[論文レビュー] A Cooperative Multi-Agent Reinforcement Learning Framework for Resource\n Balancing in Complex Logistics Network
本論文は、複雑な物流ネットワークにおける資源バランシングを確率的ゲームとして定式化し、従来の最適化手法より性能を改善する協調型マルチエージェント強化学習フレームワークを提案する。
Resource balancing within complex transportation networks is one of the most\nimportant problems in real logistics domain. Traditional solutions on these\nproblems leverage combinatorial optimization with demand and supply\nforecasting. However, the high complexity of transportation routes, severe\nuncertainty of future demand and supply, together with non-convex business\nconstraints make it extremely challenging in the traditional resource\nmanagement field. In this paper, we propose a novel sophisticated multi-agent\nreinforcement learning approach to address these challenges. In particular,\ninspired by the externalities especially the interactions among resource\nagents, we introduce an innovative cooperative mechanism for state and reward\ndesign resulting in more effective and efficient transportation. Extensive\nexperiments on a simulated ocean transportation service demonstrate that our\nnew approach can stimulate cooperation among agents and lead to much better\nperformance. Compared with traditional solutions based on combinatorial\noptimization, our approach can give rise to a significant improvement in terms\nof both performance and stability.\n
研究の動機と目的
- 複雑な物流ネットワークにおけるSnD(供給-需要)不均衡を動機づけ、従来のORアプローチが不確実性と非凸制約のために困難である点に対処する。
- ルート上の複数の相互作用資源エージェント(車両)として資源バランシングを確率的ゲームとして定式化する。
- 協調的なMARLフレームワークを設計し、相互エージェント協力を促進する状態設計と報酬設計。
- 海運における空コンテナ再配置タスクで有効性を実証し、予測不確実性に対する頑健性を示す。
提案手法
- エージェントとして車両を含む G=(N,A,S,R,P,γ) の確率的ゲームとして資源バランシング問題を定式化し、末端到着時のイベント駆動アクションを用いる。
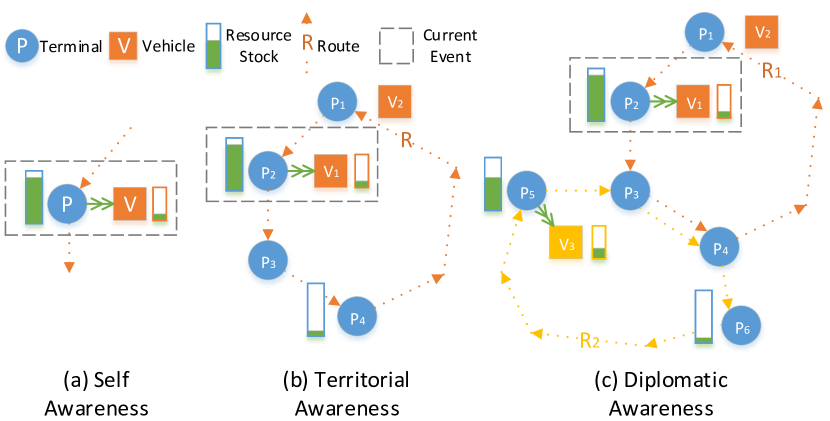
- 協調的なMARLフレームワークを導入し、協調指標を三段階(自己、領土、外交)として、協力を促進するよう状態表現と報酬を形成。
- 三段階の状態設計と、それに対応する遅延報酬を定義し、安全在庫とルート間および交差ルートでの協調を促す。
- エージェントが相互作用を通じて経験を収集し、リプレイメモリに蓄積し、MARL設定でQネットワークを更新するエンドツーエンド学習アルゴリズムを提案。
- フレームワークをシミュレートされた海洋物流ネットワークの空コンテナ再配置(ECR)タスクに適用し、ORベースのベースラインより改善を示す。
実験結果
リサーチクエスチョン
- RQ1協調的なMARLフレームワークは複雑な物流ネットワークにおける資源バランスの点で従来のORベース手法を上回ることができるか?
- RQ2異なる協調指標(自己、領土、外交)は状態設計、報酬、およびエージェント協力にどのような影響を与えるか?
- RQ3同じルート上の車両間で共有ポリシーを持つイベント駆動MARL設定は大規模ネットワークでのスケーラブルな学習を促進するか?
- RQ4海上物流における需要と供給予測の不確実性に対するこのアプローチはどれくらい頑健か?
- RQ5協調MARLを適用した場合のECRにおけるパフォーマンスはベースライン戦略と比べてどの程度影響を受けるか?
主な発見
- MARLフレームワークはシミュレーション海洋ネットワークでほぼ最適に資源バランスを達成する。
- 協調指標設計(自己、領土、外交)は状態と報酬の設計を導き、エージェント間の協力を強化する。
- 従来の組合せ最適化ベースラインと比較して、MARLアプローチは性能と安定性の点で著しい改善を提供する。
- 実験は海上物流における空コンテナ再配置に焦点を当て、SnD不確実性と非凸制約に対する頑健性を強調する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。