[논문 리뷰] Titans: Learning to Memorize at Test Time
타이탄스(Titans)는 테스트 시점에 암기하는 깊은 신경망식 장기 기억 모듈을 도입하고, 이것을 핵심 주의(attention-based) 아키텍처와 통합하여 극히 긴 맥락을 처리합니다. 이는 다양한 작업에서 트랜스포머(Transformers)와 선형 순환 모델을 능가합니다.
Over more than a decade there has been an extensive research effort on how to effectively utilize recurrent models and attention. While recurrent models aim to compress the data into a fixed-size memory (called hidden state), attention allows attending to the entire context window, capturing the direct dependencies of all tokens. This more accurate modeling of dependencies, however, comes with a quadratic cost, limiting the model to a fixed-length context. We present a new neural long-term memory module that learns to memorize historical context and helps attention to attend to the current context while utilizing long past information. We show that this neural memory has the advantage of fast parallelizable training while maintaining a fast inference. From a memory perspective, we argue that attention due to its limited context but accurate dependency modeling performs as a short-term memory, while neural memory due to its ability to memorize the data, acts as a long-term, more persistent, memory. Based on these two modules, we introduce a new family of architectures, called Titans, and present three variants to address how one can effectively incorporate memory into this architecture. Our experimental results on language modeling, common-sense reasoning, genomics, and time series tasks show that Titans are more effective than Transformers and recent modern linear recurrent models. They further can effectively scale to larger than 2M context window size with higher accuracy in needle-in-haystack tasks compared to baselines.
연구 동기 및 목표
- 단기 주의와 장기 기억을 결합한 기억 시스템 설계에 대한 동기를 제시한다.
- 놀람 기반 기제에 따라 테스트 시점에 업데이트되는 신경학적 장기 기억을 제안한다.
- 빠르고 병렬화 가능한 방식으로 장기 기억을 학습하고 검색하는 방법을 보여준다.
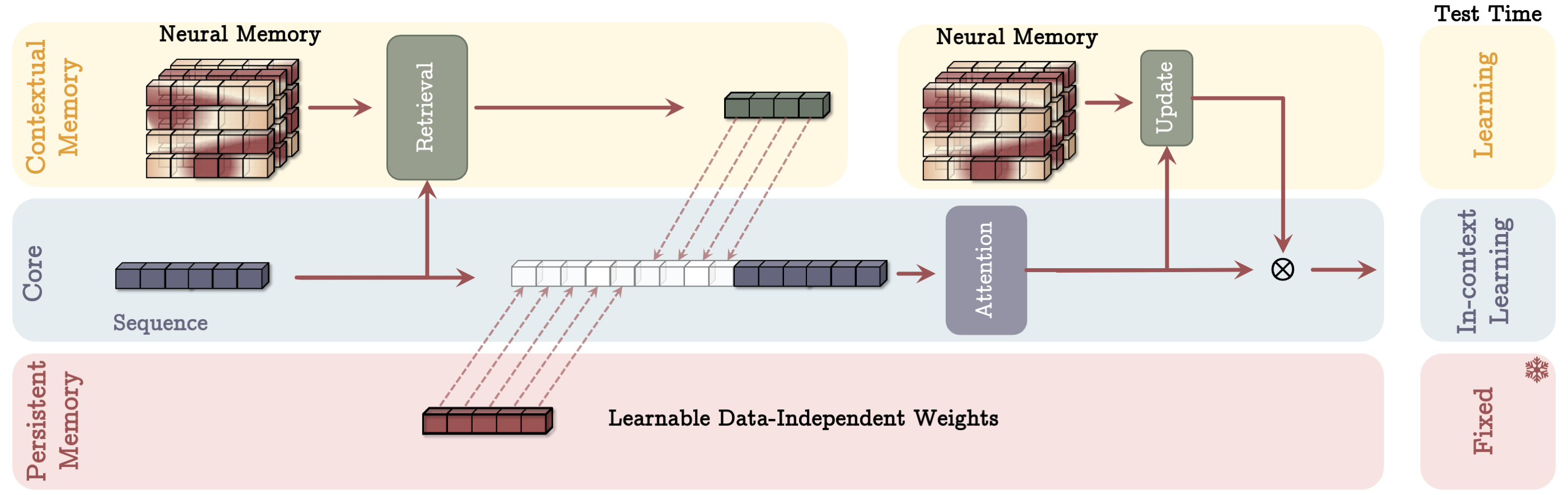
- Core, Long-term Memory, Persistent Memory의 세 가지 분기로 구성된 Titans 아키텍처에 장기 기억을 통합한다.
- 다양한 작업에서 2 million tokens를 넘는 맥락 창으로의 확장 가능성을 보여준다.
제안 방법
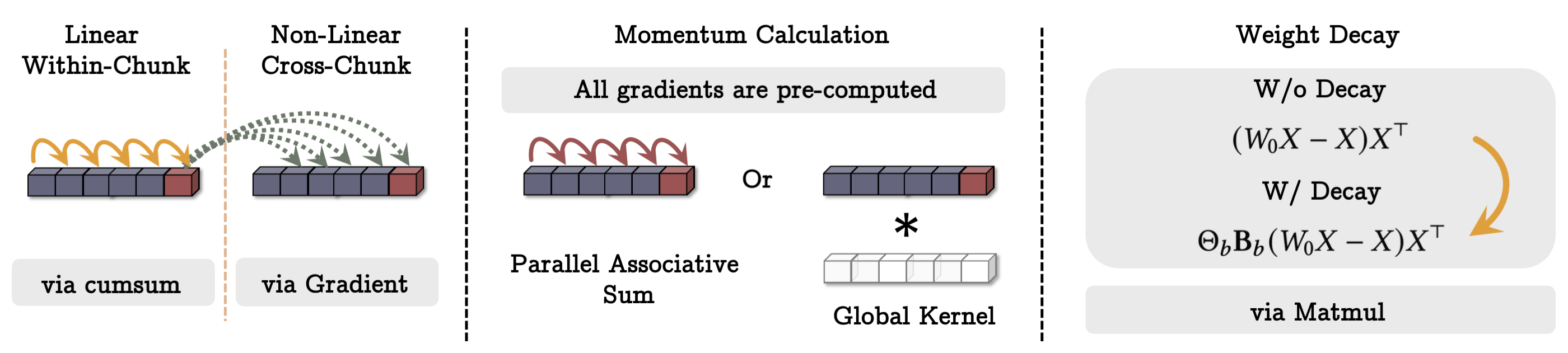
- 놀람 주도 업데이트를 사용하여 과거 정보를 매개변수에 저장하는 신경학적 장기 기억 모듈을 도입한다.
- 놀람을 정의하는 것을 손실의 입력에 대한 그래디언트를 사용하고 데이터 의존적 소멸로 과거 놀람과 순간적 놀람으로 분해한다.
- 키-값 쌍에 대한 연상 기억 손실을 이용해 메모리를 학습하는 메타 러닝 스타일의 내부 루프를 사용한다.
- 병렬화를 위한 미니배치 경사 하강과 행렬곱(matmul) 기반 계산을 활용하는 빠르고 텐서화된 학습 체계를 제안한다.
- 작업 관련이고 데이터와 무관한 지속적 기억(persistent memory)을 도입하고 기억이 컨텍스트, 레이어, 게이티드 분기로 사용되는 세 가지 Titans 변형을 제시한다.
실험 결과
연구 질문
- RQ1장기 의존성에 효과적인 기억 구조는 무엇인가?
- RQ2장기 시퀀스에서 기억화와 망각을 가장 잘 지원하는 기억 업데이트 메커니즘은 무엇인가?
- RQ3현재 작업에 대해 저장된 정보를 효율적으로 추출하는 검색/회수 프로세스는 무엇인가?
- RQ4학습/추론 속도를 저하시키지 않으면서 메모리 모듈을 아키텍처에 어떻게 효율적으로 통합할 수 있는가?
- RQ5깊은 신경망 기반 장기 기억이 견고한 장기 연구를 위해 필요한가?
주요 결과
- 타이탄스는 언어 모델링, 추론, 유전체학, 시계열 작업에서 현대 순환 모델과 그 하이브리드들을 능가합니다.
- 타이탄스는 기준 모델 대비 바늘-건초 더미(needle-in-haystack) 작업에서 더 높은 정확도로 2M 토큰을 넘어서는 맥락 윈도우로 확장될 수 있습니다.
- 장기 기억 모듈은 놀람 주도 업데이트와 망각 메커니즘을 사용하여 기억 관리와 일반화 성능을 향상시킵니다.
- 텐서화된 미니배치 업데이트를 통한 병렬화 학습은 심층 메모리의 효율적인 학습을 가능하게 합니다.
- 지속적 기억은 입력에 의존하지 않는 작업 지식을 제공하여 학습과 검색을 안정화합니다.
- 세 가지 Titans 변형(Memory as Context, Memory as Gate, 그리고 게이팅 기반 디자인)은 효율성과 효과성 간의 트레이드오프를 제공합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.