[논문 리뷰] VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation
VideoFusion은 프레임 간에 기본 노이즈를 공유하고 잔여 노이즈가 시간에 따라 달라지는 분해된 확산 프로세스를 도입하여, 미리 학습된 이미지 확산 모델을 기본 제너레이터로 활용해 여러 데이터셋에서 최첨단 결과를 달성하도록 한다.
A diffusion probabilistic model (DPM), which constructs a forward diffusion process by gradually adding noise to data points and learns the reverse denoising process to generate new samples, has been shown to handle complex data distribution. Despite its recent success in image synthesis, applying DPMs to video generation is still challenging due to high-dimensional data spaces. Previous methods usually adopt a standard diffusion process, where frames in the same video clip are destroyed with independent noises, ignoring the content redundancy and temporal correlation. This work presents a decomposed diffusion process via resolving the per-frame noise into a base noise that is shared among all frames and a residual noise that varies along the time axis. The denoising pipeline employs two jointly-learned networks to match the noise decomposition accordingly. Experiments on various datasets confirm that our approach, termed as VideoFusion, surpasses both GAN-based and diffusion-based alternatives in high-quality video generation. We further show that our decomposed formulation can benefit from pre-trained image diffusion models and well-support text-conditioned video creation.
연구 동기 및 목표
- 비디오 프레임의 시간적 중복성을 활용하여 확산 모델을 통한 비디오 생성을 개선할 의도.
- 프레임별 노이즈를 공유되는 기본 노이즈와 시간에 따라 변화하는 잔여 노이즈로 분할하는 분해된 확산 프로세스 제안.
- 비디오 합성에 강력한 이미지 priors를 주입하기 위해 미리 학습된 이미지 확산 모델을 기본 제너레이터로 활용.
- 프레임 인덱스 및 텍스트/조건 신호에 따라 프레임별 잔여를 모델링하는 잔여 제너레이터 개발.
- 생성 비디오의 콘텐츠 대 동작 제어 요인을 분석하고, 효율성과 확장성을 평가한다.
제안 방법
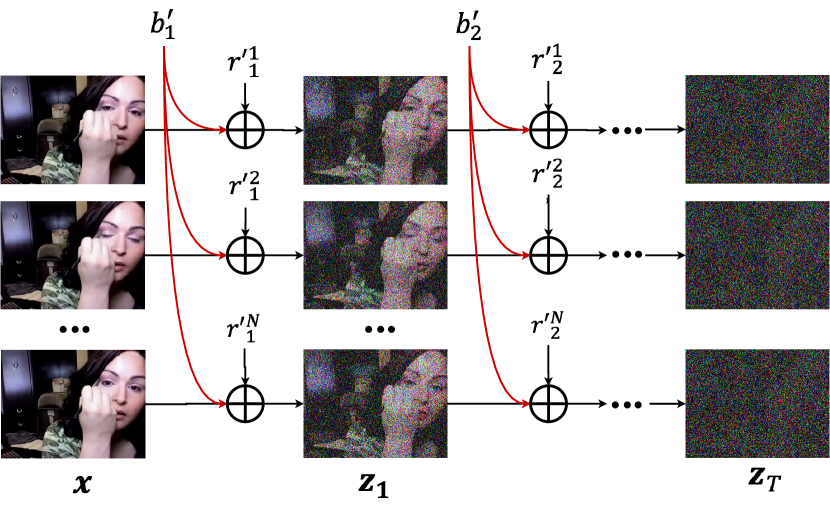
- 프레임별 데이터 x^i를 공유된 기본 x^0와 잔여 Delta x^i로 분해하고 x^i = sqrt(lambda^i) x^0 + sqrt(1 - lambda^i) Delta x^i로 표현한다.
- 확산 노이즈 epsilon_t^i를 프레임 간에 공유되는 기본 노이즈 b_t와 잔여 노이즈 r_t^i로 분할해 z_t^i를 x^0의 확산과 Delta x^i의 확산의 합으로 표현하도록 한다.
- 기본 노이즈 b_t를 모든 프레임에 공유하게 하여 z_t^i가 b_t를 통해 상관되도록 만들어 디노이징 네트워크의 영상 재구성 부담을 줄인다.
- 사전 학습된 이미지 DPM을 기본 제너레이터로 사용하여 하나의 프레임으로부터 기본 노이즈 z_phi^b(z^{floor(N/2)}_t, t)을 추정하고, 잔여 제너레이터 z_psi^r를 통해 프레임별 잔여 노이즈를 추정한다.
- 프레이즈 i ≠ floor(N/2)에 대해 기본 제너레이터에 대한 stop-gradient를 적용하여 이미지 priors를 보존하면서 비디오 데이터에 대해 미세 조정 가능하도록 jointly 훈련한다.
- DDIM/DDPM 샘플링을 두 단계 프로세스로 채택한다: 먼저 기본 노이즈를 제거하고, 다음 잔여 노이즈를 추정하여 다음 잠재 단계(latent step)를 생성한다.
![Figure 2 : Comparison between images generated from (a) independent noises; (b) noises with a shared base noise. Images of the same row are generated by the decoder of DALL-E 2 [ 25 ] with the same condition.](https://ar5iv.labs.arxiv.org/html/2303.08320/assets/x2.png)
실험 결과
연구 질문
- RQ1확산 노이즈를 공유 기본 구성요소와 프레임별 잔여 구성요소로 분해하는 것이 비디오 확산 모델의 시간 일관성을 개선할 수 있는가?
- RQ2사전 학습된 이미지 확산 모델을 기본 제너레이터로 활용하면 비디오 합성 품질과 효율성을 향상시키는 강력한 priors를 제공하는가?
- RQ3프레임별 기본 노드 lambda^i를 콘텐츠 보존과 모션 다이내믹 간의 균형을 맞추도록 어떻게 선택해야 하는가?
- RQ4기본 제너레이터와 잔여 제너레이터의 공동 미세 조정이 비디오 생성 성능에 어떤 영향을 미치는가?
- RQ5더 긴 시퀀스와 더 높은 해상도에서도 일관성과 품질을 유지할 수 있는가?
주요 결과
- VideoFusion은 16×64×64 및 16×128×128 해상도에서 FVD 및 IS 지표에서 GAN 기반 및 확산 기반 기준선을 능가하며 다수의 데이터셋에서 최첨단 결과를 달성했다.
- UCF101(비조건, 16×64×64)에서 IS 71.67 및 FVD 139를 달성하고, 16×128×128에서 IS 72.22 및 FVD 220를 달성했다.
- Sky Time-lapse에서 FVD 47.0 및 KVD 5.3; TaiChi-HD에서 FVD 56.4 및 KVD 6.9를 기록했다.
- 공유 기본 노이즈와 대규모 사전 학습 기반 제너레이터로 인한 메모리 사용량(약 21.8% 감소) 및 대기시간(약 57.5% 빨라짐) 감소 등 효율성 개선이 있었다.
- λ^i 매개변수가 성능에 결정적임을 확인했고, 중간 값(예: 0.5)이 너무 작거나 큰 값보다 IS/FVD가 더 좋았으며, stop-gradient를 포함한 공동 미세 조정이 결과를 개선했다.
- 긴 시퀀스 생성(512 프레임)에서도 기본 노이즈를 고정하고 잔여 노이즈를 변화시키는 방식으로 품질과 일관성을 유지할 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.