[논문 리뷰] UniWorld: Autonomous Driving Pre-training via World Models
UniWorld는 라벨이 필요 없는 다중 카메라 통합 사전 학습 프레임워크를 도입하여 라벨이 없는 이미지-LiDAR 쌍으로부터 4D 기하학적 점유 월드 모델을 학습하고 모션 예측, 다중 카메라 3D 물체 탐지, 그리고 주변 시맨틱 씬 완성을 향상시킵니다.
In this paper, we draw inspiration from Alberto Elfes' pioneering work in 1989, where he introduced the concept of the occupancy grid as World Models for robots. We imbue the robot with a spatial-temporal world model, termed UniWorld, to perceive its surroundings and predict the future behavior of other participants. UniWorld involves initially predicting 4D geometric occupancy as the World Models for foundational stage and subsequently fine-tuning on downstream tasks. UniWorld can estimate missing information concerning the world state and predict plausible future states of the world. Besides, UniWorld's pre-training process is label-free, enabling the utilization of massive amounts of image-LiDAR pairs to build a Foundational Model.The proposed unified pre-training framework demonstrates promising results in key tasks such as motion prediction, multi-camera 3D object detection, and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, UniWorld shows a significant improvement of about 1.5% in IoU for motion prediction, 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. By adopting our unified pre-training method, a 25% reduction in 3D training annotation costs can be achieved, offering significant practical value for the implementation of real-world autonomous driving. Codes are publicly available at https://github.com/chaytonmin/UniWorld.
연구 동기 및 목표
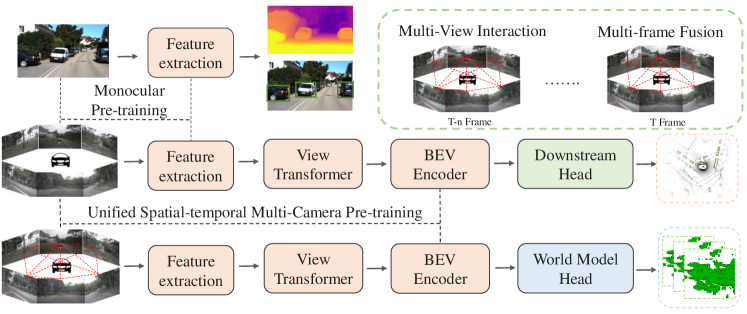
- 자율주행 사전 학습을 위한 시공간 월드 모델을 동기 부여하고 활용한다.
- 다중 시점을 사용하는 라벨이 없는 사전 학습 파이프라인을 개발하여 4D 점유를 재구성하고 미래 장면을 예측한다.
- 4D 점유 기반의 사전 학습이 모션 예측, 다중 카메라 3D 탐지, 시맨틱 씬 완성 등 하류 작업을 향상시킨다는 것을 입증한다.
- 통합된 다중 카메라 사전 학습이 라벨이 없는 데이터를 활용하면서 3D 주석 비용을 감소시킨다는 것을 보인다.
제안 방법
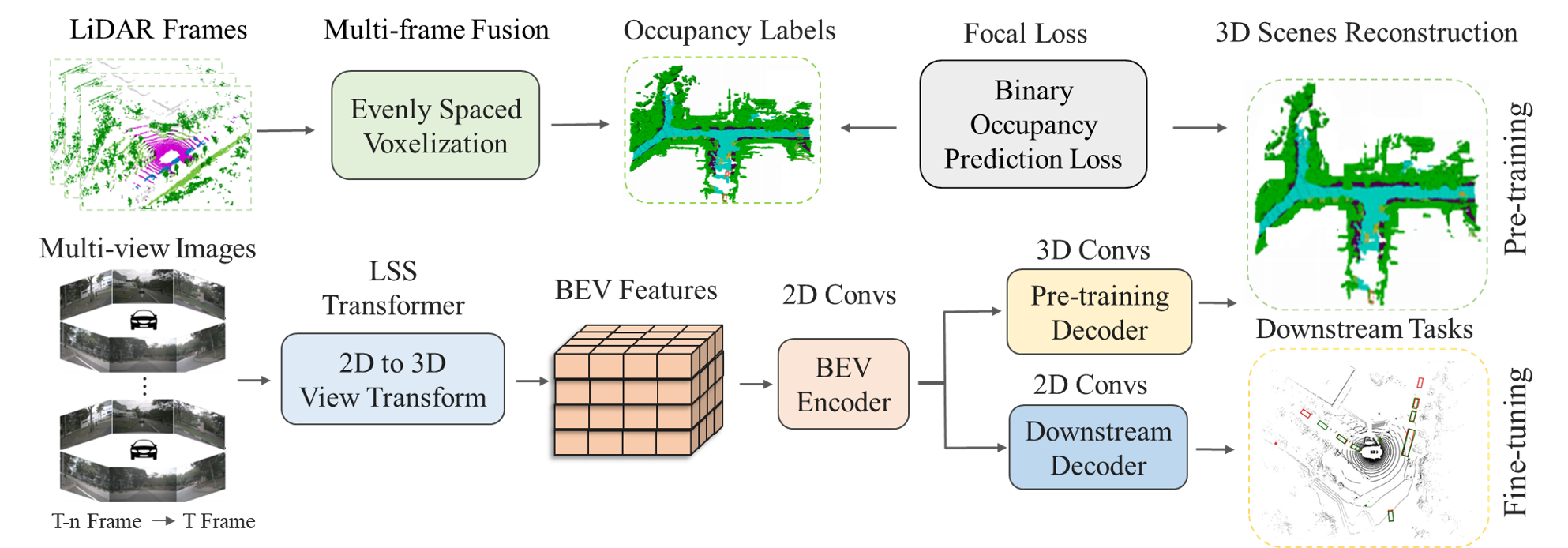
- LSS 또는 Transformer 기반 뷰 변환과 같은 방법을 사용하여 다중 시점 이미지를 통합된 BEV(Bird's Eye View) 표현으로 변환한다.
- 4D 기하학적 점유 디코더를 도입하여 D×H×W×1에 걸친 보셀 단위 점유를 예측하고, focal loss를 이용한 이진 점유 분류를 통해 학습한다.
- 프레임 간 희소성과 시간적 다이나믹스를 해결하기 위해 다중 프레임 LiDAR 포인트 클라우드를 융합하여 사전 학습용 실제 Ground-truth 4D 점유 레이블을 생성한다.
- 인코더와 경량 3D 점유 디코더를 사전 학습한 뒤 디코더를 버리고 인코더를 사용해 다운스트림 다중 카메라 인지 모델을 초기화한다.
- 먼저 3D 기하를 재구성한 다음 시맨틱 씬 완성을 위해 미세 조정하여 주변 시맨틱 점유까지 사전 학습을 확장하고, 조밀한 3D 주석 필요성을 줄인다.
- 유니월드를 단안 사전 학습, 깊이 기반 사전 학습, 지식 증류 접근 방식과 비교하고, 통합된 시공간 학습과 주석 비용 감소를 강조한다.
실험 결과
연구 질문
- RQ1라벨이 없는 다중 카메라 통합 사전 학습 프레임워크가 unlabeled 이미지-LiDAR 데이터로부터 정확한 4D 점유 표현을 학습할 수 있는가?
- RQ24D 점유 기반의 사전 학습이 단안 또는 깊이 기반 사전 학습에 비해 모션 예측, 다중 카메라 3D 물체 탐지, 시맨틱 씬 완성과 같은 하류 작업을 향상시키는가?
- RQ3다중 프레임 LiDAR 융합이 점유 레이블 품질과 하류 성능에 어떤 영향을 미치는가?
- RQ4 UniWorld의 데이터 효율성은 하류 3D 인지 작업에서 주석 비용 측면에서 어떤 이점을 제공하는가?
주요 결과
| Type | Method | Pre-train | Backbone | Image Size | CBGS | mAP | NDS | mATE | mASE | mAOE | mAVE | mAAE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DETR3D [7] | FCOS3D | R101-DCN | 900 × 1600 | ✓ | 0.349 | 0.434 | 0.716 | 0.268 | 0.379 | 0.842 | 0.200 | |
| FCOS3D + UniWorld-3D | R101-DCN | 900 × 1600 | ✓ | 0.360 | 0.461 | 0.701 | 0.260 | 0.372 | 0.730 | 0.188 | ||
| FCOS3D + UniWorld-4D | R101-DCN | 900 × 1600 | ✓ | 0.432 | 0.530 | 0.659 | 0.274 | 0.375 | 0.344 | 0.188 |
- UniWorld는 모션 예측(IoU 및 VPQ 이득)과 3D 물체 탐지(mAP 및 NDS 이득)에서 단안 사전 학습 대비 향상을 보인다.
- UniWorld-3D는 다중 카메라 3D 물체 탐지(mAP 및 NDS)를 향상시키고 하류 주석 비용을 약 25% 감소시킨다.
- 4D 점유 사전 학습은 주변 시맨틱 점유 예측에서 뚜렷한 이득(mIoU 향상)을 달성한다.
- 단안 깊이 사전 학습과 비교할 때, UniWorld 기반 사전 학습은 nuScenes 테스트 세트에서 mAP 및 NDS에 상당한 이득을 보인다.
- 데이터 효율성이 입증되어, 라벨이 달린 데이터의 75%가 전체 데이터 성능과 일치하고 25%는 미세 조정 시 특정 벤치마크를 능가할 수 있음이 실험으로 나타난다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.