[논문 리뷰] xCodeEval: A Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval
xCodeEval은 코드용으로 가장 큰 실행 가능한 다국어 다중 작업 벤치마크로, 7.5K 문제와 17개 언어를 포괄하며 7개의 작업과 실행 기반 평가 엔진 ExecEval를 갖추고 있다. 이는 LLM의 코드 이해, 생성, 번역, 검색에 대한 언어 간, 작업 간, 실행 수준 평가를 가능하게 한다.
Recently, pre-trained large language models (LLMs) have shown impressive abilities in generating codes from natural language descriptions, repairing buggy codes, translating codes between languages, and retrieving relevant code segments. However, the evaluation of these models has often been performed in a scattered way on only one or two specific tasks, in a few languages, at a partial granularity (e.g., function) level, and in many cases without proper training data. Even more concerning is that in most cases the evaluation of generated codes has been done in terms of mere lexical overlap with a reference code rather than actual execution. We introduce xCodeEval, the largest executable multilingual multitask benchmark to date consisting of $25$M document-level coding examples ($16.5$B tokens) from about $7.5$K unique problems covering up to $11$ programming languages with execution-level parallelism. It features a total of $7$ tasks involving code understanding, generation, translation and retrieval. xCodeEval adopts an execution-based evaluation and offers a multilingual code execution engine, ExecEval that supports unit test based execution in all the $11$ languages. To address the challenge of balancing the distributions of text-code samples over multiple attributes in validation/test sets, we propose a novel data splitting and a data selection schema based on the geometric mean and graph-theoretic principle. Our experiments with OpenAI's LLMs (zero-shot) and open-LLMs (zero-shot and fine-tuned) on the tasks and languages demonstrate **xCodeEval** to be quite challenging as per the current advancements in language models.
연구 동기 및 목표
- 다중 언어 프로그램 이해, 생성, 번역 및 검색을 실행 기반 프레임워크를 사용하여 평가한다.
- 다양한 프로그래밍 언어와 문제 난이도를 포괄하는 대규모의 다양 한 벤치마크를 제공한다.
- 새로운 데이터 분할 전략과 언어 간의 단위 테스트를 실행하는 실행 엔진을 통해 공정한 평가를 가능하게 한다.
제안 방법
- Codeforces에서 7.5K 문제에 걸쳐 최대 17개 언어로 2,500만 샘플 데이터세트를 구성한다.
- 안전하고 분산된 실행 엔진인 ExecEval를 개발하여 11개 언어의 44개 컴파일러/인터프리터를 지원하며 단위 테스트 기반 평가를 수행한다.
- 실행 기반 평가를 통해 7개의 작업(2개 분류, 3개 생성, 2개 검색)을 정의한다.
- 검증/테스트 분포를 문제 및 태그 전반에 걸쳐 균형 있게 분배하기 위한 기하 평균 및 순환 문제를 기반으로 한 새로운 데이터 분할 및 샘플 선택 전략을 사용한다.
- 벤치마크에 대해 OpenAI 및 공개 LLM을 평가하여 현재 역량을 측정하고 격차를 식별한다.
- 데이터 세트, GitHub/Hub, 문서를 포함한 학습 데이터 및 평가 자원을 제공한다.
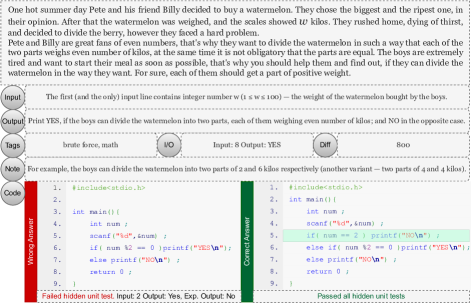
실험 결과
연구 질문
- RQ1다중 언어 LLM이 실행 기반 단위 테스트에 의해 평가될 때 코드 이해, 생성, 번역 및 검색에서 어떤 성과를 보이는가?
- RQ2실행 가능한 코드 작업에 대해 17개 언어 간 교차 언어 전이 및 제로샷 능력은 어떠한가?
- RQ3다른 문제 난이도와 언어 자원이 프로그램 합성, 수리 및 번역 성능에 어떤 영향을 미치는가?
- RQ4제안된 데이터 분할 및 샘플링 전략이 여러 속성에 걸쳐 균형 잡히고 대표적인 검증/테스트 세트를 생성하는가?
- RQ5현재 LLM의 언어별 실행 가능한 코드 숙련도와 추론에 대해 어떤 통찰을 얻을 수 있는가?
주요 결과
- xCodeEval은 최첨단 LLM에 대해 도전적이며, 제로샷 및 미세조정 모델을 포함한 태스크와 언어 간에서도 난이도가 높다.
- 태그 분류는 문제 설명이 포함될 때 일반적인 성능이 양호하고, 웹 언어의 성능은 다소 저하된다.
- 코드 컴파일은 Go, PHP, Python, Ruby, C#에서 강하고 Java, Kotlin, Rust에서는 거의 무작위에 가깝다.
- 프로그램 합성은 일부 언어에서 더 높은 pass@k를 달성하지만 Rust 및 자원이 덜 풍부한 언어에서는 뒤처지며 APR은 일부 언어에서 상대적으로 더 강한 성능을 보인다.
- 코드-코드 및 NL-코드 검색에서 StarEncoder는 언어-자원 의존적 결과를 보이며, 전반적으로 NL-코드 성능이 더 우수하다; 더 큰 말뭉치와 언어-자원 불균형은 Code-Code 검색에 영향을 미친다.
- 더 작은 모델(Starcoderbase-3B, CodeLlama 변형)으로의 실험은 데이터 효율성을 보여주며, 작은 미세조정 모델도 xCodeEval 데이터의 이점을 얻을 수 있는 반면, 대형 지시형 모델은 여전히 많은 경우에서 더 큰 대안보다 우수한 성능을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.