련 없이 불완전 정보 게임을 플레이하는 GPT-4 기반 에이전트인 Suspicion-Agent를 제시하며, Leduc Hold’em에서의 경쟁력 있는 성능과 여러 게임에서의 질적 성공을 입증한다.
Unlike perfect information games, where all elements are known to every player, imperfect information games emulate the real-world complexities of decision-making under uncertain or incomplete information. GPT-4, the recent breakthrough in large language models (LLMs) trained on massive passive data, is notable for its knowledge retrieval and reasoning abilities. This paper delves into the applicability of GPT-4's learned knowledge for imperfect information games. To achieve this, we introduce extbf{Suspicion-Agent}, an innovative agent that leverages GPT-4's capabilities for performing in imperfect information games. With proper prompt engineering to achieve different functions, Suspicion-Agent based on GPT-4 demonstrates remarkable adaptability across a range of imperfect information card games. Importantly, GPT-4 displays a strong high-order theory of mind (ToM) capacity, meaning it can understand others and intentionally impact others' behavior. Leveraging this, we design a planning strategy that enables GPT-4 to competently play against different opponents, adapting its gameplay style as needed, while requiring only the game rules and descriptions of observations as input. In the experiments, we qualitatively showcase the capabilities of Suspicion-Agent across three different imperfect information games and then quantitatively evaluate it in Leduc Hold'em. The results show that Suspicion-Agent can potentially outperform traditional algorithms designed for imperfect information games, without any specialized training or examples. In order to encourage and foster deeper insights within the community, we make our game-related data publicly available.
연구 동기 및 목표
- 사전 학습된 LLM을 활용하여 특화된 과제 훈련 없이 불완전 정보 게임을 다루도록 동기를 제시한다.
- 관측 해석, 규칙 이해, 그리고 계획 수립을 가능하게 하는 모듈식 프롬프트 기반 아키텍처를 도입한다.
- 상대의 행동을 예측하고 영향을 주기 위해 마인드 이론(ToM) 추론을 통합한다.
- 여러 게임에 걸친 일반화를 입증하고 전통적인 불완전 정보 알고리즘과 비교한다.
제안 방법
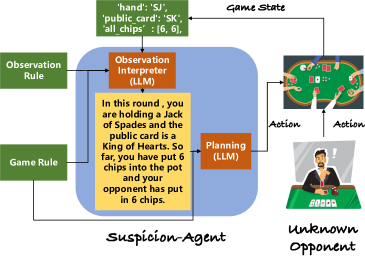
- 게임 해법을 관찰 해석기, 게임 규칙 이해, 계획, Reflexion, Evaluator로 모듈화한다.
- 저수준 게임 상태를 자연어 설명으로 변환하여 GPT-4에 입력한다.
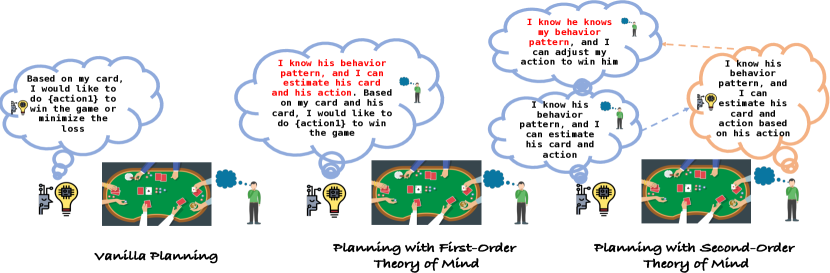
- 역사로부터 학습하고 행동을 계획하기 위해 Reflexion이 포함된 일반(plan) 계획 흐름을 사용한다.
- 상대방의 행동을 예측하고 계획을 조정하기 위해 1차(ToM) 및 2차(ToM) 계획을 도입한다.
- 상대의 패 강도와 계획에 대한 잠재적 응답을 추정하는 ToM 기반 계획을 구현한다.
- 세 가지 2인 게임에서 질적으로 평가하고 Leduc Hold’em에서는 CFR, NFSP, DMC, DQN을 상대로 정량적으로 평가한다.
실험 결과
연구 질문
- RQ1Suspicion-Agent가 특수한 훈련 없이 전통적인 불완전 정보 알고리즘과 일치하거나 능가할 수 있는가?
- RQ2ToM(일차 및 이차)이 다양한 상대에 대한 성능에 어떤 영향을 미치는가?
- RQ3GPT-4 기반 접근법이 Leduc Hold’em을 넘어 다수의 불완전 정보 게임으로 일반화될 수 있는가?
- RQ4상대 관찰 및 회고를 포함하는 것이 성능에 어떤 영향을 미치는가?
- RQ5다양한 ToM 순서가 전략적 효과 측면에서 어떻게 비교되는가?
주요 결과
- Suspicion-Agent, powered by GPT-4, outperforms baselines trained specifically on Leduc Hold’em in the presented experiments.
- GPT-4 based agents with ToM planning show superior adaptability to varied opponent strategies (CFR, DMC, NFSP) than vanilla planning.
- GPT-4 (GPT-4) significantly outperforms GPT-3.5 in the same setup, with GPT-3.5 showing a noticeable performance drop.
- Second-order ToM planning enables more aggressive and exploitative strategies (e.g., bluffing) leading to higher chip gains when facing bluff-prone opponents.
- Qualitative results demonstrate generalization to Coup and Texas Hold’em Limit without additional training or examples.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.