[논문 리뷰] T-RAG: Lessons from the LLM Trenches
논문은 Tree-RAG(T-RAG), 계층적 엔터티 트리와 온프렘 개인 거버넌스 문서에 대한 finetuned Llama-2 7B를 이용한 검색 보강 생성 시스템을 제시하며, 표준 RAG 및 finetuned baselines보다 정확도가 향상되었고 배운 교훈이 제시된다.
Large Language Models (LLM) have shown remarkable language capabilities fueling attempts to integrate them into applications across a wide range of domains. An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, limited computational resources and the need for a robust application that correctly responds to queries. Retrieval-Augmented Generation (RAG) has emerged as the most prominent framework for building LLM-based applications. While building a RAG is relatively straightforward, making it robust and a reliable application requires extensive customization and relatively deep knowledge of the application domain. We share our experiences building and deploying an LLM application for question answering over private organizational documents. Our application combines the use of RAG with a finetuned open-source LLM. Additionally, our system, which we call Tree-RAG (T-RAG), uses a tree structure to represent entity hierarchies within the organization. This is used to generate a textual description to augment the context when responding to user queries pertaining to entities within the organization's hierarchy. Our evaluations, including a Needle in a Haystack test, show that this combination performs better than a simple RAG or finetuning implementation. Finally, we share some lessons learned based on our experiences building an LLM application for real-world use.
연구 동기 및 목표
- 개인 조직 문서에 대한 실제 LLM 기반 QA 시스템을 입증한다.
- RAG를 finetuned 오픈소스 LLM과 결합해 사실 정확도와 응답 품질이 향상되는지 보인다.
- 엔터티 관련 질문에 응답을 보강하기 위해 트리 기반 맥락(엔터티 계층)을 도입한다.
- 정확하지만 과도하게 장황한 답변을 포착하기 위한 새로운 평가 지표(Correct-Verbose)를 제안한다.
- 생산 현장에서 LLM 기반 QA 시스템 배포로 얻은 실용적 교훈을 공유한다.
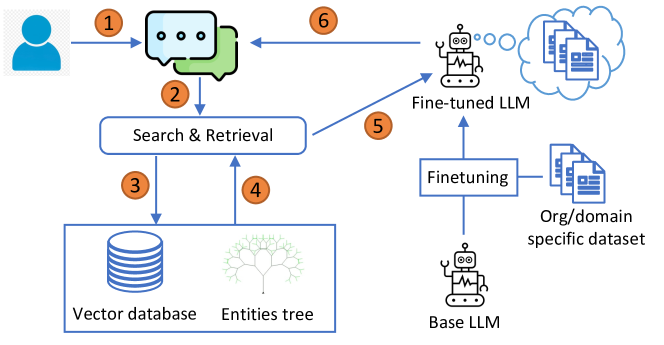
제안 방법
- Retrieval-Augmented Generation(RAG)과 finetuned 오픈소스 Llama-2 7B를 결합해 응답 생성을 수행한다.
- Tree-RAG(T-RAG): 표준 RAG 맥락에 조직의 계층 구조를 인코딩하는 엔터티 트리를 보강한다.
- 조직의 거버넌스 문서로부터 지시문 데이터셋을 생성하고 4-bit 양자화를 사용한 PEFT(QLoRA)로 LLM을 미세조정한다.
- 문서 청크에 대해 벡터 저장소(Chroma DB)와 MM Retrieval을 활용해 다양하고 관련성 높은 청크를 선택한다.
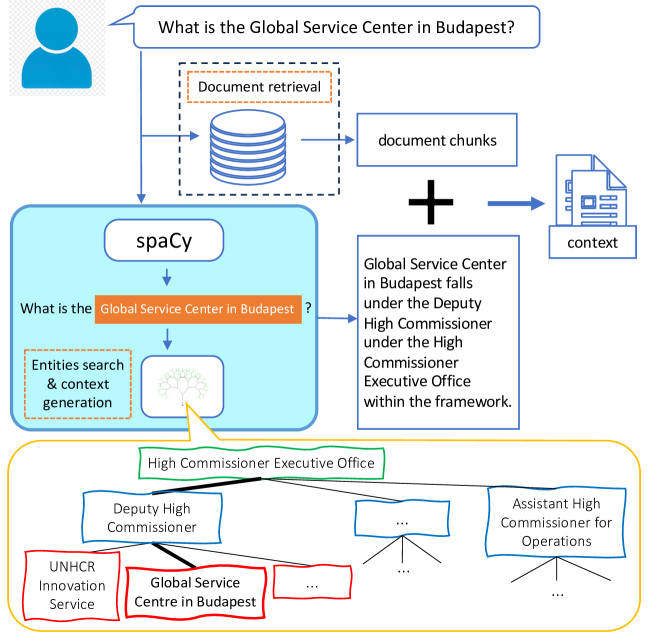
- 쿼리에 포함된 엔터티에 대한 맞춤형 조직 규칙이 반영된 spaCy 기반 NER를 통해 엔터티에 관한 텍스트 진술로 맥락을 보강한다.
- 조직의 계층 구조를 트리로 표현하고 이를 쿼리해 엔터티-포지션 정보를 추출해 엔터티가 언급될 때 맥락을 보강한다.
- Correct(C) 및 Correct-Verbose(CV) 응답에 대해 인간 평가를 이용해 평가한다.
실험 결과
연구 질문
- RQ1T-RAG 시스템이 기업 문서 QA에서 표준 RAG 또는 단독 파인튜닝 모델에 비해 사실 정확도와 관련성을 개선하는가?
- RQ2특히 복잡한 엔터티 관련 질문에서 엔터티 트리 맥락의 추가가 성능에 미치는 영향은 어떤가?
- RQ3맥락이 제한되거나 엔터티 계층 구조가 활용될 때 파인튜닝된 LLM과 RAG의 비교는 어떻게 되는가?
- RQ4제안된 Correct-Verbose 지표가 시스템 간 의미 있는 차별화를 제공하는가?
주요 결과
| 질문 세트 | N | C | CV | T | 퍼센트. | |
|---|---|---|---|---|---|---|
| RAG | 세트 1 | 17 | 9 | 0 | 9 | 52.9% |
| RAG | 세트 2 | 11 | 7 | 0 | 7 | 63.6% |
| RAG | 세트 3 | 9 | 4 | 1 | 5 | 55.6% |
| RAG | 전체 | 37 | 20 | 1 | 21 | 56.8% |
| Finetuned | 세트 1 | 17 | 11 | 1 | 12 | 70.6% |
| Finetuned | 세트 2 | 11 | 3 | 0 | 3 | 27.3% |
| Finetuned | 세트 3 | 9 | 5 | 0 | 5 | 55.6% |
| Finetuned | 전체 | 37 | 19 | 1 | 20 | 54.1% |
| T-RAG | 세트 1 | 17 | 9 | 4 | 13 | 76.5% |
| T-RAG | 세트 2 | 11 | 6 | 2 | 8 | 72.7% |
| T-RAG | 세트 3 | 9 | 6 | 0 | 6 | 66.7% |
| T-RAG | 전체 | 37 | 21 | 6 | 27 | 73.0% |
- T-RAG는 RAG(21/37) 또는 Finetuned(20/37)보다 전체적으로 더 높은 정확도(C 또는 CV) 응답을 달성한다(27/37).
- 트리 맥락은 특히 복잡한 질의에서 엔터티 관련 질문의 정확도를 크게 향상시킨다.
- 파인튜닝된 Llama-2와 엔터티 트리 맥락을 함께 포함하면 큰 이득이 발생한다(예: 간단한 질문 8/17에서 17/17로; 복잡한 8/22에서 15/22로).
- 엔터티-트리 맥락이 포함된 RAG는 조직 범주 내 엔터티의 맥락 오도 및 불일치를 감소시킨다.
- T-RAG는 더 길고 자세한(CV) 정답을 보여주지만 전체적으로 정답은 더 높다.
- 평가는 인간이 평가한 C 또는 CV 응답의 3개 사용자-질문 세트를 사용했다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.