[논문 리뷰] The Semantic Scholar Open Data Platform
논문은 Semantic Scholar Open Data Platform 및 Semantic Scholar Academic Graph (S2AG)를 설명하고 데이터 파이프라인, 시맨틱 기능, 공용 API/데이터셋을 개략적으로 제시한다.
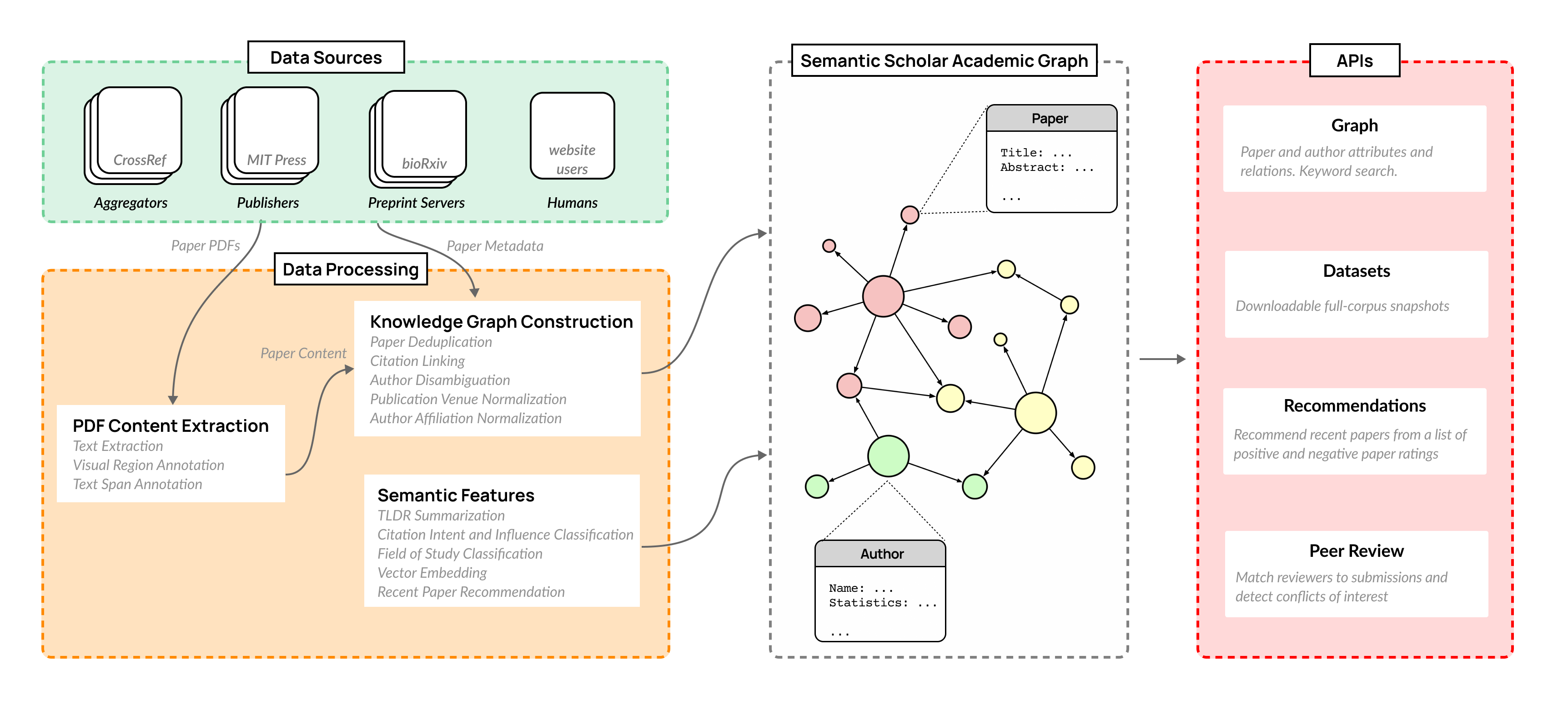
The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
연구 동기 및 목표
- 정보 과부하를 관리하기 위해 자동화된 학술 데이터 도구의 필요성을 제시한다.
- 대규모의 비모호화된 지식 그래프로서의 Semantic Scholar Open Data Platform과 S2 Academic Graph (S2AG)를 설명한다.
- 학술 콘텐츠를 추출하고 구조화하기 위한 데이터 처리 파이프라인, 데이터 소스 및 방법을 설명한다.
- S2AG 및 시맨틱 기능에 접근할 수 있는 공개 API와 다운로드 가능한 데이터 세트를 상세히 설명한다.
- 시맨틱 라벨링, 개인화 및 협업 기반 주석을 향상시키기 위한 향후 방향을 개요한다.
제안 방법
- 50개가 넘는 소스의 메타데이터 및 PDF를 수집하여 비모호화된 지식 그래프(S2AG)를 구축한다.
- PDF 콘텐츠 추출을 수행하여 구조화된 텍스트, 섹션, 그림, 표 및 참고 문헌을 얻는다.
- 레이아웃 및 시맨틱 라벨로 추출된 콘텐츠를 보강하기 위해 시각 영역 주석 및 텍스트 스팬 주석을 사용한다.
- 고유 엔티티를 구성하기 위해 중복 제거(S2APLER), 저자 비모호화(S2AND), 소속 정규화(S2AFF)를 적용한다.
- TLDR 요약, 인용 의도/영향, 연구 분야 분류, 논문 임베딩(SPECTER), 추천 등 시맨틱 기능을 생성한다.
- 프로그래밍 방식 접근을 위한 API 및 월별 데이터셋 스냅샷(논문, 저자, 인용, 임베딩, TLDR, 학술지, S2ORC)을 제공한다.
실험 결과
연구 질문
- RQ1다양한 데이터 소스에서 대규모의 개방적이고 비모호화된 학술 그래프(S2AG)를 어떻게 구축할 수 있는가?
- RQ2과학 문헌의 발견과 이해를 향상시키기 위해 어떤 시맨틱 기능(요약, 임베딩, 분류)을 추가할 수 있는가?
- RQ3연구자들이 API 및 데이터 세트를 통해 포괄적인 학술 데이터 및 시맨틱 주석에 프로그래밍 방식으로 어떻게 접근하고 다운로드할 수 있는가?
- RQ4지식 그래프를 지속적으로 업데이트하려면 어떤 구성 요소와 파이프라인이 필요한가?
주요 결과
- S2AG은 205M 논문, 80M 저자, 550k 학술지, 580M 논문-저자 간선, 2.4B 인용 간선(설계된 파이프라인 기준)으로 대규모 학술 그래프에 근접한다.
- 플랫폼은 구조적으로 구문 해석된 텍스트, TLDR 요약, 벡터 임베딩(SPECTER), 추천 등 고급 시맨틱 기능을 제공한다.
- 파이프라인은 50개가 넘는 데이터 소스, 정교한 PDF 콘텐츠 추출(Text Extraction, Visual Region Annotation, Text Span Annotation), 다중 정규화/비모호화 모델(S2APLER, S2AND, S2AFF)을 통합한다.
- 공개 API와 월간 데이터 세트를 제공하여 핵심 메타데이터, 초록, 전체 텍스트(권한이 있는 경우), 인용, 임베딩, TLDR에 접근할 수 있게 한다.
- 시맨틱 처리에 다양한 모델과 데이터 세트를 제공하며, TLDR (CatTS), 인용 의도를 위한 SciCite, 연구 분야용 S2FOS, SPECTER 임베딩, 동적 추천 등을 포함한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.