[論文レビュー] A Comprehensive Survey on Data Augmentation
本論文は、5つのデータモダリティ(image, text, graph, tabular, time-series)に跨る、モダリティに依存しないデータ拡張と survey 手法のデータ中心の分類法を提案する。
Data augmentation is a series of techniques that generate high-quality artificial data by manipulating existing data samples. By leveraging data augmentation techniques, AI models can achieve significantly improved applicability in tasks involving scarce or imbalanced datasets, thereby substantially enhancing AI models' generalization capabilities. Existing literature surveys only focus on a certain type of specific modality data and categorize these methods from modality-specific and operation-centric perspectives, which lacks a consistent summary of data augmentation methods across multiple modalities and limits the comprehension of how existing data samples serve the data augmentation process. To bridge this gap, this survey proposes a more enlightening taxonomy that encompasses data augmentation techniques for different common data modalities by investigating how to take advantage of the intrinsic relationship between and within instances. Additionally, it categorizes data augmentation methods across five data modalities through a unified inductive approach.
研究の動機と目的
- 希少または不均衡なデータセットに対処し、汎化性能を向上させるための data augmentation の必要性を動機付ける。
- モダリティに依存しない、データ中心の data augmentation の分類法を提案する。
- 統一的な帰納的アプローチを用いて、5つのデータモダリティにまたがる augmentation 技術を分類する。
- 各モダリティ内の情報が augmentation にどう活用できるかを分析する。
- データ拡張手法とその理論的基盤の最新の総覧を提供する。
提案手法
- data augmentation を、ラベル付きデータセットを拡張データセットへ変換する関数 f_theta として形式化する。
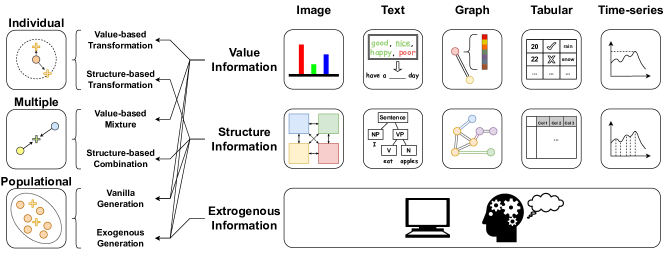
- 情報源に基づく二階層の分類法を導入する:Individual、Multiple、 and Populational Augmentation。
- さらに分類する:i) どの情報の部分が使用されるか(value-based vs structure-based)、ii) 新しいデータを生成するために使用されるサンプル数(sample-level、pairwise、population)。
- Populational augmentation における Vanilla(value/structure)対 Exogenous generation を区別する。
- この分類法を5つのモダリティに適用し、各モダリティの代表的な手法を review する。
- モダリティを横断したコアトレンドと最新の文献を要約する。
実験結果
リサーチクエスチョン
- RQ1RQ1: 各新しいサンプルを生成するために使用されるサンプル数はどれか(individual、multiple、populational)。
- RQ2RQ2: 新しいデータを生成するために使用される情報のどの部分か(value-based vs structure-based)。
- RQ3RQ3: モダリティに依存しない分類法が、異なるデータタイプ間の共通パターンをどう明らかにするか。
- RQ4RQ4: 画像、テキスト、グラフ、表形式データ、時系列データの最新の data augmentation 手法が、提案された分類法にどう適合するか。
主な発見
- 本論文は、5つのデータモダリティすべてに適用可能なモダリティに依存しない、データ中心の分類法を提供する。
- 3つの augmentation タイプ(individual、multiple、populational)と2つの情報源(value vs structure)を分類の対象として特定する。
- 画像、テキスト、グラフ、表形式データ、時系列モダリティにまたがる最新の data augmentation 文献を統合・分類する。
- 各モダリティ内の情報を、統一的な原則を通じて augmentation に活用する方法を強調する。
- 提案された枠組みの中で、automatic policy search や mixup-based strategies を含む最新の技術を調査・統合する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。