[論文レビュー] A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music
本論文では MusicVAE を提案する。階層デコーダを用いることで音楽列の長期的構造を効果的にモデリングし、平坦なデコーダVAE よりも再構成、補間、属性操作を改善する。
The Variational Autoencoder (VAE) has proven to be an effective model for producing semantically meaningful latent representations for natural data. However, it has thus far seen limited application to sequential data, and, as we demonstrate, existing recurrent VAE models have difficulty modeling sequences with long-term structure. To address this issue, we propose the use of a hierarchical decoder, which first outputs embeddings for subsequences of the input and then uses these embeddings to generate each subsequence independently. This structure encourages the model to utilize its latent code, thereby avoiding the "posterior collapse" problem, which remains an issue for recurrent VAEs. We apply this architecture to modeling sequences of musical notes and find that it exhibits dramatically better sampling, interpolation, and reconstruction performance than a "flat" baseline model. An implementation of our "MusicVAE" is available online at http://g.co/magenta/musicvae-code.
研究の動機と目的
- VAEs が長い時系列データで苦労する理由とリカーネントの崩壊(posterior collapse)を説明する。
- 音楽の長距離構造を捉え latent 使用を促す階層デコーダを提案する。
- 平坦なデコーダよりも音楽列の再構成、補間、属性操作を改善することを示す。
- 音楽データにおけるマルチストリーム(複数楽器)モデリングの利点を示す。
- 方法論を大規模な MIDI データセットで定量的・定性的に評価し、アプローチを検証する。
提案手法
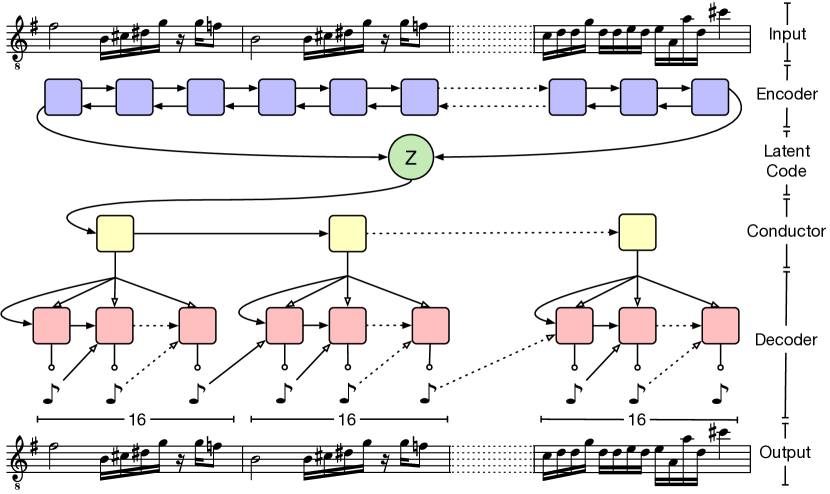
- 全体の列を単一の潜在ベクトル z に写像する双方向 LSTM エンコーダを使用する。
- 階層的デコーダを導入し、コンダクタ RNN が各サブ列の埋め込みを最初に出力し、それを各サブ列の下位レベルデコーダ RNN の初期化とする。
- 入力列を U 個の非重複サブ列にセグメント化し、長距離文脈がコンダクタ埋め込みを介して流れるようデコーダを制約する。
- 同じコンダクタ埋め込みにより駆動される別々の楽器デコーダを用いたマルチストリーム(トリオ)モデリングへ拡張する。
- 標準的な VAE 目的に、posterior collapse を抑制し長い列に対するスケジュールドサンプリングを活用する拡張を適用して訓練する。
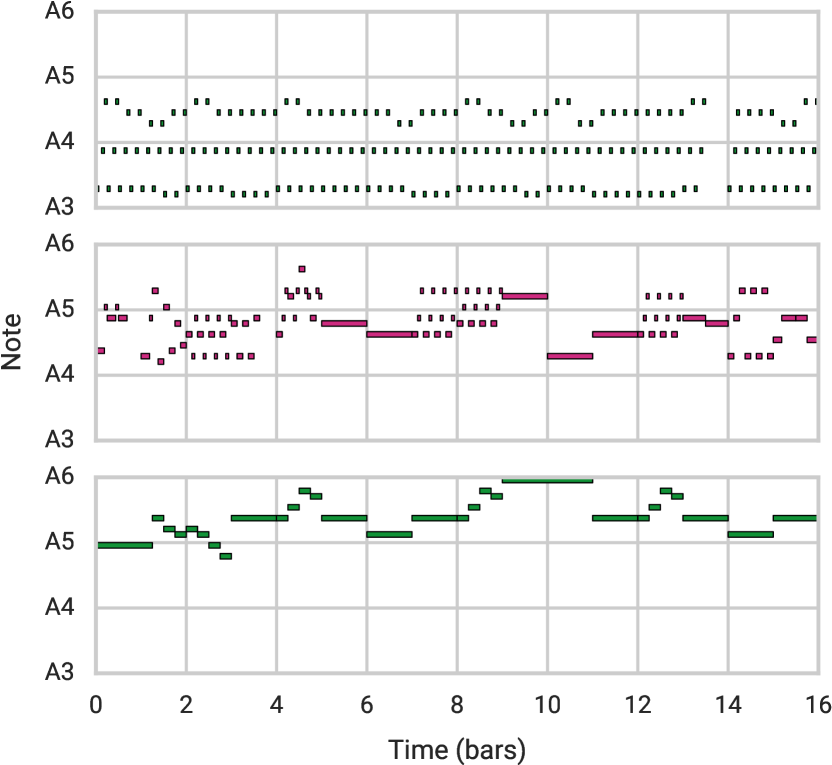
実験結果
リサーチクエスチョン
- RQ1階層型デコーダは posterior collapse を防ぎ、平坦なデコーダと比べて長い音楽列のモデリングを改善できるか。
- RQ2階層型 MusicVAE は、平坦なベースラインよりも長い列(16 小節以上)の再構成・補間・音楽的に一貫した生成を向上させるか。
- RQ3マルチストリームモデリング(メロディー、ベース、ドラム)は音楽列の構造学習にどのような利点をもたらすか。
- RQ4潜在空間の操作(補間・属性ベクトル)は、音楽データに対して意味があり、音楽的に一貫しているか。
主な発見
| モデル | フラット(教師強制) | 階層型(教師強制) | フラット(サンプリング) | 階層型(サンプリング) |
|---|---|---|---|---|
| 2-bar Drum | 0.979 | - | 0.917 | - |
| 2-bar Melody | 0.986 | - | 0.951 | - |
| 16-bar Melody | 0.883 | 0.919 | 0.620 | 0.812 |
| 16-bar Drum | 0.884 | 0.928 | 0.549 | 0.879 |
| Trio (Melody) | 0.796 | 0.848 | 0.579 | 0.753 |
| Trio (Bass) | 0.829 | 0.880 | 0.565 | 0.773 |
| Trio (Drums) | 0.903 | 0.912 | 0.641 | 0.863 |
- 階層型 MusicVAE は、平坦なデコーダに比べて長い列(16 小節のメロディー/ドラムパターンおよびマルチストリームデータ)で再構成精度を大幅に向上させる。
- 階層モデルによる潜在空間補間は、データ空間補間や平坦モデルよりもメロディー間の移行を滑らかで一貫性のあるものにする。
- 潜在空間の属性ベクトル演算は、密度やシンクポーションなどの意味的な音楽的変化を、例ごとに制御可能な操作としてもたらす。
- リスニング研究では、階層モデルのサンプルが平坦な基準と比べてメロディー、トリオ、ドラムのタスク全般でより音楽的と評価される。
- 教師付き再構成とサンプリング再構成のギャップを縮小し、潜在コードのより良い利用と露出バイアスの緩和を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。