[논문 리뷰] The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World
AS-1B라는 억 개의 영역으로 구성된 오픈 월드 데이터셋과 All-Seeing Model (ASM)이라는 위치 인지 기반 비전-언어 기초 모델을 소개한다. ASM은 팬옵틱 인식과 이해를 위한 강력한 제로샷 능력을 갖춘 모델이다.
We present the All-Seeing (AS) project: a large-scale data and model for recognizing and understanding everything in the open world. Using a scalable data engine that incorporates human feedback and efficient models in the loop, we create a new dataset (AS-1B) with over 1 billion regions annotated with semantic tags, question-answering pairs, and detailed captions. It covers a wide range of 3.5 million common and rare concepts in the real world, and has 132.2 billion tokens that describe the concepts and their attributes. Leveraging this new dataset, we develop the All-Seeing model (ASM), a unified framework for panoptic visual recognition and understanding. The model is trained with open-ended language prompts and locations, which allows it to generalize to various vision and language tasks with remarkable zero-shot performance, including region-text retrieval, region recognition, captioning, and question-answering. We hope that this project can serve as a foundation for vision-language artificial general intelligence research. Models and the dataset shall be released at https://github.com/OpenGVLab/All-Seeing, and demo can be seen at https://huggingface.co/spaces/OpenGVLab/all-seeing.
연구 동기 및 목표
- 풍부한 의미와 설명을 갖춘 대규모 영역 수준 데이터셋을 구축하여 오픈 월드 판옵틱 시각 인식 및 이해를 향상시킨다.
- 영역 수준 정보에 대해 추론하고 판별적 및 생성적 작업을 모두 지원하는 통합 비전-언어 모델(ASM)을 만든다.
- 표준 시각 및 시각-언어 벤치마크에서 제로샷 및 미세조정 성능의 향상을 입증한다.
제안 방법
- 데이터–인간–모델 루프를 통해 1B 영역 주석, 3.5M 개념, 132.2B 토큰, 그리고 3.3B VQA 쌍을 갖는 AS-1B 데이터셋을 개발한다.
- 경계 박스, 마스크 및 점 집합을 사용하여 영역 기반 특성을 추출하는 위치 인식 이미지 토크나이저를 제안한다.
- 공유 가중치를 가진 판별적/생성적 비전-언어 작업의 통합 처리를 가능하게 하는 LLM 기반 디코더를 채택한다.
- 생성 손실과 영역-텍스트 정렬/대조 손실을 결합한 학습 목표를 도입하여 판별적 작업에 CLIP과 유사하게 작동하도록 한다.
- 정확한 영역 태깅을 위해 CLIP, CLIPSeg를 사용하고 이후 ASM으로 확장하는 영역-텍스트 정렬 정제 파이프라인을 구현한다.
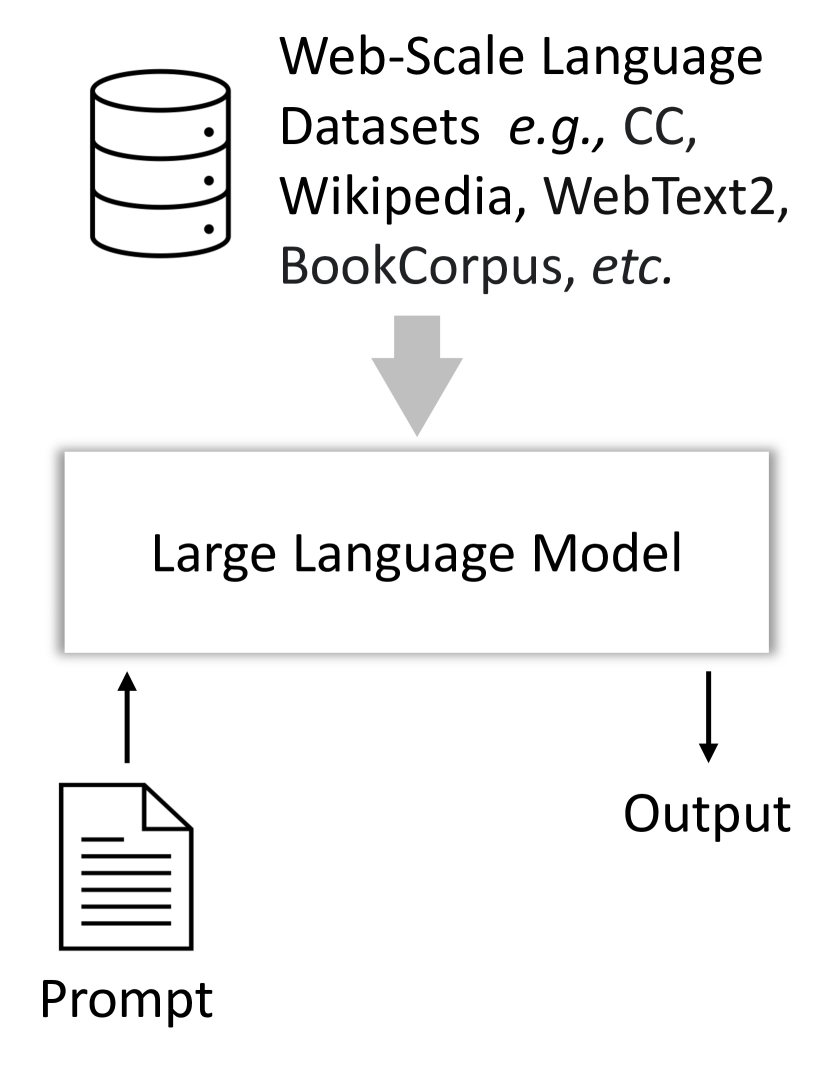
실험 결과
연구 질문
- RQ1영역 수준의 오픈 월드 팬옵틱 데이터셋이 견고하고 영역 인지 이해와 생성을 가능하게 할 수 있는가?
- RQ2통합 위치 인식 비전-언어 모델이 제로샷 및 미세조정 설정에서 다양한 비전-언어 작업으로 일반화되는가?
- RQ3반복적인 데이터-인간-모델 루프가 데이터 품질과 모델 성능에 미치는 영향은 무엇인가?
주요 결과
- AS-1B는 1.2B 영역, 3.5M 개념, 132.2B 토큰 및 3.3B VQA 쌍을 포함하여 넓은 오픈 월드 시맨틱스를 가능하게 한다.
- ASM은 표준 벤치마크에서 제로샷 및 미세조정 성능 향상을 달성하며, 영역 수준 인식을 포함한 기존 모델들보다 우수하다.
- ASM은 COCO와 LVIS에서 각각 제로샷 영역 인식 작업에서 CLIP보다 10.4 및 14.3 mAP 우수하다.
- 데이터 엔진은 개선된 모델을 데이터 생성 및 라벨링으로 다시 피드백해 데이터 품질을 반복적으로 향상시킨다.
- 단일 아키텍처 내에서 영역-텍스트 검색부터 캡션 작성 및 VQA에 이르는 다양한 작업을 지원한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.