[논문 리뷰] VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
VASA-1은 단일 이미지를 이용해 실시간으로 고충실도 오디오 구동 말하는 얼굴 비디오를 생성하며, 동기화된 입 모양 움직임, 표현적인 얼굴 역동성, 자연스러운 머리 움직임을 산출합니다. 이는 분리된 얼굴 잠재 공간에서 확산 기반의 전체 얼굴 역학 모델을 사용합니다.
We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only generating lip movements that are exquisitely synchronized with the audio, but also producing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos. Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method not only delivers high video quality with realistic facial and head dynamics but also supports the online generation of 512x512 videos at up to 40 FPS with negligible starting latency. It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
연구 동기 및 목표
- 실감나는, 오디오 구동 말하는 얼굴 생성의 현실화 촉진( lip 동기화 너머 ).
- 분리된, 표현적인 얼굴 잠재 공간을 개발하여 전체적 얼굴 역동성과 머리 동작을 포괄적으로 표현.
- 실시간 생성 가능성과 높은 시각 품질, 제어 신호(시선, 거리, 감정)의 제어 가능성 확보.
- 확산 트랜스포머를 활용하여 잠재 공간에서의 오디오 조건부 얼굴 역동성을 모델링.
제안 방법
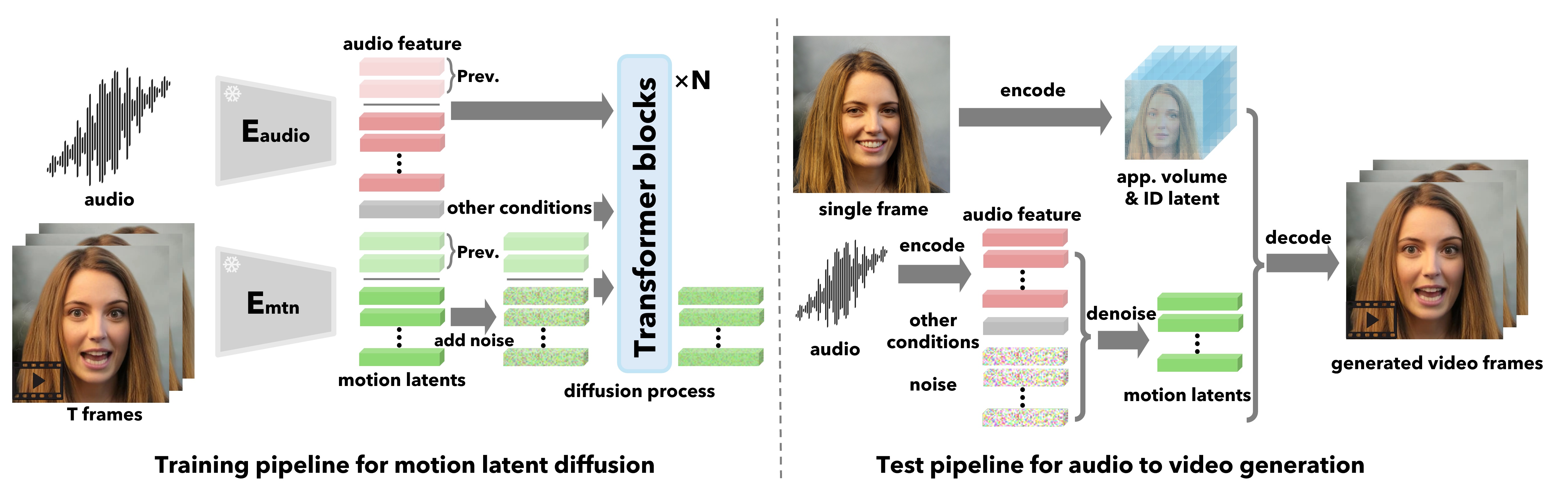
- 3D 보조의, 분리된 얼굴 잠재 공간 구성요소 V_app, z_id, z_pose, z_dyn으로 구축.
- 오디오 특징으로부터 아이덴티티에 의존하지 않는 전체적 얼굴 역동성과 머리 움직임을 모델링하기 위해 확산 트랜스포머를 학습한다.
- 선택적 제어(가시선 g, 거리 d, 감정 e)와 안정적인 샘플링을 위한 classifier-free 가이던스로 조건부 확산 프레임워크를 사용한다.
- 입력 이미지에서 얻은 외관 및 아이덴티티 특징을 활용하여 얼굴 디코더로 모션 잠재 코드를 영상 프레임으로 디코딩한다.
- 대규모 말하기 얼굴 비디오(VoxCeleb2 및 고해상도 추가 데이터셋)로 학습하여 표현적이고 제어 가능한 출력을 달성한다.

실험 결과
연구 질문
- RQ1잠재 공간에서의 전체적이고 아이덴티티에 의존하지 않는 얼굴 역동성을 효과적으로 모델링하여 오디오로부터 입 모양 동기화와 자연스러운 머리 자세를 생성할 수 있는가?
- RQ2확산-트랜스포머 기반 접근이 립-오디오 동기화, 포즈 정합성 및 전체 비디오 품질에서 이전 방법들보다 우수한가?
- RQ3제어 신호(시선, 머리 거리, 감정)가 생성된 말하는 얼굴의 리얼리즘과 제어 가능성에 어떤 영향을 미치는가?
- RQ4샘플링 스텝과 CFG 스케일이 립-오디오 동기화, 포즈 정확도 및 비디오 품질에 어떤 영향을 미치는가?
주요 결과
- VoxCeleb2 및 OneMin-32 벤치마크에서 립 동기화와 포즈 정합성 지표 모두에서 기존 방법보다 우수하다.
- 오디오-립 동기화 점수: Ours는 VoxCeleb2에서 S_C=8.841 및 S_D=6.312, OneMin-32에서 CAPP=0.468 및 ΔP=0.304를 달성했다.
- CAPP 지표는 오디오-포즈 정합성과 상관관계가 있으며 프레임 시프트에 따라 저하되어, 오디오-헤드 포즈 동기화를 강력하게 평가함을 보여준다.
- CFG 튜닝(오디오 CFG λ_A=0.5 및 시선 CFG λ_g=1.0)은 립-오디오 정렬과 포즈 동기화를 개선하고; 샘플링 스텝은 속도와 품질 간의 트레이드오프를 제공한다(스텝이 적을수록 추론 속도가 빨라진다).
- 비디오 품질(FVD_25)은 베이스라인보다 크게 우수하며; OneMin-32의 경우 제안 방법의 FVD_25=105.884에 비해 실제 비디오 29.244로 더 높은 현실감을 나타낸다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.