[논문 리뷰] ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Image
ZeroNVS는 다양한 실세계 장면 데이터에 대해 3D-인식 확산 모델을 훈련시켜 단일 이미지로부터 360도 신규 시점을 합성하며, camera conditioning과 SDS anchoring를 도입해 DTU와 Mip-NeRF 360 벤치마크에서 제로샷 성능을 달성한다.
We introduce a 3D-aware diffusion model, ZeroNVS, for single-image novel view synthesis for in-the-wild scenes. While existing methods are designed for single objects with masked backgrounds, we propose new techniques to address challenges introduced by in-the-wild multi-object scenes with complex backgrounds. Specifically, we train a generative prior on a mixture of data sources that capture object-centric, indoor, and outdoor scenes. To address issues from data mixture such as depth-scale ambiguity, we propose a novel camera conditioning parameterization and normalization scheme. Further, we observe that Score Distillation Sampling (SDS) tends to truncate the distribution of complex backgrounds during distillation of 360-degree scenes, and propose "SDS anchoring" to improve the diversity of synthesized novel views. Our model sets a new state-of-the-art result in LPIPS on the DTU dataset in the zero-shot setting, even outperforming methods specifically trained on DTU. We further adapt the challenging Mip-NeRF 360 dataset as a new benchmark for single-image novel view synthesis, and demonstrate strong performance in this setting. Our code and data are at http://kylesargent.github.io/zeronvs/
연구 동기 및 목표
- 다양한 객체와 복잡한 배경을 가진 야외 현장(in-the-wild)에서의 제로샷 360도 신규 시점 합성을 다룬다.
- 다양한 기하학 및 배경을 다루기 위해 CO3D, RealEstate10K, ACID 등 다양한 실제 장면 데이터셋으로 구성된 대규모 혼합 데이터에 대해 학습된 확산 기반 사전(prior)을 개발한다.
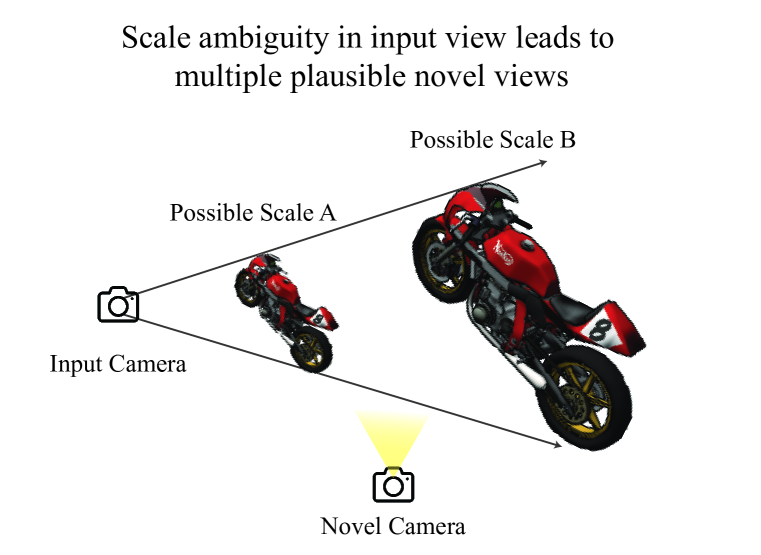
- 스케일 불확실성을 해소하고 3D 일관성을 향상시키기 위한 강력한 카메라 컨디셔닝 체계와 장면 정규화를 구현한다.
- SDS 앵커링을 활용한 SDS 기반 증류에서 배경 다양성 손실을 완화하여 다양하고 합리적인 배경을 촉진한다.
- 강력한 제로샷 일반화를 입증하고 새로운 장면 수준 단일 이미지 NVS 벤치마크(Mip-NeRF 360)를 확립한다.
제안 방법
- 단일 이미지로부터 3D 일관된 신규 시점을 얻기 위해 2D 조건부 확산 모델을 훈련한 뒤 3D SDS 증류를 수행한다.
- 6DoF+1 카메라 컨디셔닝 표현(가시영역 포함 상대 자세와 시야각) 및 시청자 중심의 정규화 체계를 도입하여 야외 데이터 전반의 스케일 및 자세 변화에 대응한다.
- 깊이 통계에서 얻은 장면 스케일 매개변수 q를 사용해 카메라 평행이동을 정규화하여 스케일 불확실성을 줄인다.
- 훈련 중 일관된 스케일 추정을 위해 깊이 보충(Dense maps)를 적용하는 새로운 정규화 방법인 6DoF+1, viewer를 도입하여 데이터셋 간 컨디셔닝을 일원화한다.
- SDS 앵커링을 제안한다: DDIM으로 여러 앵커 뷰를 샘플링한 뒤 SDS 최적화 시 가장 가까운 앵커를 컨디셔닝으로 사용하여 배경 다양성을 증가시킨다.
- DTU에서 LPIPS, PSNR, SSIM으로 평가(제로샷)하고 새로운 제로샷 장면 수준 NVS 벤치마크로 Mip-NeRF 360을 도입한다.
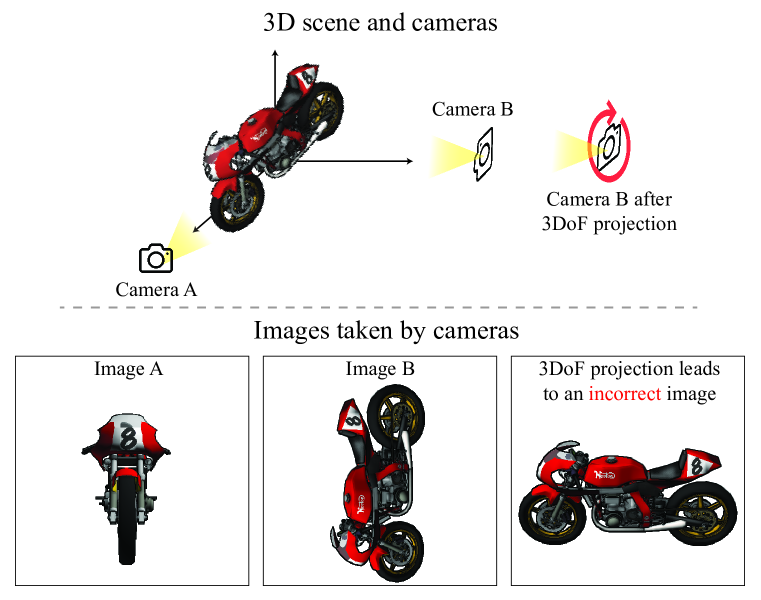
실험 결과
연구 질문
- RQ1다양한 실제 장면에서 학습된 확산 기반 사전이 단일 이미지로부터 제로샷 360도 신규 시점 합성을 어떻게 가능하게 할 수 있는가?
- RQ2야외 현장의 스케일 및 자세 불확실성에 가장 잘 대처하는 카메라 컨디셔닝 및 정규화 전략은 무엇인가?
- RQ33D 일관성을 희생하지 않으면서 SDS 기반 증류에서 장면 수준 NVS의 배경 다양성을 개선할 수 있는가?
주요 결과
| 데이터셋 / 방법 | LPIPS ↓ | PSNR ↑ | SSIM ↑ |
|---|---|---|---|
| DS-NeRF (Deng et al., 2022b) | 0.649 | 12.17 | 0.410 |
| PixelNeRF (Yu et al., 2021) | 0.535 | 15.55 | 0.537 |
| SinNeRF (Xu et al., 2022) | 0.525 | 16.52 | 0.560 |
| DietNeRF (Jain et al., 2021) | 0.487 | 14.24 | 0.481 |
| NeRDi (Deng et al., 2022a) | 0.421 | 14.47 | 0.465 |
| ZeroNVS (ours) | 0.380 | 13.55 | 0.469 |
- ZeroNVS는 DTU에서 제로샷 설정에서 최첨단 LPIPS를 달성하고 DTU에서 학습된 방법들을 능가한다.
- Mip-NeRF 360에서 제로샷 기반 베이스라인들 중 최상의 LPIPS를 달성한다.
- 깊이 정보 기반 스케일 정규화를 포함한 시청자 중심의 6DoF+1 컨디셔닝은 2D-에서 3D로의 컨디셔닝과 CO3D, ACID, RealEstate10K 등 다양한 데이터셋에서의 일반화를 향상시킨다.
- SDS 앵커링은 배경 다양성을 증가시키며, 사용자 연구에서 리얼리즘과 창의성을 고려해 선호된다.
- CO3D, ACID, RealEstate10K의 혼합 데이터로의 학습이 평가된 데이터셋 전반에서 성능을 개선한다는 연구 결과가 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.