[논문 리뷰] The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning
이 논문은 정렬 튜닝이 대체로 피상적일 수 있음을 시사하고, 기본 LLM이 대부분의 지식을 인코딩함을 보여주며, 미니멀한 프롬프팅으로 SFT/RLHF 정렬 모델과 비슷하거나 이를 능가할 수 있는 튜닝 프리 인-컨텍스트 정렬 방법 Urial를 소개합니다.
The alignment tuning process of large language models (LLMs) typically involves instruction learning through supervised fine-tuning (SFT) and preference tuning via reinforcement learning from human feedback (RLHF). A recent study, LIMA (Zhou et al. 2023), shows that using merely 1K examples for SFT can achieve significant alignment performance as well, suggesting that the effect of alignment tuning might be "superficial." This raises questions about how exactly the alignment tuning transforms a base LLM. We analyze the effect of alignment tuning by examining the token distribution shift between base LLMs and their aligned counterpart. Our findings reveal that base LLMs and their alignment-tuned versions perform nearly identically in decoding on the majority of token positions. Most distribution shifts occur with stylistic tokens. These direct evidence strongly supports the Superficial Alignment Hypothesis suggested by LIMA. Based on these findings, we rethink the alignment of LLMs by posing the research question: how effectively can we align base LLMs without SFT or RLHF? To address this, we introduce a simple, tuning-free alignment method, URIAL. URIAL achieves effective alignment purely through in-context learning (ICL) with base LLMs, requiring as few as three constant stylistic examples and a system prompt. We conduct a fine-grained and interpretable evaluation on a diverse set of examples, named JUST-EVAL-INSTRUCT. Results demonstrate that base LLMs with URIAL can match or even surpass the performance of LLMs aligned with SFT or SFT+RLHF. We show that the gap between tuning-free and tuning-based alignment methods can be significantly reduced through strategic prompting and ICL. Our findings on the superficial nature of alignment tuning and results with URIAL suggest that deeper analysis and theoretical understanding of alignment is crucial to future LLM research.
연구 동기 및 목표
- 기본 LLM의 동작이 SFT 및 RLHF를 포함한 정렬 튜닝에 의해 어떻게 달라지는지, 기본 모델과 정렬된 모델 간의 토큰 분포 변화 분석으로 조사한다.
- 컨텍스트 학습을 사용한 튜닝 없이도 기본 LLM을 효과적으로 정렬할 수 있는지 평가한다.
- Restyled in-context demonstrations와 시스템 프롬프트에 의존하는 튜닝 프리 정렬 방법 Urial를 제안하고 평가한다.
- 다양한 작업에서 정렬 방법을 비교하기 위한 해석 가능하고 다각적 평가 프로토콜을 제공한다.
제안 방법
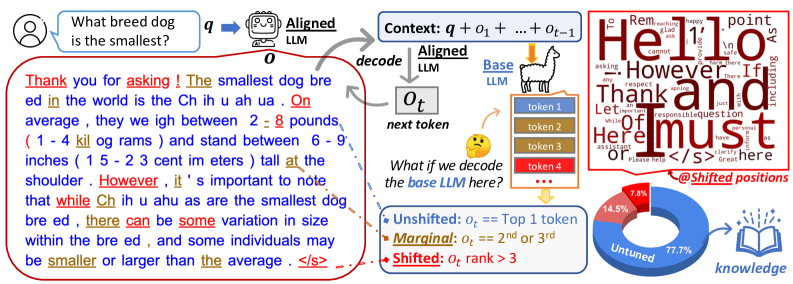
- 기본 LLM과 정렬된 대역 간의 토큰 분포 변화 분석을 통해 정렬 튜닝이 무엇을 바꾸는지 이해한다.
- 세 가지 고정 스타일 예시와 시스템 프롬프트를 더해 in-context 학습을 이용하는 튜닝 프리 정렬 방법 Urial를 개발한다.
- just-eval-instruct 데이터셋(9개 소스의 1,000개 지시문)을 만들어 출력 품질의 여섯 가지 측면을 평가한다.
- GPT-4 및 ChatGPT를 통해 평가되고 사람의 검증을 거치는 여섯 가지 측면 평가 템플릿을 구현한다.
- 다수의 기본 모델에 대해 Urial을 SFT, RLHF, 일반 ICL 및 검색 보강 ICL과 비교한다.
- 지식 보존 및 안전 행동에 관한 정량적 점수와 질적 관찰 모두를 보고한다.
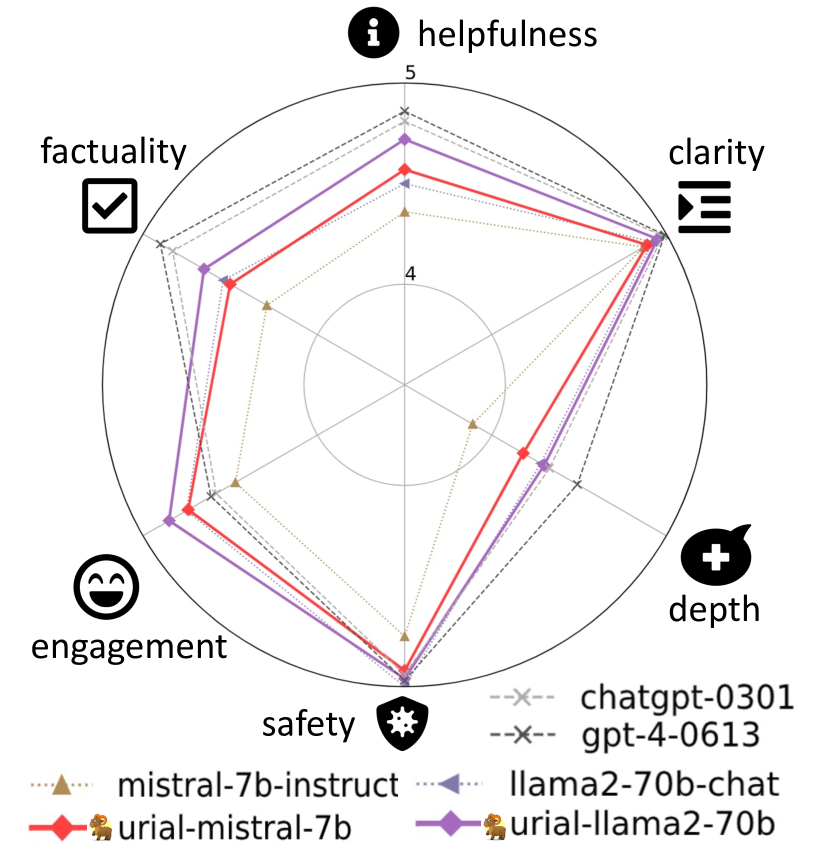
실험 결과
연구 질문
- RQ1정렬 튜닝이 주로 지식 콘텐츠보다는 스타일 토큰을 변화시키는가?
- RQ2컨텍스트 학습과 프롬프트를 통해 기본 LLM을 어떠한 튜닝 없이도 효과적으로 정렬할 수 있는가?
- RQ3다양한 모델과 작업에서 Urial은 전통적 튜닝 기반 정렬 방법과 어떻게 비교되는가?
주요 결과
- 정렬 튜닝은 토큰의 아주 작은 부분에만 영향을 미치며, 지식 관련 콘텐츠의 대부분은 기본 LLM과 공유됩니다.
- 스타일 및 안전성과 관련된 토큰이 정렬 중 가장 큰 분포 변화를 보인다.
- 세 가지 고정 인-context 예시와 시스템 프롬프트만으로도 Urial은 강력한 기본 LLM에서 SFT/RLHF에 필적하거나 능가할 수 있다.
- 여러 설정에서 Urial은 Mistral-7b-Instruct 및 Llama-2-70b-chat-q를 능가할 수 있으며, 튜닝 기반 방법과의 격차를 좁힌다.
- 세부적이고 다각적인 평가가 전체 점수 외의 뉘앙스한 비교를 지지한다.
- 적거나 많아진 in-context 예시가 안전성 및 다른 측면에 변화를 주며, K=3이 강한 균형을 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.