[论文解读] CvT: Introducing Convolutions to Vision Transformers
CvT 将卷积集成到 Vision Transformers,创建一个分层的、卷积增强的 Transformer,在参数和 FLOPs 更少的情况下,在 ImageNet 上达到 SOTA,甚至在没有位置嵌入的情况下。
We present in this paper a new architecture, named Convolutional vision Transformer (CvT), that improves Vision Transformer (ViT) in performance and efficiency by introducing convolutions into ViT to yield the best of both designs. This is accomplished through two primary modifications: a hierarchy of Transformers containing a new convolutional token embedding, and a convolutional Transformer block leveraging a convolutional projection. These changes introduce desirable properties of convolutional neural networks (CNNs) to the ViT architecture (\ie shift, scale, and distortion invariance) while maintaining the merits of Transformers (\ie dynamic attention, global context, and better generalization). We validate CvT by conducting extensive experiments, showing that this approach achieves state-of-the-art performance over other Vision Transformers and ResNets on ImageNet-1k, with fewer parameters and lower FLOPs. In addition, performance gains are maintained when pretrained on larger datasets (\eg ImageNet-22k) and fine-tuned to downstream tasks. Pre-trained on ImageNet-22k, our CvT-W24 obtains a top-1 accuracy of 87.7\% on the ImageNet-1k val set. Finally, our results show that the positional encoding, a crucial component in existing Vision Transformers, can be safely removed in our model, simplifying the design for higher resolution vision tasks. Code will be released at \url{https://github.com/leoxiaobin/CvT}.
研究动机与目标
- 结合 CNN 和 Transformer 以利用局部和全局上下文进行图像识别的动机。
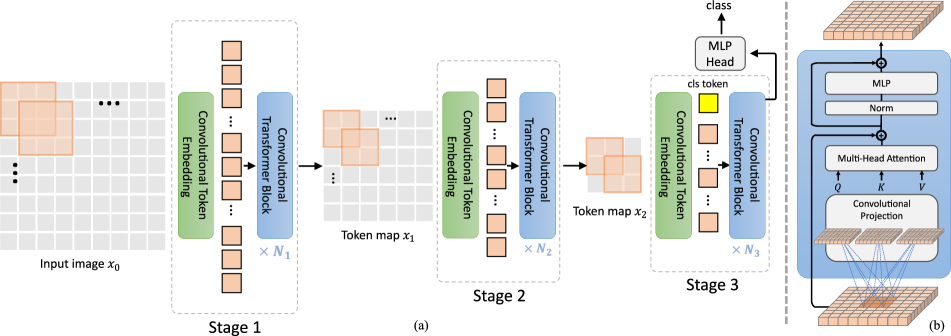
- 提出 CvT 的两个核心变化:卷积令牌嵌入与分层 Transformer 框架中的卷积投影。
- 证明在 ImageNet-1k 和 ImageNet-22k 上相较 ViT/DeiT 和有竞争力的 CNN 具有更高的准确性和效率。
- 展示在不牺牲性能的情况下可以去除位置编码,从而实现可变输入分辨率。
提出的方法
- 提出一个三阶段分层的 CvT 骨干网,使用卷积令牌嵌入在逐步降低令牌长度的同时提高特征维度。
- 用基于深度可分离卷积的卷积投影来替代注意力输入投影,以建模局部上下文并实现令牌下采样。
- 在卷积令牌嵌入之后执行层归一化,并在最终阶段应用标准的 MLP 头进行分类。
- 证明由于卷积带来的内在局部上下文,去掉位置嵌入不会降低性能。
![Figure 1 : Top-1 Accuracy on ImageNet validation compared to other methods with respect to model parameters. (a) Comparison to CNN-based model BiT [ 18 ] and Transformer-based model ViT [ 11 ] , when pretrained on ImageNet-22k. Larger marker size indicates larger architectures. (b) Comparison to con](https://ar5iv.labs.arxiv.org/html/2103.15808/assets/x1.png)
实验结果
研究问题
- RQ1在大规模图像分类中引入卷积进入 Vision Transformers 是否能提升准确性和效率?
- RQ2具有卷积令牌嵌入和卷积投影的分层多阶段 CvT 架构能否超越 ViT/DeiT 和 CNN?
- RQ3在局部上下文被卷积捕获的情况下,是否可以在不牺牲性能的前提下去除显式位置嵌入?
- RQ4CvT 模型如何随数据集规模(如 ImageNet-1k vs ImageNet-22k)和向下任务迁移的扩展?
主要发现
| 方法类型 | 网络 | #Param (M) | 图像大小 | FLOPs (G) | ImageNet top-1 (%) | Real (%) | V2 (%) |
|---|---|---|---|---|---|---|---|
| 卷积变换器(本研究) | CvT-13 | 20 | 224^2 | 4.5 | 81.6 | 86.7 | 70.4 |
| 卷积变换器(本研究) | CvT-21 | 32 | 224^2 | 7.1 | 82.5 | 87.2 | 71.3 |
| 卷积变换器(本研究) | CvT-13↑384 | 20 | 384^2 | 16.3 | 83.0 | 87.9 | 71.9 |
| 卷积变换器(本研究) | CvT-21↑384 | 32 | 384^2 | 24.9 | 83.3 | 87.7 | 71.9 |
| 卷积变换器(本研究) | CvT-13-NAS | 18 | 224^2 | 4.1 | 82.2 | 87.5 | 71.3 |
| 卷积变换器(本研究) | CvT-W24↑384 | 277 | 384^2 | 193.2 | 87.7 | 90.6 | 78.8 |
- CvT-21 在 ImageNet-1k 上达到 82.5% top-1,FLOPs 为 7.1G,参数为 32M,优于 DeiT-B,且 FLOPs/参数更少。
- CvT-13 达到 81.6% top-1,FLOPs 4.5G,参数 20M,在效率方面超过若干 CNN/Transformer 基线。
- CvT-W24 在 ImageNet-22k 预训练后达到 ImageNet-1k 的 87.7% top-1,并在 CIFAR、PETS、Flowers 等数据集上保持强泛化。
- 从 CvT 中移除位置嵌入不会影响性能,凸显卷积组件提供了足够的空间偏置。
- 受 NAS 启发的变体(CvT-13-NAS)在参数更少的情况下也能达到可比精度,表明架构搜索仍有潜在收益。
- CvT 在不同分辨率(如 384^2)下显示出强大性能,与其他变换器在相似或更低 FLOPs 下具竞争或更高准确度。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。