[論文レビュー] A Comprehensive Survey on Knowledge Distillation of Diffusion Models
拡散モデルの蒸留手法を調査し、拡散-to-場、拡散-to-生成器、トレーニング不要蒸留を分類。トレーニング不要のサンプリング洞察と複数の蒸留戦略を含む。
Diffusion Models (DMs), also referred to as score-based diffusion models, utilize neural networks to specify score functions. Unlike most other probabilistic models, DMs directly model the score functions, which makes them more flexible to parametrize and potentially highly expressive for probabilistic modeling. DMs can learn fine-grained knowledge, i.e., marginal score functions, of the underlying distribution. Therefore, a crucial research direction is to explore how to distill the knowledge of DMs and fully utilize their potential. Our objective is to provide a comprehensible overview of the modern approaches for distilling DMs, starting with an introduction to DMs and a discussion of the challenges involved in distilling them into neural vector fields. We also provide an overview of the existing works on distilling DMs into both stochastic and deterministic implicit generators. Finally, we review the accelerated diffusion sampling algorithms as a training-free method for distillation. Our tutorial is intended for individuals with a basic understanding of generative models who wish to apply DM's distillation or embark on a research project in this field.
研究の動機と目的
- 拡散モデルと、それらをニューラルベクタ場へ蒸留する際の課題を説明する。
- 確率的・決定論的暗黙生成器へ拡散モデルを蒸留した既存研究をレビューする。
- トレーニング不要蒸留手法として加速拡散サンプリングアルゴリズムを要約する。
- 蒸留手法をDiffusion-to-Field、Diffusion-to-Generator、Training-Freeのカテゴリに整理する。
提案手法
- 拡散モデルをスコアベースモデルとして導入し、ARMsとEBMsと対比する。
- Fisher発散とスコアマッチングをSBMのトレーニング目的として説明する。
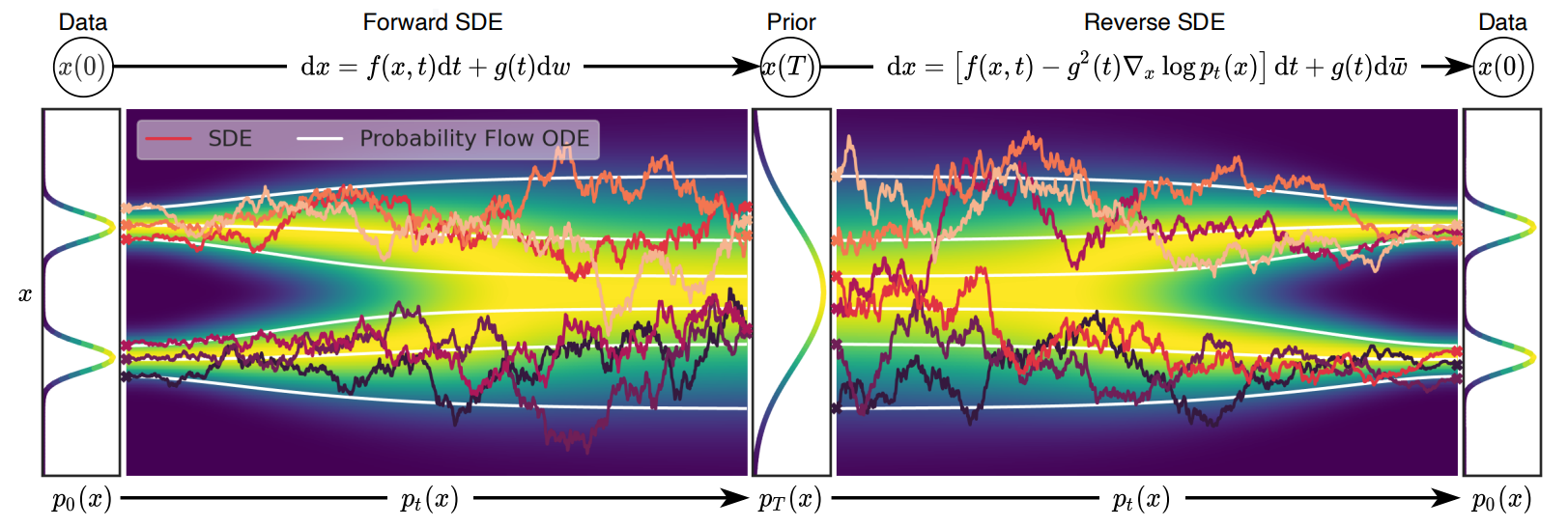
- 前方拡散SDE(VPとVE)とそのモジュラーカーネル、DDIM/ODEベースのサンプリングが蒸留を可能にする仕組みを説明する。
- 三つの蒸留カテゴリを要約する:D2F(出力蒸留と経路蒸留)、D2G、TF蒸留、それぞれの代表的手法と目的。
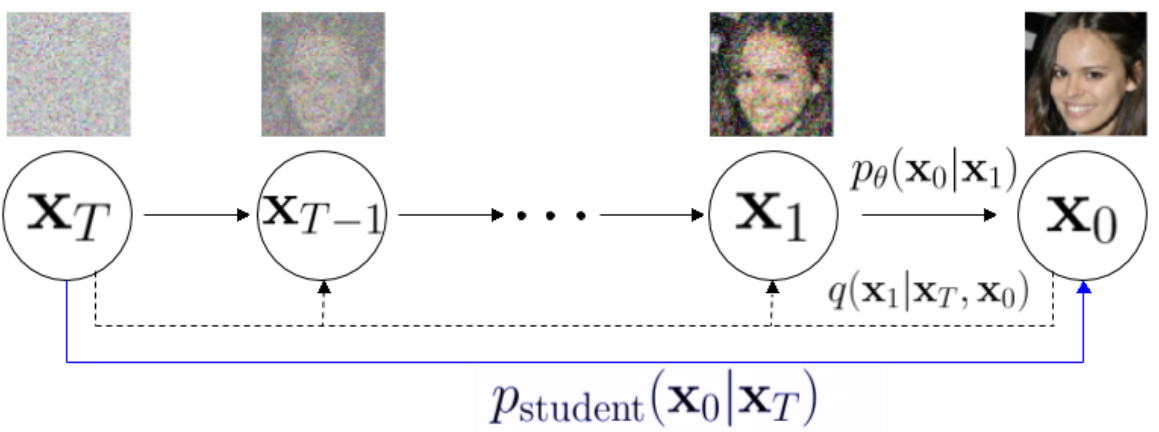
- 進行性蒸留(PD)と、それに関連する特徴/整合性ベースの蒸留手法とサンプリング効率の向上を示す。
実験結果
リサーチクエスチョン
- RQ1性能の大幅な低下を招かずに、低NFEsサンプラーへ拡散モデルを蒸留する効果的な戦略は何か。
- RQ2教師拡散モデルの知識を軽量な学生生成器やベクトル場へどう転用できるか。
- RQ3拡散サンプリングを加速するトレーニング不要またはほぼトレーニング不要のアプローチは何か。
- RQ4異なる蒸留パイプライン(D2F、D2G、TF)は、タスク間で効率と忠実度の面でどう比較されるか。
主な発見
- 出力蒸留により、教師ODE出力を大きなステップで模倣する学生を訓練でき、NFEsを大幅に減少させる(ケースにより1 NFEも可能)。
- 進行性蒸留は各ステージでNFEsを半分に減らすことができ、精度低下が小さな範囲(報告ケースで約5%のFID低下)で、4 NFEsにまで到達可能。
- 二段階蒸留は、分類器なしガイダンスを用いて条件付き拡散モデルを維持しつつサンプリングステップを減らすことを可能にする。
- 特徴空間蒸留(CFD)は、出力をピクセル空間の出力ではなくマルチステップの教師特徴と整合させ、効率を向上させる。
- 二段階蒸留アプローチはピクセル空間および潜在空間条件付き拡散へ適用され、NFEsが少なくてもFIDが競争力を持つ、または優れる場合がある。
- 自己一貫性蒸留(整合性モデル)は、生成ODEの数ステップを使用して経路レベルの整合性を強制する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。