QUICK REVIEW
[論文レビュー] A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong|arXiv (Cornell University)|Oct 14, 2023
Advanced Text Analysis Techniques被引用数 41
ひとこと要約
TimesFM は、実データと合成データで事前学習されたデコーダー専用の時系列基盤モデルであり、未知データセットの分野横断でゼロショット予測のほぼ最先端を達成します。
ABSTRACT
Motivated by recent advances in large language models for Natural Language Processing (NLP), we design a time-series foundation model for forecasting whose out-of-the-box zero-shot performance on a variety of public datasets comes close to the accuracy of state-of-the-art supervised forecasting models for each individual dataset. Our model is based on pretraining a patched-decoder style attention model on a large time-series corpus, and can work well across different forecasting history lengths, prediction lengths and temporal granularities.
研究の動機と目的
- データセット固有の共変量を用いず、多様な時系列の一般的なゼロショット予測機を構築する動機付け。
- 入力パッチを用いた、文脈長とホライズン長の変化に適したデコーダースタイルのトランスフォーマーを設計する。
- 約1000億の時点に基づいて学習された200Mパラメータのモデルが、未知データに対して監視学習時と同等の精度に近づくことを示す。
- 異なるドメイン、粒度、ホライズンにわたるゼロショット性能を示す。
- アーキテクチャの選択と事前学習データの影響を正当化するアブレーションを提供する。
提案手法
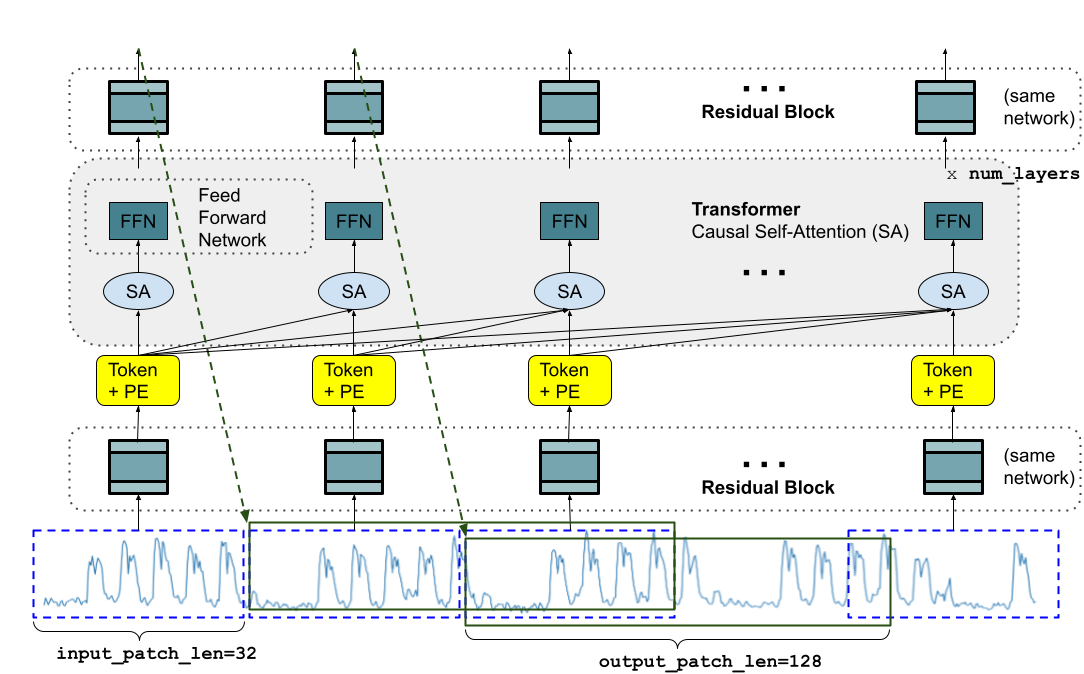
- 時系列をパッチに変換し、デコーダー専用トランスフォーマーに入力するパッチベースの入力処理。
- より長い出力パッチを用いて、自己回帰ステップを減らしつつ長いホライズンを予測する。
- 訓練中にパッチマスキングを適用し、1から最大コンテキスト長までの可変コンテキスト長を可能にする。
- 残差ブロックと因果的マルチヘッド自己注意を備えたデコーダー専用モデル(TimesFM)を訓練する。
- 実世界データ(Google Trends、Wiki Pageviews)と合成時系列の大規模混合コーパスで事前学習(約100Bのタイムポイント)。
- ポイント予測にはMSE損失で訓練し、将来の作業で確率的ヘッドの可能性を検討する。
実験結果
リサーチクエスチョン
- RQ1単一の事前学習済み時系列基盤モデルが、未知データセットの分野横断で強力なゼロショット予測を達成できるか。
- RQ2パッチ処理、デコーダー専用設計、パッチ長のトレードオフなど、どのようなアーキテクチャ上の選択が時系列予測における効果的なゼロショット一般化を可能にするか。
- RQ3データ源と事前学習スケールは、異なるホライズンや粒度にわたるゼロショット予測性能にどう影響するか。
- RQ4 Foundation-model 設定で長いホライズン予測に対して長い出力パッチデコーディングは有益か。
- RQ5パッチサイズとマスキング戦略が文脈長の頑健性と精度に与える影響は何か。
主な発見
- TimesFM は、 diverse な、これまで未知だったデータセットに対して、ゼロショット予測性能は最先端の監視学習モデルに近い。
- パラメータが200M、約100Bタイムポイントで事前学習されたモデルは、異なるホライズンと粒度で一般化できる。
- TimesFM は、ゼロショット設定で Monash、Darts、Informer のデータセットグループと競合可能。
- アブレーションにより、パラメータスケーリングが性能を向上させ、長い出力パッチは自己回帰ステップを減らし、長いホライズンでの精度を向上。
- 大規模で多様な事前学習データ(実データ + 合成データ)は、実データのみの事前学習と比較してゼロショット性能を大幅に向上させる。
![(a) Monash Archive [ 8 ]](https://ar5iv.labs.arxiv.org/html/2310.10688/assets/monash_mae_chart_200m.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。