[논문 리뷰] Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
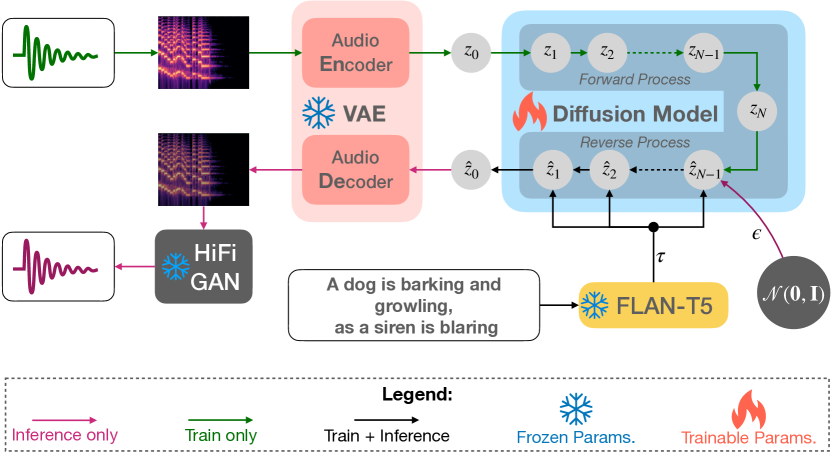
Tango는 텍스트 인코더로 얼어붙은 지시-조정 LLM(Flan-T5)을 텍스트 인코더로 사용하고 잠재 확산 모델과 함께 텍스트에서 오디오를 생성하여 prior 방법들보다 훨씬 작은 학습 데이터셋으로 AudioCaps에서 최첨단 성능을 달성합니다.
The immense scale of the recent large language models (LLM) allows many interesting properties, such as, instruction- and chain-of-thought-based fine-tuning, that has significantly improved zero- and few-shot performance in many natural language processing (NLP) tasks. Inspired by such successes, we adopt such an instruction-tuned LLM Flan-T5 as the text encoder for text-to-audio (TTA) generation -- a task where the goal is to generate an audio from its textual description. The prior works on TTA either pre-trained a joint text-audio encoder or used a non-instruction-tuned model, such as, T5. Consequently, our latent diffusion model (LDM)-based approach TANGO outperforms the state-of-the-art AudioLDM on most metrics and stays comparable on the rest on AudioCaps test set, despite training the LDM on a 63 times smaller dataset and keeping the text encoder frozen. This improvement might also be attributed to the adoption of audio pressure level-based sound mixing for training set augmentation, whereas the prior methods take a random mix.
연구 동기 및 목표
- 텍스트 인코더의 미세 조정을 최소화하면서 텍스트-투-오디오 생성을 촉진한다.
- TTA를 위한 동결된 텍스트 인코더로서의 지시-조정 LLM의 효과를 탐구한다.
- AudioCaps에서 Tango를 최첨단 기준선과 비교 평가한다.
- 데이터 세트 규모 감소와 표적 증강을 통한 데이터 효율적 학습을 보여준다.
제안 방법
- 텍스트 표현을 얻기 위해 Flan-T5-Large를 동결된 텍스트 인코더로 사용한다.
- 텍스트 임베딩에 조건화된 오디오 프라이어를 생성하기 위해 잠재 확산 모델을 채택한다.
- 멜-스펙트로그램 잠재 표현에서 파형을 재구성하기 위해 오디오 VAE와 HiFi-GAN 보코더를 훈련한다.
- 소스 음향을 더 잘 보존하기 위해 압력 레벨 기반의 오디오 혼합으로 학습 데이터를 증강한다.
- 텍스트 프롬프트로 확산 샘플링을 제어하기 위해 classifier-free 가이던스를 적용한다.
- 경쟁력 있는 성능을 유지하면서 훨씬 작게(63배 작음) 학습하는 AudioCaps 데이터셋에서 학습한다.
실험 결과
연구 질문
- RQ1지시-조정 LLM을 동결한 상태로 두면 확산 기반 오디오 생성기에 충분한 교차모달 가이던스를 제공할 수 있는가?
- RQ2압력-레벨 기반 데이터 증강이 TTA를 위한 교차 모달 개념 구성에 영향을 미치는가?
- RQ3AudioCaps에서 학습될 때 Tango가 Objective 및 주관적 지표에서 AudioLDM 및 다른 기준선과 어떻게 비교되는가?
- RQ4추론 단계와 가이던스 스케일이 오디오 품질과 관련성에 미치는 영향은 무엇인가?
주요 결과
| 모델 | 데이터 세트 | 텍스트 | #매개변수 | FD ↓ | KL ↓ | FAD ↓ | OVL ↑ | REL ↑ |
|---|---|---|---|---|---|---|---|---|
| Ground truth | - | - | - | 91.61 | 86.78 | - | - | - |
| DiffSound | AS+AC | ✓ | 400 M | 47.68 | 2.52 | 7.75 | - | - |
| AudioGen | AS+AC+8 others | ✓ | 285 M | - | 2.09 | 3.13 | - | - |
| AudioLDM-S | AC | ✗ | 181 M | 29.48 | 1.97 | 2.43 | - | - |
| AudioLDM-L | AC | ✗ | 739 M | 27.12 | 1.86 | 2.08 | - | - |
| AudioLDM-M-Full-FT | AS+AC+2 others | ✗ | 416 M | 26.12 | 1.26 | 2.57 | 79.85 | 76.84 |
| AudioLDM-L-Full | AS+AC+2 others | ✗ | 739 M | 32.46 | 1.76 | 4.18 | 78.63 | 62.69 |
| AudioLDM-L-Full-FT | AS+AC+2 others | ✗ | 739 M | 23.31 | 1.59 | 1.96 | - | - |
| Tango | AC | ✓ | 866 M | 24.52 | 1.37 | 1.59 | 85.94 | 80.36 |
- Tango는 AudioCaps 감독 신호만으로 동결된 Flan-T5 인코더를 사용하여 AudioCaps에서 FD(24.52), KL(1.37), FAD(1.59)에서 최첨단을 달성한다.
- Tango는 주관적 점수도 높게 얻는다(OVL 85.94, REL 80.36), 이는 뛰어난 음질과 텍스트 관련성을 시사한다.
- 63배 작은 학습 데이터세트를 사용하면서도 Tango는 AudioLDM-L을 능가하고 여러 AudioLDM-FT 변형을 근접하거나 능가한다.
- 상대 압력 기반 증강은 무작위 증강보다 더 나은 객관적 지표를 얻는다(FD 24.52 vs 25.84; KL 1.37 vs 1.38; FAD 1.59 vs 2.72).
- 추론 단계 증가와 적절한 classifier-free 가이던스(스케일 약 3)가 Tango의 성능을 향상시키며 100에서 200단계 사이에서 큰 이득이 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.