[논문 리뷰] Temporal Perceiving Video-Language Pre-training
TemPVL은 짧은 비디오 스트림과 텍스트 스트림을 긴 시퀀스로 합친 텍스트-비디오 로컬라이제이션 사전 학습(Task)을 도입해, 시간 정보를 주석으로 요구하지 않으면서 미세한 시점 의존적 교차모달 정렬을 학습하고, 다수의 비디오-언어 태스크를 향상시킨다.
Video-Language Pre-training models have recently significantly improved various multi-modal downstream tasks. Previous dominant works mainly adopt contrastive learning to achieve global feature alignment across modalities. However, the local associations between videos and texts are not modeled, restricting the pre-training models' generality, especially for tasks requiring the temporal video boundary for certain query texts. This work introduces a novel text-video localization pre-text task to enable fine-grained temporal and semantic alignment such that the trained model can accurately perceive temporal boundaries in videos given the text description. Specifically, text-video localization consists of moment retrieval, which predicts start and end boundaries in videos given the text description, and text localization which matches the subset of texts with the video features. To produce temporal boundaries, frame features in several videos are manually merged into a long video sequence that interacts with a text sequence. With the localization task, our method connects the fine-grained frame representations with the word representations and implicitly distinguishes representations of different instances in the single modality. Notably, comprehensive experimental results show that our method significantly improves the state-of-the-art performance on various benchmarks, covering text-to-video retrieval, video question answering, video captioning, temporal action localization and temporal moment retrieval. The code will be released soon.
연구 동기 및 목표
- 비디오 프레임과 텍스트 설명 간의 미세한 시점적 및 의미적 정합성을 학습하려는 목표.
- 로컬라이제이션을 감독하기 위해 시간 주석이 필요하지 않은 사전 학습 태스크를 개발.
- 로컬라이제이션 주도 멀티모달 학습을 통해 다운스트림 비디오-언어 태스크에서 일반화 성능을 향상시킨다.
제안 방법
- 다중 모달 인코더를 결합하기 위해 비디오와 텍스트에 이중 인코더를 사용하고 다중 모달 인코더로 특징을 융합.
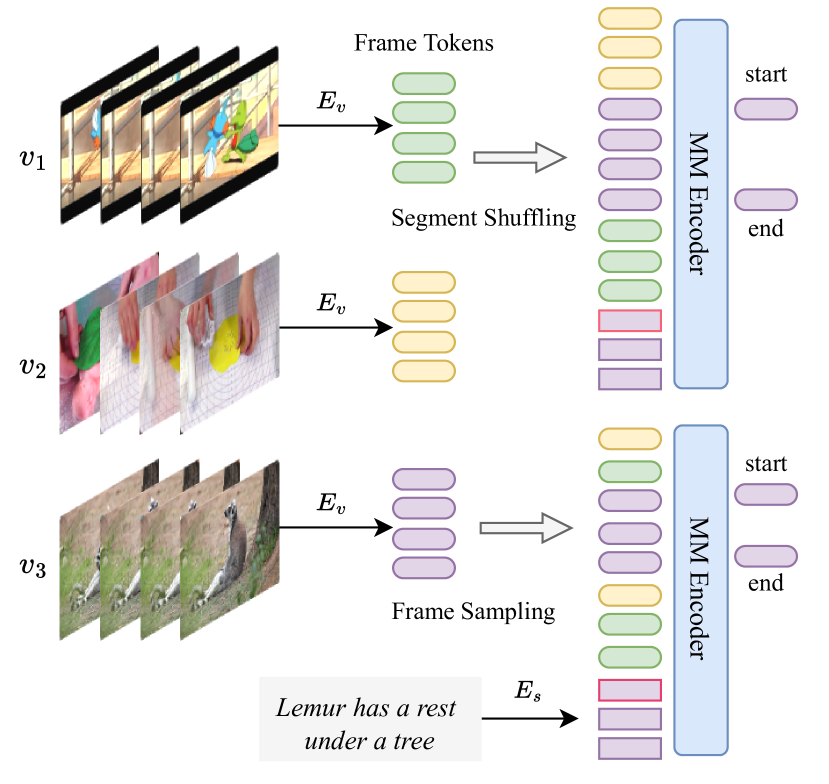
- 여러 비디오의 프레임 특징을 합쳐 긴 비디오 시퀀스를 구성하고 합쳐진 텍스트 토큰과 정렬.
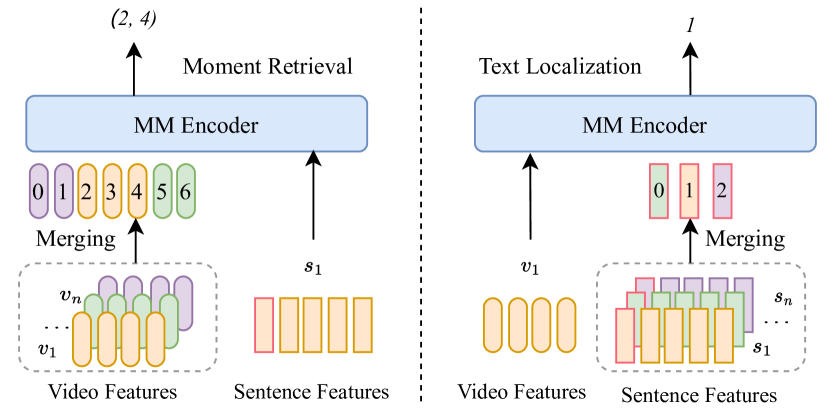
- 두 가지 로컬라이제이션 목표를 도입: 언어와 함께하는 모먼트 검색(moment retrieval)과 비디오와 함께하는 텍스트 로컬라이제이션.
- 마스킹된 언어 모델링과 제안된 로컬라이제이션 손실과 함께 텍스트-비디오 대조 목표를 적용.
- 합쳐진 비디오 프레임에 대한 시작/종료 경계를 예측하고 합쳐진 텍스트 토큰의 매칭 위치를 분류 기반 손실로 예측.
실험 결과
연구 질문
- RQ1로컬라이제이션 기반의 사전 학습 목표가 시간 주석 없이도 미세한 프레임-단어 정합성을 개선할 수 있는가?
- RQ2짧은 비디오-텍스트 쌍을 긴 시퀀스로 병합하는 것이 사전 학습 중 효과적인 모먼트 로컬라이제이션과 텍스트 로컬라이제이션을 가능하게 하는가?
- RQ3텍스트-비디오 로컬라이제이션이 제로샷 및 미세 조정 성능에 미치는 영향은 검색, QA, 자막 생성, 시간 로컬라이제이션 태스크에서 어떠한가?
- RQ4비디오 및 텍스트 시퀀스의 병합 전략이 로컬라이제이션 품질과 다운스트림 태스크 성능에 어떤 영향을 미치는가?
주요 결과
- TemPVL은 MSR-VTT와 DiDeMo에서 제로샷 텍스트-비디오 검색을 개선하고 MSVD와 LSMDC에서 이득을 얻는다.
- 본 방법은 강력한 베이스라인 대비 비디오 QA 및 비디오 자막 생성에서 개선을 보인다.
- 시간적 행동 로컬라이제이션 및 모먼트 검색은 추출된 특징과 로컬라이제이션 주도 사전 학습으로 이익을 얻고, 이전 방법들보다 향상된다.
- 비디오 합성에 대한 하드 샘플링 및 CLS 기반 텍스트 합병은 로컬라이제이션 정확도와 다운스트림 태스크 성능을 향상시킨다.
- 다양한 백본(SwinT, ViT)을 TVL과 함께 사용하면 작업 전반에 걸쳐 일관된 이득이 나타나Robust generalization
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.