[논문 리뷰] WhiteFox: White-Box Compiler Fuzzing Empowered by Large Language Models
WhiteFox는 LLM을 통해 최적화 코드를 분석하고 테스트 입력을 생성하는 화이트박스 컴파일러 퍼저를 도입하여 더 높은 최적화 커버리지와 여러 컴파일러에 걸친 많은 버그를 발견합니다.
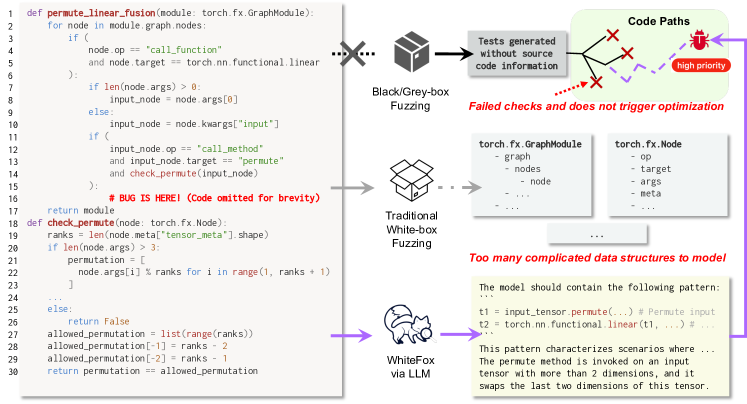
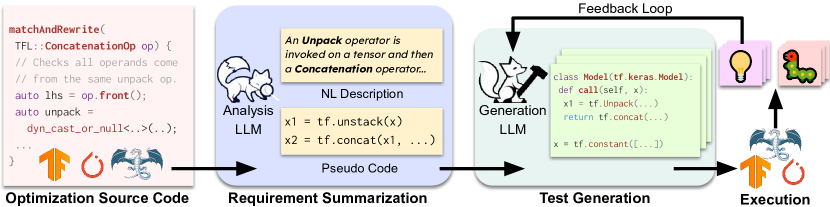
Compiler correctness is crucial, as miscompilation can falsify program behaviors, leading to serious consequences. Fuzzing has been studied to uncover compiler defects. However, compiler fuzzing remains challenging: Existing arts focus on black- and grey-box fuzzing, which generates tests without sufficient understanding of internal compiler behaviors. Meanwhile, traditional white-box techniques, like symbolic execution, are computationally inapplicable to the giant codebase of compilers. Recent advances demonstrate that Large Language Models (LLMs) excel in code generation/understanding tasks. Nonetheless, guiding LLMs with compiler source-code information remains a missing piece of research in compiler testing. To this end, we propose WhiteFox, the first white-box compiler fuzzer using LLMs with source-code information to test compiler optimization, with a spotlight on detecting deep logic bugs in the deep learning (DL) compilers. WhiteFox adopts a multi-agent framework: an LLM-based analysis agent examines the low-level optimization source code and produces requirements on the high-level test programs that can trigger the optimization; an LLM-based generation agent produces test programs based on the summarized requirements. Additionally, optimization-triggering tests are used as feedback to enhance the generation on the fly. Our evaluation on the three most popular DL compilers (i.e., PyTorch Inductor, TensorFlow-XLA, and TensorFlow Lite) shows WhiteFox can generate high-quality test programs to exercise deep optimizations, practicing up to 8X more than state-of-the-art fuzzers. WhiteFox has found 101 bugs for the DL compilers, with 92 confirmed as previously unknown and 70 fixed. WhiteFox has been acknowledged by the PyTorch team and is being incorporated into its development workflow. Beyond DL compilers, WhiteFox can also be adapted for compilers in different domains.
연구 동기 및 목표
- 전통적 기호적 방법이나 커버리지 기반 방법을 넘어 신뢰할 수 있는 컴파일러 최적화와 확장 가능한 화이트박스 퍼징의 필요성을 촉진한다.
- 최적화 구현을 고수준 테스트 입력으로 번역하기 위한 이중 LLM 프레임워크를 제안한다.
- 최적화 트리거 테스트를 활용한 피드백 루프를 개발하여 테스트 입력을 반복적으로 개선한다.
- WhiteFox를 여러 컴파일러에서 평가하여 최적화 커버리지와 버그 발견 능력을 평가한다.
제안 방법
- 분석 LLM을 사용해 저수준 최적화 코드를 혼합 NL 및 의사코드 형식으로 고수준 트리거 요건으로 요약한다.
- 생성 LLM을 사용해 요약된 요건을 만족하는 테스트 프로그램(예: PyTorch 모델)을 생성한다.
- 최적화를 트리거하는 테스트를 소수 샘플 예제로 추가하여 향후 생성을 개선하는 피드백 루프를 구현한다.
- 최적화가 트리거될 때를 탐지하고 테스트 오랄로이드로서 충돌이나 결과 불일치를 식별하도록 컴파일러를 계 Instrument한다.
- 탐색과 활용의 균형을 맞추기 위해 테스트 생성에 효과적인 트리거링 예제를 선택하는 데 Thompson Sampling 기반 다중 무장 밴딧을 적용한다.
실험 결과
연구 질문
- RQ1LLMs가 저수준 최적화 구현을 효과적으로 트리거 최적화를 유발하는 고수준 입력 요건으로 번역할 수 있는가?
- RQ2LLM 가이드가 이끄는 테스트 입력이 다양한 컴파일러에서 기존 퍼저보다 더 깊은 최적화 커버리지를 제공하는가?
- RQ3피드백 루프와 예제 선택 전략이 후속 테스트 생성을 개선하는 데 얼마나 효과적인가?
주요 결과
- WhiteFox는 실험에서 최적화가 수행된 수를 최첨단 퍼저보다 최대 8배 더 달성한다.
- 프레임워크는 테스트된 컴파일러에서 96개의 버그를 발견했으며 그 중 80개는 이전에 알려지지 않았고 51개는 이미 수정되었다.
- WhiteFox는 LLVM을 포함한 3개의 DL 컴파일러와 4개의 SUT에서 더 높은 최적화 커버리지를 보여준다.
- 자연어와 의사코드 요약의 결합은 최적화를 트리거하기 위한 요건 추출을 개선한다.
- 트리거링 테스트를 소수 샘플 예제로 사용하고 Thompson Sampling을 적용한 피드백 루프는 후속 테스트 생성을 개선한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.