[논문 리뷰] Towards Verifiable Generation: A Benchmark for Knowledge-aware Language Model Attribution
본 논문은 KaLMA를 정의하고, BioKaLMA를 BioKGs에 대해 1,085개의 질문으로 구축하며, Conscious Incompetence를 도입하고, 지식 기반 귀속에서 개선의 여지가 있음을 보여주는 검색 기반의 완전 자동 평가 프레임워크를 제시한다.
Although achieving great success, Large Language Models (LLMs) usually suffer from unreliable hallucinations. Although language attribution can be a potential solution, there are no suitable benchmarks and evaluation metrics to attribute LLMs to structured knowledge. In this paper, we define a new task of Knowledge-aware Language Model Attribution (KaLMA) that improves upon three core concerns with conventional attributed LMs. First, we extend attribution source from unstructured texts to Knowledge Graph (KG), whose rich structures benefit both the attribution performance and working scenarios. Second, we propose a new ``Conscious Incompetence" setting considering the incomplete knowledge repository, where the model identifies the need for supporting knowledge beyond the provided KG. Third, we propose a comprehensive automatic evaluation metric encompassing text quality, citation quality, and text citation alignment. To implement the above innovations, we build a dataset in biography domain BioKaLMA via evolutionary question generation strategy, to control the question complexity and necessary knowledge to the answer. For evaluation, we develop a baseline solution and demonstrate the room for improvement in LLMs' citation generation, emphasizing the importance of incorporating the "Conscious Incompetence" setting, and the critical role of retrieval accuracy.
연구 동기 및 목표
- 비구조적 텍스트에서 지식 그래프까지 귀속 소스를 확장하여 구조화된 지식을 활용한다.
- 모델이 지식 격차를 인지하고 부재 지식을 [NA]로 인용하도록 하여 커버리지 격차를 해소한다.
- 참고 자료 없이 텍스트 품질, 인용 품질, 텍스트-인용 정렬을 포괄적으로 평가하는 자동 평가 프레임워크를 제안한다.
- 생애 도메인에서 제어 가능한 자동 평가를 용이하게 하기 위해 BioKaLMA를 구축한다.
제안 방법
- 생성의 기반을 지식 그래프로 두고, 식별된 엔티티를 둘러싼 원-홉 서브그래프를 WikiData에서 검색한다.
- 정확 일치 이웃 구조를 사용하여 엔티티를 판별하기 위한 검색 및 재정렬 파이프라인을 구현한다.
- 검색된 KG와 질문을 포함하는 프롬프트로, 시연을 통한 원샷 in-context 학습을 사용하여 생성 모델을 학습시킨다.
- KG에 지식이 누락된 경우 문장을 [NA]로 매핑하도록 Conscious Incompetence를 도입한다.
- 일관성, 응집성, 유창성, 관련성에 걸쳐 참조 없이 NLG 평가자(GPTScore)로 텍스트 품질을 평가한다.
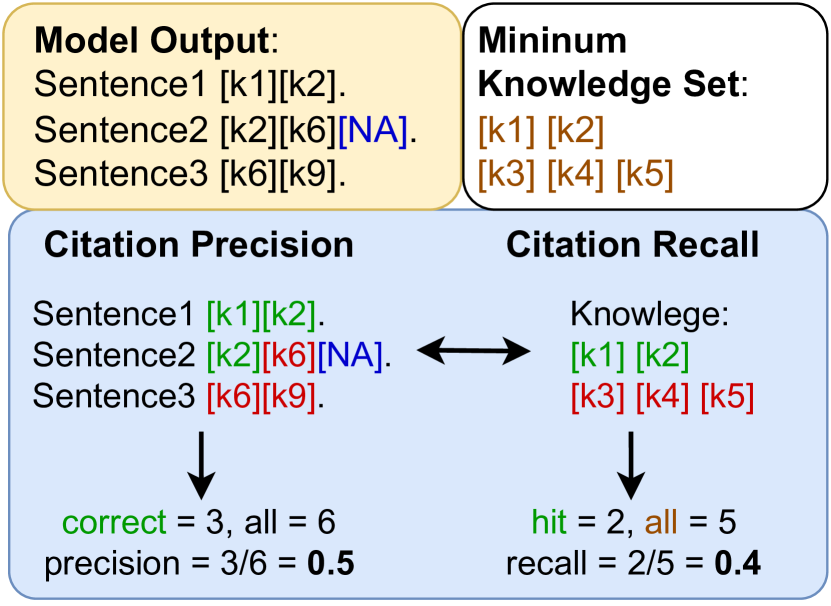
- 최소 지식 집합과 비교한 정오성, 정밀도, 재현율, F1에 대해 인용을 평가하고, NLI 기반 함의 검사로 텍스트-인용 정렬을 평가한다.
![Figure 1: A demonstration of our task set up. Given a question, the system generates answers attributed from a retrieved knowledge graph. The underlines in question are the retrieved entities, and the underlines in outputs are the citations. [NA] is the “Not Applicable Citation”.](https://ar5iv.labs.arxiv.org/html/2310.05634/assets/x1.png)
실험 결과
연구 질문
- RQ1KaLMA에서 귀속 소스를 비구조적 문서에서 지식 그래프로 확장할 수 있는 방법은 무엇인가?
- RQ2제공된 KG에 포함되지 않은 지식 격차를 모델이 식별하고 Conscious Incompetence 설정으로 표시할 수 있는가?
- RQ3검색 정확도와 KG 커버리지가 생성 텍스트 및 인용 품질에 어떤 영향을 미치는가?
- RQ4금본 금참? gold references 없이 텍스트 품질, 인용 품질, 텍스트-인용 정렬을 자동으로 어떻게 평가할 수 있는가?
- RQ5생애 도메인에서 지식 인식형 언어 모델 귀속의 벤치마크로서 BioKaLMA의 효과는 무엇인가?
주요 결과
- GPT-4는 대부분의 지표에서 최상의 전반적 인용 품질을 달성하며, 정렬이 더 높고 상대적으로 높은 일관성 및 응집성을 보인다.
- 모든 모델은 인용의 정밀도와 재현율에서 개선의 여지가 있으며, KG 기반 귀속으로의 접지를 강조한다.
- 검색 정확도가 인용 품질에 크게 영향을 미치며, 재현율은 정밀도보다 검색 오류에 더 민감하다.
- Conscious Incompetence는 지식 격차를 드러내고 커버리지가 제한될 때 신뢰성을 높이는 데 도움이 된다.
- 텍스트-인용 정렬은 모델 크기와 상관관계가 있어, 더 큰 모델일수록 더 높은 정렬을 보인다.
- 일부 기준선에 대해 정렬 및 인용 품질의 자동 평가 지표가 인간 판단과 상관관계를 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.