[論文レビュー] A Careful Examination of Large Language Model Performance on Grade School Arithmetic
この論文は GSM1k を新たに導入し、GSM8k を模倣して初等レベルの算数の性能が真の推論を反映しているか、それともデータ汚染によるものかを評価する1250問のベンチマークを提示する。複数のモデルファミリで顕著な過適合を発見する一方、フロンティアモデルでは強い一般化を示す。
Large language models (LLMs) have achieved impressive success on many benchmarks for mathematical reasoning. However, there is growing concern that some of this performance actually reflects dataset contamination, where data closely resembling benchmark questions leaks into the training data, instead of true reasoning ability. To investigate this claim rigorously, we commission Grade School Math 1000 (GSM1k). GSM1k is designed to mirror the style and complexity of the established GSM8k benchmark, the gold standard for measuring elementary mathematical reasoning. We ensure that the two benchmarks are comparable across important metrics such as human solve rates, number of steps in solution, answer magnitude, and more. When evaluating leading open- and closed-source LLMs on GSM1k, we observe accuracy drops of up to 8%, with several families of models showing evidence of systematic overfitting across almost all model sizes. Further analysis suggests a positive relationship (Spearman's r^2 = 0.36) between a model's probability of generating an example from GSM8k and its performance gap between GSM8k and GSM1k, suggesting that some models may have partially memorized GSM8k. Nevertheless, many models, especially those on the frontier, show minimal signs of overfitting, and all models broadly demonstrate generalization to novel math problems guaranteed to not be in their training data.
研究の動機と目的
- GSM8k-stype のベンチマークがデータ汚染の影響を受けているかを評価するため、独立した人手作成の GSM1k データセットを構築する。
- 複数のモデルファミリとサイズを通じて GSM1k と GSM8k を比較し、過適合と一般化を定量化する。
提案手法
- GSM1k を、GSM8k の難易度分布に合わせた1250の人手で注釈された問題で構築する。
- fork of EleutherAI LM Evaluation Harness を用いて GSM1k 上でオープンソースおよびクローズドソースの LLM を評価する。
- モデルファミリ間で GSM8k 対 GSM1k の性能差を比較して過適合を分析する。
- データ汚染を評価するため、GSM8k のデータを生成する可能性を測定する。
- 定性的な教訓を提供し、汚染以外の過適合の潜在的な源について論じる。
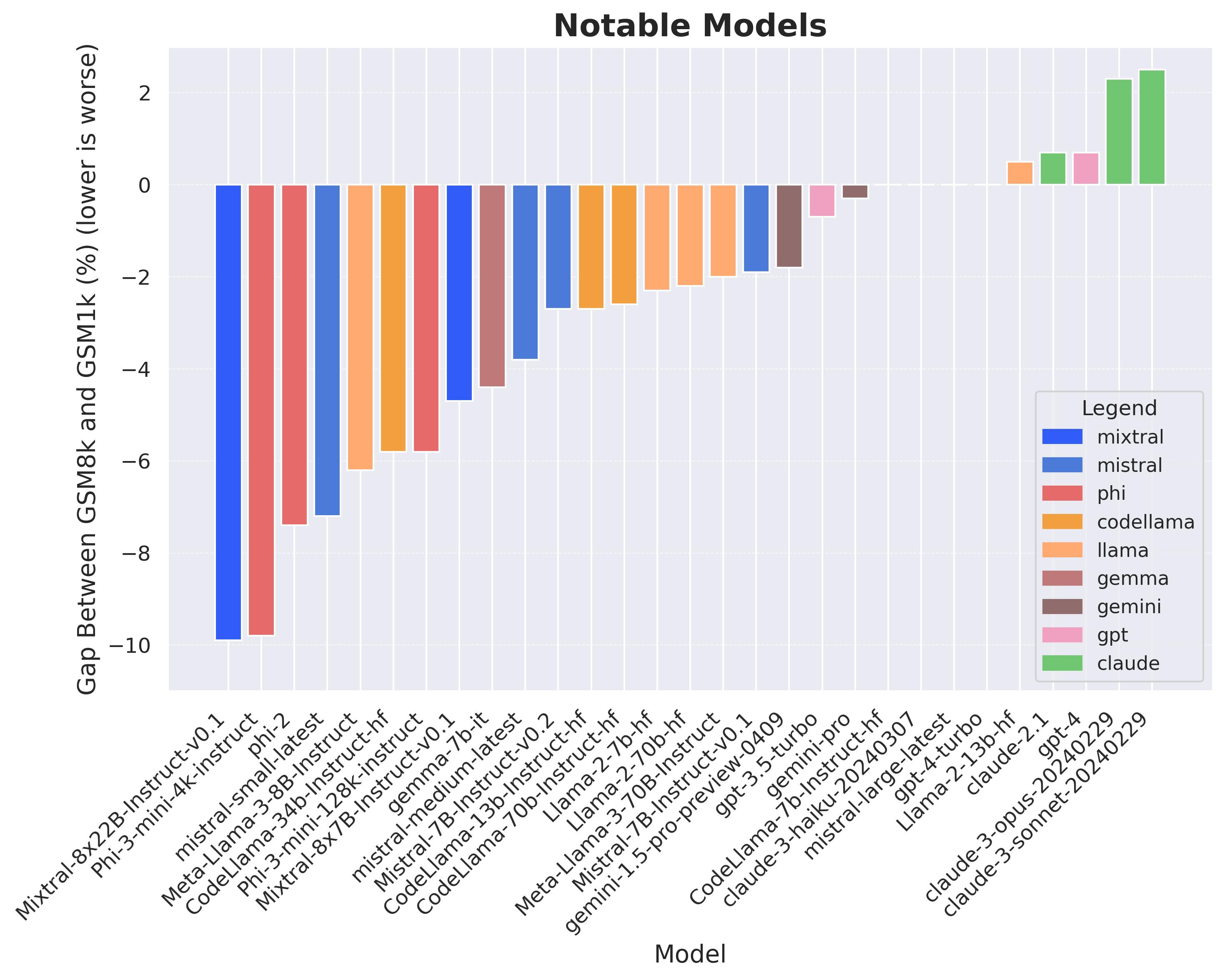
実験結果
リサーチクエスチョン
- RQ1GSM1k は GSM8k が見逃している過適合を明らかにするか。
- RQ2どのモデルファミリがサイズとリリースを超えて体系的な過適合を示すか。
- RQ3フロンティアモデルは過適合が少なく、新しい問題へより良い一般化を示すか。
- RQ4モデルが GSM8k データを生成する可能性と、GSM8k–GSM1k の性能格差との関係はどうなるか。
- RQ5データ汚染は観測された過適合の原因をどの程度説明できるか、他の要因はあるか。
主な発見
- GSM1k は、いくつかのモデルファミリにおいて GSM1k 上での正確さが GSM8k より最大で 13% 減少することを示す。
- Mistral および Phi ファミリはモデルサイズを超えて体系的な過適合を示す一方、フロンティアモデルは過適合が最小である。
- フロンティアモデル(例:Gemini、GPT、Claude)は GSM8k と GSM1k の両方で同様の成績を示し、より強い一般化や汚染対策を示唆する。
- モデルが GSM8k データを生成する可能性とその GSM8k–GSM1k の性能ギャップには正の関係があり(Spearman r^2 = 0.32)、GSM8k テストデータの部分的な記憶を示唆する。
- 過適合したモデルでも合理的に推論し、新規の GSM1k 問題を解けることがあり、過適合が推論能力を完全に排除するという考えに挑戦する。
- データ汚染は過適合の唯一の説明ではなく、ベンチマーク主導のデータ収集など他の要因も寄与する可能性が高い。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。